End-To-End Memory Networks
2016-10-12 10:22
519 查看
关键词
End2End, Memory Networks, Multiple hops来源
arXiv 2015.03.31 (published at NIPS 2015)问题
当前 AI 研究面临两大问题:如何在回答问题时实现多个计算步骤
如何描述序列数据的长距离依赖性
本文尝试从 Memory Networks 入手,解决这两个问题。
文章思路
模型介绍 在单层模型中模型将 document 中的每一个 word 保存为一个 memory mi,每个memory 本质上就是一个向量,这一点与 embedding 是一回事,只是换了一个名词。另外每个 word 还与一个输出向量 ci 相关联。可以理解为每个 word 表示为两组不同的 embedding A 和 C。同样的道理,query 中的每个单词可以用一个向量来表示,即对应着另一个 embedding B。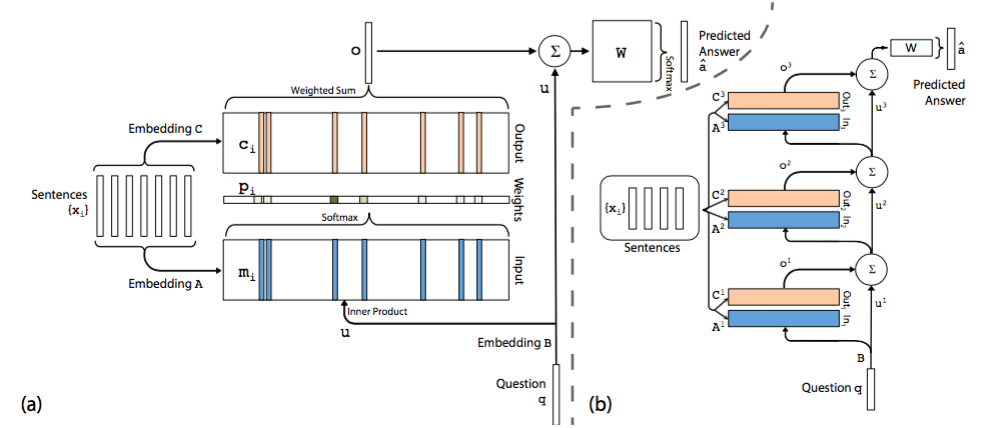
在 Input memory 表示层,用 query 向量与 document 中每个单词的 mi 作内积,再用 softmax 归一化得到一组权重,这组权重就是 attention,即 query 与 document 中每个 word 的相关度。
接下来,将权重与 document 中的另一组 embedding ci 作加权平均得到 Output memory 的表示。这一步也称作 support memory。
最后,利用 query 的表示和 output memory 的表示去预测answer。
根据单层模型的结构,非常容易构造出多层模型。每一层的 query 表示等于上一层 query 表示与上一层输出 memory 表示的和 (还有很多其他结合方式)。每一层中的 A 和 C embedding 有两种模式:
第一种是邻接,即 Ak+1=Ck,依次递推
第二种是类似于 RNN 中共享权重的模式,A1=A2=…=Ak,C1=C2=…=Ck。其他的过程均和单层模型无异。
模型细节 论文中一般采用 3 跳网络邻接模式,其中
句子 memory 表示有两种方式
一种是 bag of words 表示出的向量与 embedding 矩阵 A 相乘得到 memory,即mi=ΣjAxij其中 i 表示第 i 个句子,j 表示第 j 个词。
另一种是在它们做 element-wise 乘法时,前面乘上一个系数。mi=Σjlj⋅Axij这个系数 lj 叫做 Position Encoding,它是一个列向量,用如下公式计算lkj=(1−j/J)−(k/d)(1−2j/J)其中 J 表示句子中词汇数量,d 表示 embedding 维度。
很多 QA 任务对上下文有要求,本文采用 Temporal Encoding。为了解决这个问题,用如下公式解决mi=ΣjAxij+TA(i) 其中 TA(i) 表示第 i 行。ci 也同样用 TC(i) 加强。
在正则化 TA 时,引入随机噪音效果会比较好。文中在训练时对于 document 额外添加 10% 空的 memory。
资源
论文地址:https://arxiv.org/abs/1503.08895v5代码地址:https://github.com/facebook/MemNN
相关工作
文中数据集采用 Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks 中 version1.1 版本的数据集。数据集是这样的:给定一段陈述句以及一个对应的问题,这个问题通常是一个单词 (偶尔会是多个)。数据集包含 20 种不同推理推断能力,下面是一个数据样例

注意到对于每个问题,只有部分陈述句包含了答案所需信息,其他的都是干扰。
简评
一般的 Memory Networks 在每一层都需要监督,因而不易训练。但是本文是连续版的 Memory Networks,因此可以 end2end 训练。
相关文章推荐
- 记忆网络之Gated End-To-End Memory Networks
- End-To-End Memory Networks 论文翻译
- End-To-End Memory Networks
- 论文:记忆网络之Gated End-to-End Memory Networks
- End-To-End Memory Networks 论文阅读
- 论文阅读:End-To-End Memory Networks
- 读论文end-to-end Memory Networks
- 记忆网络之End-To-End Memory Networks
- End-To-End Memory Networks
- 释放内存free()错误:CRT detected that the application wrote to memory after end of heap buffer:内存访问违规
- CRT detected that the application wrote to memory after end of heap buffer.
- 车牌检测识别--Towards End-to-End Car License Plates Detection and Recognition with Deep Neural Networks
- CRT detected that the application wrote to memory after end of heap buffer
- 一个关于LSTM的high-level介绍(但是很好):A Gentle Introduction to Long Short-Term Memory Networks by the Experts
- CRT detected that the application wrote to memory after end of heap buffer
- End to End Memory network
- 内存错误:CRT detected that the application wrote to memory after end of heap buffer
- How to Use the TimeDistributed Layer for Long Short-Term Memory Networks in Python 译文
- CRT detected that the application wrote to memory after end of heap buffer
- 论文阅读:End-to-End Learning of Deformable Mixture of Parts and Deep Convolutional Neural Networks for H