为什么机器学习真的可以学到东西?
2016-10-08 12:20
399 查看
前言
开始跟《机器学习基石》这门课,相对于Stanford那门课,这门明显难度大很多,我跟到第10个
Lecture,才刚刚讲到
Logistic Regression。前面费了很大力气在讲机器什么时候可以学习,以及证明为什么能学习。
此文主要是基于《机器学习基石》的学习笔记。
Topic是为什么机器可以学习?
机器学习流程
下面是一个粗略的机器学习流程图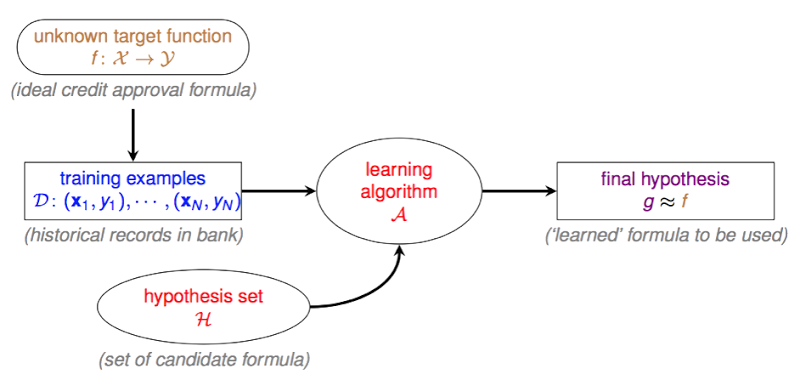
机器学习最开始也是最终的目的是获得一个
target function,喂进去数据能直接得到正确结论的函数。为了得到这个函数,我们需要一大堆的训练数据。然后通过一个好的机器学习算法,从一大堆
可能的function(也就是H)中挑选一个
比较好的function(也就是g),这个
g和
target function长得越像越好。
Hoeffding’s
inequality
大家有没有想过,为什么这样就能学到东西。我们的算法只是在训练数据上跑,从训练数据跑出来的g,我们怎么能确定它也能在测试数据上跑的很好呢?这个就是问题的关键。其实接下来内容主要就是论证这个问题。
先来考虑一个简单的问题。比如说我们现在有一个黑罐子,里面有很多弹珠,只有两种颜色,黄的和绿的。好现在问你,你怎么能知道黄色弹珠大概有多少颗?
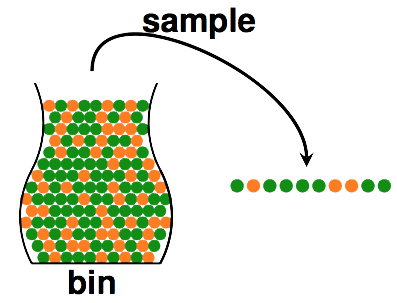
大家肯定都会说抽样。没错,我们抽出10个弹珠,很容易能知道黄色弹珠在
sample中的比例。但是这个比例真的能代表罐子中的比例吗?也许能,也许不能。而且能的记录会随着我们
sample数目的增大而增大。但是也有可能你抓出一把全绿。但这种情况发生的记录很小。这里我们有一个定理保证这种偏差发生的记录很小。
Hoeffding's inequality可以保证偏差很大发生的几率很小,并且随着
N的增大很减小。公式如下,
v代表
sample中黄色弹珠的比例,
μ表示罐子中黄色弹珠的比例。
ϵ也就是偏差。
ℙ[|ν−μ|>ϵ]≤2exp(−2(ϵ^2)N)
坏事的发生
现在我们称v为
Ein,
μ为
Eout,现在我们已经证明了
Ein和
Eout不会差的太远,更重要的事情是保重
Ein越小越好,这就需要一个好的算法。
还记得上面的学习流程吗,我们的算法是从很多个
h中去挑选一个
Ein最小的
h让它成为
g。但是这里会有坏事情发生。
所谓的坏事情就是
bad sample,就是说我们抽出了十个全是绿的弹珠。现在有一个好的
h称之为
h1,和坏的
h叫
h2,
h1对于这个
bad sample的表现当然是糟糕的,而恰好
h2表现很好,那
h2就被选成
g了。
当出现坏事的时候,我们学习就会困难,可以直接说不能学习。所以这个坏事出现的概率是多少呢?把所有h中发生坏事的几率加起来。

从上图的式子中可以看到,坏事发生的几率和
M有关。
M也就是
h的个数。
从现在的条件来看,如果
M很大甚至无线的话那么
Learning是不可行的。
无效的Hypothesis
真实的情况是M一般不会很大,请再仔细看看上一张图的推导,
M是通过把所有的
h坏事发生的概率加起来的,但是其实这些
h不是互相独立的。所以这些
h是有重复的,如下图。
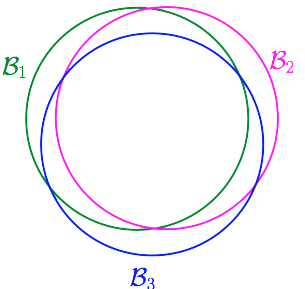
比如说,我们想学习的
target function是一条把
x1分类成正负的线。现在
h就有无数个,因为任意一条线都能分类,但是实际有意义的只有两种,分成正的和负的。
如果是两个点的话,实际有效的
h就有4种,但是3个点就有可能不到8种了,因为会出现三点共线的情况。4个点的话按理说有16种,但是同样有一种情况不会发生,请看下图。

所以现在我们的公式就变成了这样,大大减小
M的个数

成长函数的上限
现在我们给上面effective(N)一个称呼,叫做成长函数。也就是说,对于某一个输入
D,
H最多能够产生的多少种方程。注意是种类的数量。
这个所谓的种类我们也给一个定义叫做
dichotomy,用来表示
H对与
D的二元分类情况。
好,现在问题的关键,就是
H到底能把
D分成多少个
dichotomy。也就是它的成长函数到底是多少?
但是我们很难确定它的成长函数。但是好在我们拥有一个叫做
break point的东西,这就是成长函数的上限。我们再看回上面分类的例子。
一个点能分成两种
两个点分成四种
三个点分成六种或者八种
四个点只有14种(
break point)
这里的输入为三个点就是一个
break point。也就是说当输入N个点,
H不能够把这个
N个点的排列组合全部表示出来时
(2^N),
N就是一个
break point。
当
H能把
N的全部组合表示出来时,说明这
N个点被
H给
shatter掉了
我们用
B(N,k)来表示当输入
N个点时,
H可以最多产生多少个
dichotomy。
通过数学归纳法我们可以证明到

VC
BOUND
现在到了最后一步,除了把上边那个成长函数的上限代入进去之外,还需要进行一系列的变形,这些变形需要很强的数学能力和概率上面的知识,我自己都不太懂,况且我觉得大部分人都不需要了解。这里我就略过,有兴趣的强人自己最终的式子如下

好了,现在我们终于能说机器学习确实可以学到东西了。但是需要满足三个条件。
有一个好的
H(拥有
break point)
足够多的数据
好的算法,能够使
Ein足够小
这三者的关系如下图。

dvc = k - 1,大致上可以把它看出
theta的维度加1
上图很清晰的说明,并不是说你的模型搞得很复杂,算法弄得很好,就能学好,反而是取到一个折中的点,这样的学习才最有效。
#Machine
Learning

相关文章推荐
- 为什么数据库可以连接上,却写不进数据库东西啊
- 机器学习基石笔记5——为什么机器可以学习 (1)
- 从Google身上可以学到的14个东西
- 机器学习基石笔记7——为什么机器可以学习(3)
- 年轻的采访可以学到很多东西
- 机器学习基石笔记7——为什么机器可以学习(3)
- 机器学习基石笔记8——为什么机器可以学习(4)
- 从Google身上可以学到的14个东西 转帖
- 从Google身上可以学到的14个东西
- 从Google身上可以学到的14个东西
- 机器学习基石笔记8——为什么机器可以学习(4)
- 从Google身上可以学到的14个东西
- 有用的oracle的SQL语句,可以学到很多东西
- 为什么export-->runnable jar file的launch configuration没有东西可以选择?
- 机器学习基石笔记5——为什么机器可以学习(1)
- 【机器学习基础】理解为什么机器可以学习3——VC理论
- 机器学习基石笔记6——为什么机器可以学习(2)
- 希望可以学到东西.
- 【机器学习基础】理解为什么机器可以学习1——PAC学习模型
- 【机器学习基础】理解为什么机器可以学习——Hoeffding不等式