scikit-learn一般实例之八:多标签分类
2016-10-05 19:30
417 查看
本例模拟一个多标签文档分类问题.数据集基于下面的处理随机生成:
选取标签的数目:泊松(n~Poisson,n_labels)
n次,选取类别C:多项式(c~Multinomial,theta)
选取文档长度:泊松(k~Poisson,length)
k次,选取一个单词:多项式(w~Multinomial,theta_c)
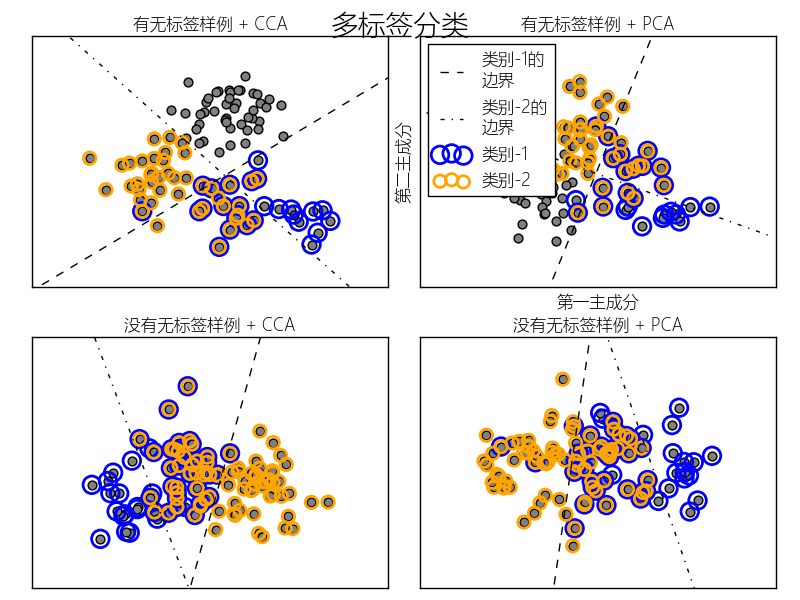
在上面的处理中,拒绝抽样用来确保n大于2,文档长度不为0.同样,我们拒绝已经被选取的类别.被同事分配给两个分类的文档会被两个圆环包围.
通过投影到由PCA和CCA选取进行可视化的前两个主成分进行分类.接着通过元分类器使用两个线性核的SVC来为每个分类学习一个判别模型.注意,PCA用于无监督降维,CCA用于有监督.
注:在下面的绘制中,"无标签样例"不是说我们不知道标签(就像半监督学习中的那样),而是这些样例根本没有标签~~~
选取标签的数目:泊松(n~Poisson,n_labels)
n次,选取类别C:多项式(c~Multinomial,theta)
选取文档长度:泊松(k~Poisson,length)
k次,选取一个单词:多项式(w~Multinomial,theta_c)
在上面的处理中,拒绝抽样用来确保n大于2,文档长度不为0.同样,我们拒绝已经被选取的类别.被同事分配给两个分类的文档会被两个圆环包围.
通过投影到由PCA和CCA选取进行可视化的前两个主成分进行分类.接着通过元分类器使用两个线性核的SVC来为每个分类学习一个判别模型.注意,PCA用于无监督降维,CCA用于有监督.
注:在下面的绘制中,"无标签样例"不是说我们不知道标签(就像半监督学习中的那样),而是这些样例根本没有标签~~~
# coding:utf-8 import numpy as np from pylab import * from sklearn.datasets import make_multilabel_classification from sklearn.multiclass import OneVsRestClassifier from sklearn.svm import SVC from sklearn.preprocessing import LabelBinarizer from sklearn.decomposition import PCA from sklearn.cross_decomposition import CCA myfont = matplotlib.font_manager.FontProperties(fname="Microsoft-Yahei-UI-Light.ttc") mpl.rcParams['axes.unicode_minus'] = False def plot_hyperplane(clf, min_x, max_x, linestyle, label): # 获得分割超平面 w = clf.coef_[0] a = -w[0] / w[1] xx = np.linspace(min_x - 5, max_x + 5) # 确保线足够长 yy = a * xx - (clf.intercept_[0]) / w[1] plt.plot(xx, yy, linestyle, label=label) def plot_subfigure(X, Y, subplot, title, transform): if transform == "pca": X = PCA(n_components=2).fit_transform(X) elif transform == "cca": X = CCA(n_components=2).fit(X, Y).transform(X) else: raise ValueError min_x = np.min(X[:, 0]) max_x = np.max(X[:, 0]) min_y = np.min(X[:, 1]) max_y = np.max(X[:, 1]) classif = OneVsRestClassifier(SVC(kernel='linear')) classif.fit(X, Y) plt.subplot(2, 2, subplot) plt.title(title,fontproperties=myfont) zero_class = np.where(Y[:, 0]) one_class = np.where(Y[:, 1]) plt.scatter(X[:, 0], X[:, 1], s=40, c='gray') plt.scatter(X[zero_class, 0], X[zero_class, 1], s=160, edgecolors='b', facecolors='none', linewidths=2, label=u'类别-1') plt.scatter(X[one_class, 0], X[one_class, 1], s=80, edgecolors='orange', facecolors='none', linewidths=2, label=u'类别-2') plot_hyperplane(classif.estimators_[0], min_x, max_x, 'k--', u'类别-1的\n边界') plot_hyperplane(classif.estimators_[1], min_x, max_x, 'k-.', u'类别-2的\n边界') plt.xticks(()) plt.yticks(()) plt.xlim(min_x - .5 * max_x, max_x + .5 * max_x) plt.ylim(min_y - .5 * max_y, max_y + .5 * max_y) if subplot == 2: plt.xlabel(u'第一主成分',fontproperties=myfont) plt.ylabel(u'第二主成分',fontproperties=myfont) plt.legend(loc="upper left",prop=myfont) plt.figure(figsize=(8, 6)) X, Y = make_multilabel_classification(n_classes=2, n_labels=1, allow_unlabeled=True, random_state=1) plot_subfigure(X, Y, 1, u"有无标签样例 + CCA", "cca") plot_subfigure(X, Y, 2, u"有无标签样例 + PCA", "pca") X, Y = make_multilabel_classification(n_classes=2, n_labels=1, allow_unlabeled=False, random_state=1) plot_subfigure(X, Y, 3, u"没有无标签样例 + CCA", "cca") plot_subfigure(X, Y, 4, u"没有无标签样例 + PCA", "pca") plt.subplots_adjust(.04, .02, .97, .94, .09, .2) plt.suptitle(u"多标签分类", size=20,fontproperties=myfont) plt.show()

相关文章推荐
- [占位-未完成]scikit-learn一般实例之十:核岭回归和SVR的比较
- 机器学习 - 基于 Scikit-learn 多类别和多标签分类算法
- scikit-learn一般实例之一:保序回归(Isotonic Regression)
- scikit-learn一般实例之一:绘制交叉验证预测
- [占位-未完成]scikit-learn一般实例之十一:异构数据源的特征联合
- scikit-learn一般实例之六:构建评估器之前进行缺失值填充
- scikit-learn一般实例之四:管道的使用:链接一个主成分分析和Logistic回归
- 【scikit-learn】【RandomForest】【GridSearchCV】二分类应用实例及【ROC】曲线绘制
- [未完成]scikit-learn一般实例之九:用于随机投影嵌入的Johnson–Lindenstrauss lemma边界
- scikit-learn分类问题入门实例(1)
- scikit-learn一般实例之四:使用管道和GridSearchCV选择降维
- scikit-learn一般实例之七:使用多输出评估器进行人脸完成
- 使用 scikit-learn 实现多类别及多标签分类算法
- scikit-learn一般实例之三:连接多个特征提取方法
- [占位-未完成]scikit-learn一般实例之十二:用于RBF核的显式特征映射逼近
- 【scikit-learn】Python分类实例
- 30分钟学会用scikit-learn的基本分类方法(决策树、SVM、KNN)和集成方法(随机森林,Adaboost和GBRT)
- Scikit Learn RandomForestRegressor 入门实例
- Scikit-learn:scikit-learn快速教程及实例
- Scikit Learn CountVectorizer 入门实例