第二次结对编程作业——毕业导师智能匹配
2016-09-29 21:58
495 查看
第二次结对编程作业——毕业导师智能匹配
结对编程人员031402418汪培侨
031402618林宇晨
一、问题描述
编码实现一个毕设导师的智能匹配的程序。提供输入包括:30个老师(包含带学生数的要求的上限,单个数值,在[0,8]内),100个学生(包含绩点信息),每个学生有5个导师志愿(志愿的导师可以重复但不能空缺)。实现一个智能自动分配算法,根据输入信息,输出导师和学生间的匹配信息(一个学生只能有一个确认导师,一个导师可以带少于等于其要求的学生数的学生)
及 未被分配到学生的导师 和 未被导师选中的学生。
二、问题分析
经过商讨后得出以下问题:
数据输入要采用数据库还是txt?
同学的中选要以绩点为优先、对某个老师的喜爱程度优先~~?
同学的志愿里面里面如果填了多个同样的老师又该如何分配?
到底要用什么语言?
填了多个老师意味着他非常喜欢这个老师?
随机生成的数据,是不是不太符合我们现实的情况?
算法的目标没中选的学生人数越少越好?
5个志愿到底是平行志愿,还是有先后顺序?
经过一番系列性的讨论,以及两次攥写的经过,可以得出我们小组的答案
编程语言:C/C++
数据输入输出:采用文本TXT的形式
随机生成数据:对随机生成数据的概率进行了一定的约束,模拟较为现实的环境
志愿顺序的关系:和志愿的排序有一定的关系,每一个次序所占权重不同,但相差不会太大
分配规则:对学生的绩点,以及对某某老师的喜爱程度(多志愿选择同一老师)进行一定权重的积,绩点所占比重会大一点
算法目标:让更多的选手选到自己志愿里面的老师,权重高的中选的自己喜欢的老师的机会大
接下来将我们实现的算法进行解释说明。
三、算法的实现策略
1、数据的生成
为了更好的贴切现实生活中,学生选择老师的情况,我们对随机的生成数据进行了一定的约束,以便于后续的模拟。教师大体可以分为这三类:
热门老师
普通老师
冷门老师
我们的模拟数据生成器中,就选择了6个热门老师,14个普通热门老师,10个普通老师
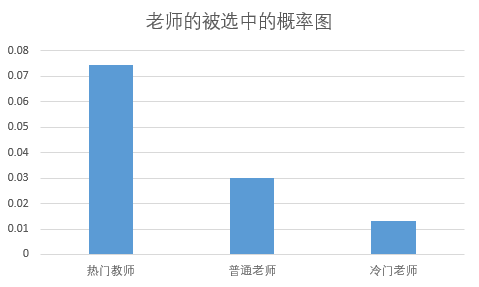
以上为对应单个老师的被学生选中的概率分析图。
我们将学生选择志愿的老师的程度用上图描述。
教师数据生成
for(i=0;i<m;i++) //教师工号的生成,按tea0-29 ,以及对应的要选择学生的人数
{
if(i>=0 && i <=9) fprintf(fpWrite,"tea00%d\n", i);
else if(i>9) fprintf(fpWrite,"tea0%d\n", i);
fprintf(fpWrite,"%d\n",rand()%8+1);
}学生数据生成
for(j=0;j<n;j++) //学生学号,基点,五个志愿对应老师的选择
{
if(j==0) fprintf(fpWrite,"stu000\n"); //学号
else if(j>0&&j<=9) fprintf(fpWrite,"stu00%d\n",j);
else if(j>9) fprintf(fpWrite,"stu0%d\n",j);
double jidian;
jidian = ( rand()%101 ) /25.0 + 1;
fprintf(fpWrite,"%.1lf\n",jidian); //绩点
/*模拟对应志愿的选择,每个志愿的对应的老师的概率不同*/
for (i=0; i<5; i++)
{
number = rand() % 150;
if(number<60) number=number%30;
else if(number>=60&&number<100)
{
number=(number-59)%6;
}
else if(number>=100)
{
number=(number-99)%20;
}
if(number>=0 && number <=9) fprintf(fpWrite,"tea00%d\n", number);
else if(number>9) fprintf(fpWrite,"tea0%d\n", number);
}
}实现代码可参见
2、权重的计算
绩点权重
基点权重的计算:分为4个阶级用以下图表示
上图为各个阶级段的绩点所占权重,该值为多次实验反复修改后得到的值,
设分权重为Q1,则
$$
Q1=绩点*上述对应的绩点权重
$$
对应代码
int jdqz(double jidian)//计算绩点权重
{
int qz;
if(jidian<2 && jidian>=1) qz=100;
else if(jidian<3 && jidian>=2) qz=120;
else if(jidian<4 && jidian>=3) qz=130;
else if(jidian<=5 && jidian>=4) qz=140;
return (int)qz*jidian;
};教师权重
教师权重表示的是XX学生的XX老师的喜爱程度每一个志愿的老师对应权重
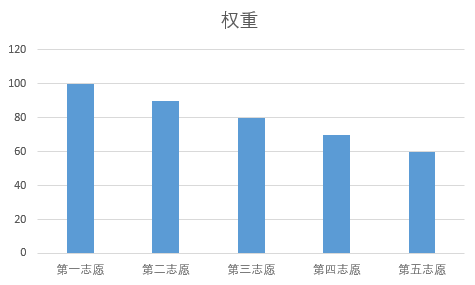
如果选择多个志愿选择同样的老师,那就以第一个志愿的权重为基准,加上后续选择的同样老师的志愿权重/5,此番设计也是通过多次实验,反复修改得到
设分权重(学生对XX老师)为Q2
$$
Q2=第一个出现该老师的权重+后续出现老师的权重/5
$$
总权重
设总权重为Q(stuxx,teaxx),以及上述的绩点权重Q1,教师权重Q2,可以得到某某学生对某某老师的总权重:$$
Q(stuxx,teaxx)=Q1*Q2
$$
后续将会以这个权重Q会平衡点以及老师所需要的学生人数为基准去实现分配
3、学生分配
第一次算法模拟:
流程图如下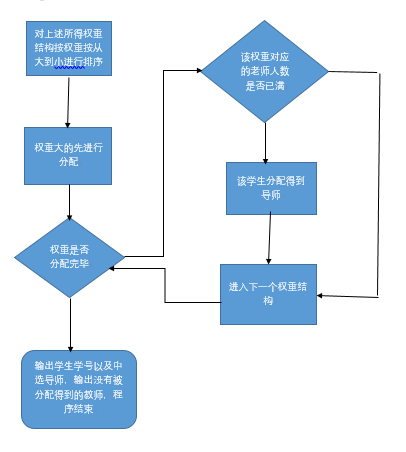
总结上述算法在实验中遇到的问题:
在模拟一般选志愿的时候还比较OK,就是选中30个老师,每个老师的概率都是一样的,后面换了测试数据后,发现这个算法会导致还有10多个学生没有中选老师,显然这是不可接受的。于是我们又找了第二个算法进行了尝试。
第二次算法模拟
在请教了同学之后,得到了一个偶然的算法,最小费用最大流(MCMF)算法!!!下面介绍该算法
算法介绍:
在一个网络中每段路径都有“容量”和“费用”两个限制的条件下,此类问题的研究试图寻找出:流量从A到B,如何选择路径、分配经过路径的流量,可以达到所用的费用最小的要求。如n辆卡车要运送物品,从A地到B地。由于每条路段都有不同的路费要缴纳,每条路能容纳的车的数量有限制,最小费用最大流问题指如何分配卡车的出发路径可以达到费用最低,物品又能全部送到。
类比一下我们的题目:
容量就相当于每一个学生只能选择一个老师,每一个老师收的学生都有上限一样,费用可以看成是学生对老师权重的大小,我们这里要权重最大的那个,因此要把权重做一定的处理,把大的权重通过一定的映射转化成题目所需的小权重。
如图所示:

这里的起点终点,与卡车题中的起点和终点一样,学生点和老师点就相当于走过的路径,最终就是为了,优先实现最大流基本上的路径都能经过(尽量让每个学生都能选上老师),然后在让费用最小(通过映射即让权重大的尽量走过)
模拟效果也比我们第一个算法有了很大的进步。
代码如下:
struct MCMF//最小费用最大流
{
int n,m,s,t;
vector<Edge> edges;
vector<int> G
;
int inq
,d
,p
,a
;
void init(int n)//初始化
{
this->n=n;
for(int i=0; i<n; i++) G[i].clear();
edges.clear();
}
void addedge(int from,int to,int cap,int cost)//连边
{
edges.push_back(Edge(from,to,cap,0,cost));
edges.push_back(Edge(to,from,0,0,-cost));
int m=edges.size();
G[from].push_back(m-2);
G[to].push_back(m-1);
}
bool SPFA(int s,int t,int &flow,int &cost)//求最短增广路
{
for(int i=0;i<n;i++) d[i]=INF;
memset(inq,0,sizeof(inq));
d[s]=0;inq[s]=1;p[s]=0;a[s]=INF;
queue<int> Q;
Q.push(s);
while(!Q.empty())
{
int u=Q.front();
Q.pop(); inq[u]--;
for(int i=0;i<G[u].size();i++)
{
Edge& e=edges[G[u][i]];
if(e.cap>e.flow && d[e.to]>d[u]+e.cost)
{
d[e.to]=d[u]+e.cost;
p[e.to]=G[u][i];
a[e.to]=min(a[u],e.cap-e.flow);
if(!inq[e.to])
{
inq[e.to]++;
Q.push(e.to);
}
}
}
}
if(d[t]==INF) return false;
flow+=a[t];
cost+=d[t]*a[t];
int u=t;
while(u!=s){
edges[p[u]].flow+=a[t];
edges[p[u]^1].flow-=a[t];
u=edges[p[u]].from;
}
return true;
}
int run(int s,int t)//运行
{
int flow=0,cost=0;
while(SPFA(s,t,flow,cost));
return cost;
}
void PrintPlan(int l,int r)//输出方案
{
int Plan
;
memset(Plan,0,sizeof(Plan));
for(int i=0; i<edges.size(); ++i)
if(edges[i].cap==edges[i].flow&&edges[i].cap&&edges[i].from>=l&&edges[i].from<=r)
Plan[edges[i].from]=edges[i].to-r;
for(int i=l; i<=r; ++i)
if(Plan[i])
printf("学生学号 %s 所分配教师工号 %s\n",Sname[i],Tname[Plan[i]]);
for(int i=l; i<=r; ++i)
if(!Plan[i])
printf("学生学号 %s 未分配老师\n",Sname[i]);
}
};四、结对感受
031402418汪培侨:
我觉得把结对,最重要的就是能让你写代码的时候更专注,而且互相分析问题会更加的全面,毕竟两个脑子,互相补充。这次的作业相比上一次应该是要难很多,但期间的收获还是蛮大的,比如第一次的算法就因为处理数据不够强,就被我们淘汰了,最终还是找到了一个MCMF算法,多亏同学帮忙。这次我要给我的队友满分,在我还在纠结要不要换算法增加工作量时,最终还是选择了换算法。继续加油。
031402618林宇晨
觉得这次结对的任务量比上次小了一些,但是觉得交流上的难度变大了,在讨论算法的时候两个人发生了较大的分歧,两人沟通不好,没有很好的表达出自己的意思,结果导致第一次采用的方法在引入6个导师后出现了较大问题,后来连夜修改了算法,用我的话说就是“命都没了半条”。关于git的使用方面,因为采用的是结对编程的方式,使用较少。最后总结下这次的作业,个人认为最突出的问题有两个,第一是交流较失败导致进度被拖下,第二点是设计算法的时候烤炉的不够周全导致实现的时候出现了种种问题。
闪光点:
1、能够根据实际的情况去模拟数据的生成 2、大砍一刀换算法的勇气
建议分享:
讲道理,上面大砍一刀的情况其实我们并不想看到,所以我觉得在做这个之前,还是去浏览一些相关的论文,以便于增多自己的可选择的方法,让自己的肚子更有墨水。
五、Coding.net上的代码
详情请戳这里,请看里面的READMEhttps://coding.net/u/peiqiaoWang/p/work_num2/git

相关文章推荐
- 第二次结对编程作业——毕业导师智能匹配
- 第二次结对编程作业——毕业导师智能匹配
- 第二次结对编程作业——毕业导师智能匹配
- 第二次结对编程作业——毕业导师智能匹配
- 第二次结对编程作业——毕业导师智能匹配
- 第二次结对编程作业——毕设导师智能匹配
- 随笔0005 第二次结对编程作业——毕设导师智能匹配
- 第二次结对编程作业——毕设导师智能匹配
- 第二次结对编程作业——毕设导师智能匹配
- 第二次结对编程作业—毕设导师智能匹配
- 第二次结对编程作业——毕设导师智能匹配
- 第二次结对编程作业——毕设导师智能匹配
- 第二次结对编程作业——毕设导师智能匹配
- 第二次结对编程作业——毕设导师智能匹配
- 第二次结对编程作业——毕设导师智能匹配
- 第二次结对编程作业——毕设导师智能匹配
- 第二次结对编程作业-毕设导师智能匹配
- 第二次结对编程作业——毕设导师智能匹配
- 第二次结对编程作业——毕设导师智能匹配
- 第二次结对编程作业——毕设导师智能匹配