python 爬虫基础笔记(一)
2016-09-29 10:38
525 查看
笔记记录来自慕课网(IMOOC):http://www.imooc.com/video/10683
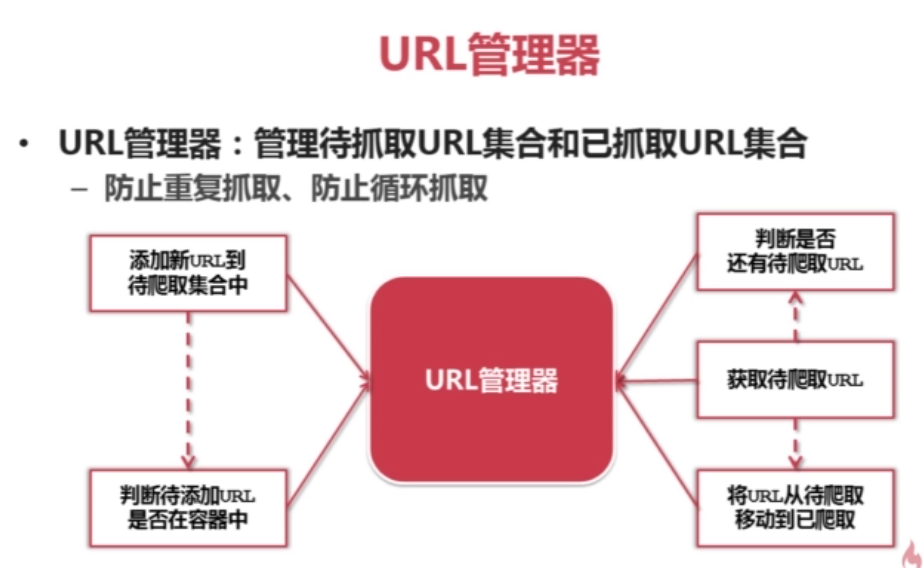
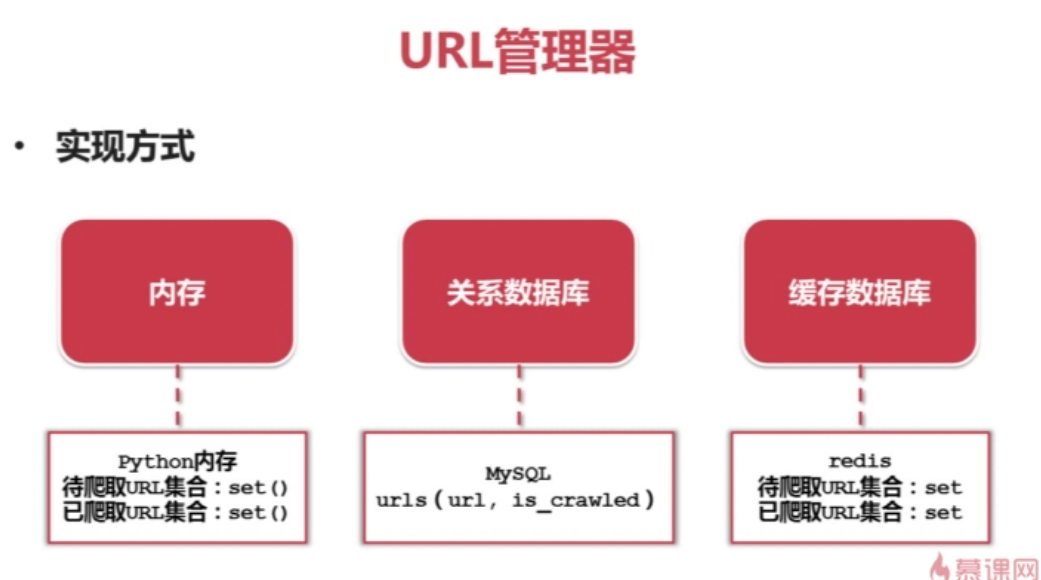
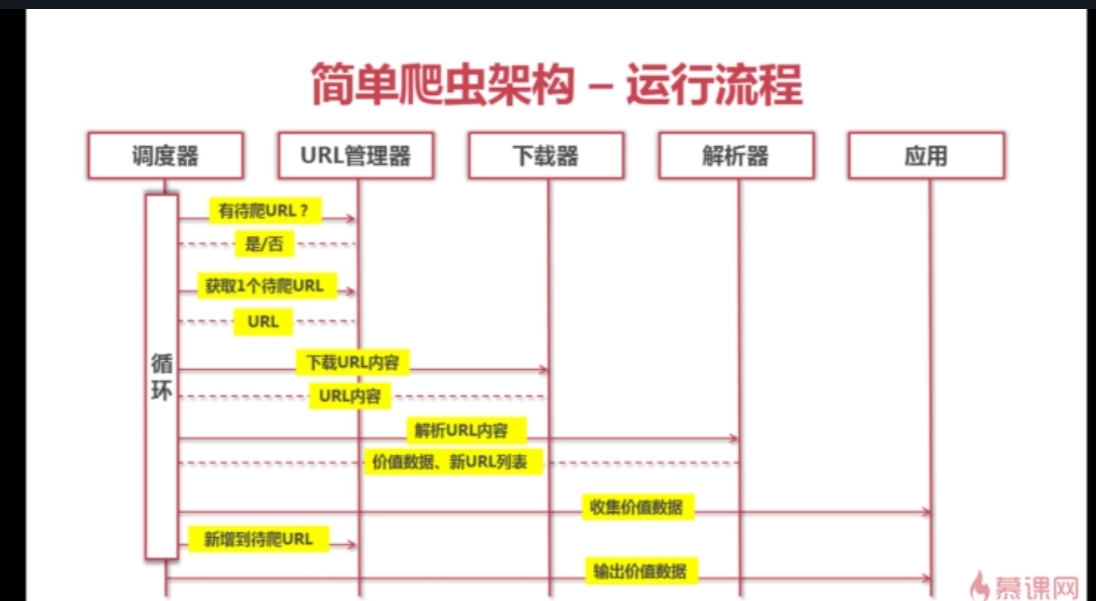
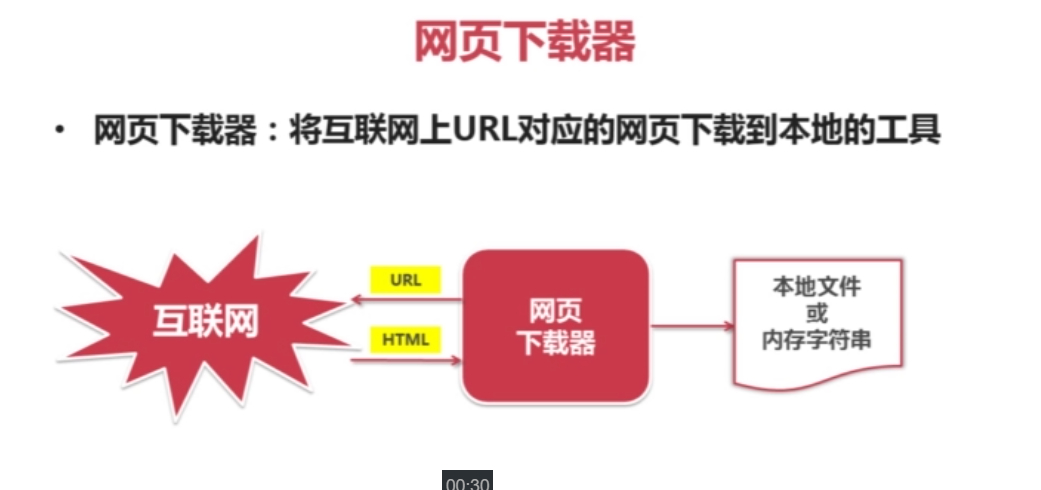

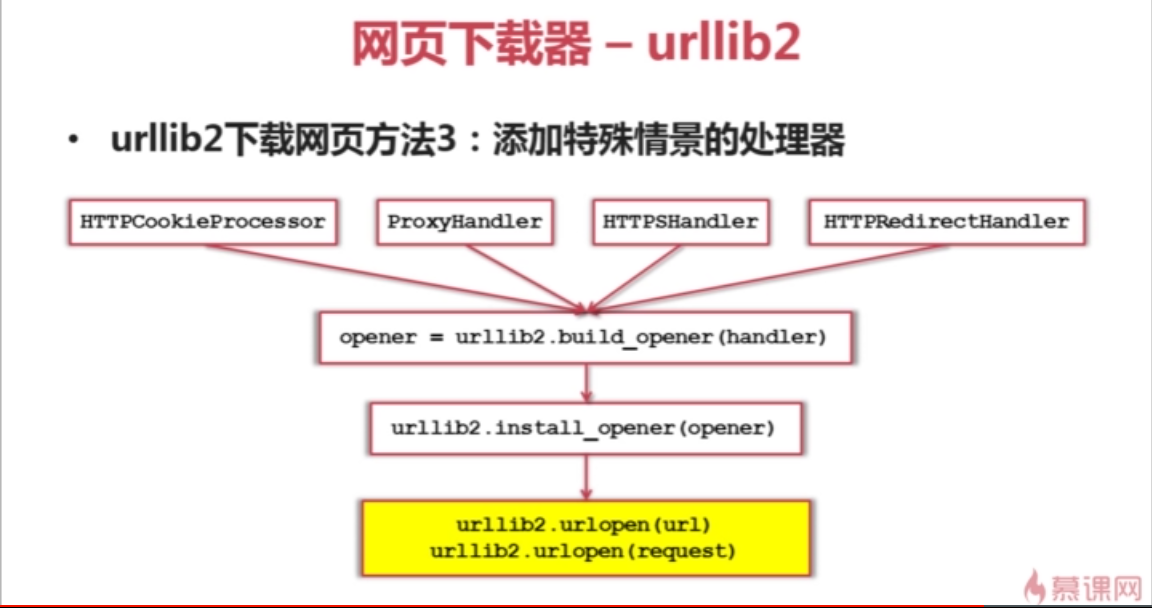
有些网页需要用户登录才能访问 需要添加Cookie的处理 使用 HTTPCookieProcessor
有些网页需要代理才能访问 使用 ProxyHandler
有些网页使用协议HTTPS 加密访问的 我们使用HTTPSHandler
还有的url之间相互跳转 的关系 我们使用 HTTPRedirectHandler
我们把Handler 传给 opener = urllib2.build_opener(handler)方法 创建opener对象
然后使用把opener对象传递给 urllib2.install_opener(opener) 这样就有了处理这些场景的能力
网页解析器 - Beautiful Soup -语法:
BeautifulSoup 例:
例:
import urllib2,cookielib
#创建cookie容器
cj = cookielib.CookieJar()
#创建1个opener
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
#给urllib2安装opener
urllib2.install_opener(opener)
#使用带有cookie的urllib2访问网页
response = urllib2.urlopen("http://www.baidu.com/")有些网页需要用户登录才能访问 需要添加Cookie的处理 使用 HTTPCookieProcessor
有些网页需要代理才能访问 使用 ProxyHandler
有些网页使用协议HTTPS 加密访问的 我们使用HTTPSHandler
还有的url之间相互跳转 的关系 我们使用 HTTPRedirectHandler
我们把Handler 传给 opener = urllib2.build_opener(handler)方法 创建opener对象
然后使用把opener对象传递给 urllib2.install_opener(opener) 这样就有了处理这些场景的能力
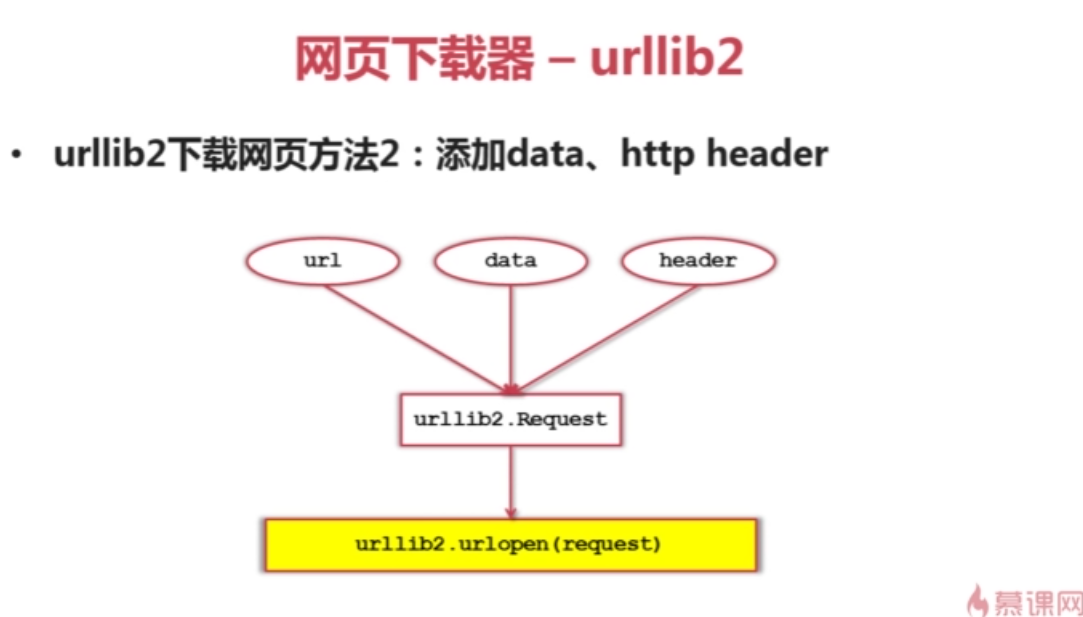
例2:
import urllib2
url = "http://www.baidu.com/"
print '第一种方法'
response1 = urllib2.urlopen(url)
print response1.getcode() #状态码
print len(response1.read())
print '第二种方法'
request = urllib2.Request(url)
request.add_header("user_agent","Mozilla/5.0") #伪装成Mozilla浏览器
response2 = urllib2.urlopen(request)
print response2.getcode() #状态码
print len(response2.read())
print '第三种方法'
import cookielib
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
urllib2.install_opener(opener)
response3 = urllib2.urlopen(url)
print response3.getcode() #状态码
print cj #输出Cookie内容
print response3.read()网页解析器 - Beautiful Soup -语法:
1) 创建BeautifulSoup对象
from bs4 import BeautifulSoup #根据HTML网页字符串创建BeautifulSoup对象 soup = BeautifulSoup( html_doc, #HTML文档字符串 'html.parser'#HTML解析器 from_encoding='utf8'#HTML文档的编码 )
2) 搜索节点(find_all,find,(参数相同)) #方法 :find_all(name,attrs,string)
#查找所有标签为 a 的节点
soup.find_all('a')
#查找所有标签为a,链接符合/view/123.html形式的节点
soup.find_all('a',href='/view/123.html')
soup.find_all('a',href=re.compile(r'/view/\d+\.html')) #可以传入一个正则表达式
#查找标签为div,class为abc,文字为python的节点
soup.find_all('div',class_='abc',string='python')3)访问节点信息 #得到节点:<a href='1.html'>Python</a> #获取查找到的节点的标签名称 node.name #获取查找到的a节点的href属性 node['href'] #获取查找到的a节点的链接文字 mode.get_text()
BeautifulSoup 例:
from bs4 import BeautifulSoup
import re #正则表达式re模块
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup =BeautifulSoup(html_doc,'html.parser',from_encoding='utf-8')
print"获取所有链接"
links = soup.find_all('a')
for link in links:
print link.name,link['href'],link.get_text()
print"获取Lacie的链接"
link_node = soup.find('a',href='http://example.com/lacie')
print link_node.name,link_node['href'],link_node.get_text()
print'正则匹配'
link_node = soup.find('a',href = re.compile(r,'ill'))
print link_node.name,link_node['href'],link_node.get_text()
print '获取p段落文字'
p_node = soup.find('p',class_ = 'title')
print p_node.name,p_node.get_text()

相关文章推荐
- Python学习笔记(八)爬虫基础(正则和编解码)
- 【python学习笔记】7:用python实现爬虫-基础
- 【实战\聚焦Python分布式爬虫必学框架Scrapy 打造搜索引擎项目笔记】第3章 爬虫基础知识回顾
- Python爬虫学习笔记之基础知识
- python学习笔记(3)--爬虫基础教程1
- python 基础学习笔记1
- 零基础自学用Python 3开发网络爬虫(二): 用到的数据结构简介以及爬虫Ver1.0 alpha
- python基础语法笔记
- python爬虫笔记
- python基础教程笔记(1)
- Python爬虫入门之爬虫基础了解
- Python 爬虫笔记(获取整个站点中的所有外部链接)
- python笔记(基础知识)
- python 3.0学习笔记之二------python基础小知识
- Python基础学习笔记一
- Python基础学习笔记二
- Python基础学习笔记四
- python 爬虫学习笔记(2)
- Python之基础知识学习笔记