Data Structure:Binary Tree
2016-09-29 03:01
197 查看
二叉树就是每个节点至多有两个孩子的树。
特殊的二叉树:完全二叉树和满二叉树。满二叉树是叶子节点层(最后一层)是满的二叉树(其它层当然也是满的)。而完全二叉树则叶子节点层不要求满,但是编号不能断的二叉树。什么是编号不能断?意思是按照顺序存储结构给完全二叉树的节点编号,编号出现中断,譬如最后一层有个叶子节点是父节点的左孩子,但它是空的,但另外一个叶子节点作为同一个父节点的右孩子,不为空。那么,编号就出现了中断。所以,就不是一个完全二叉树。如下图所示:
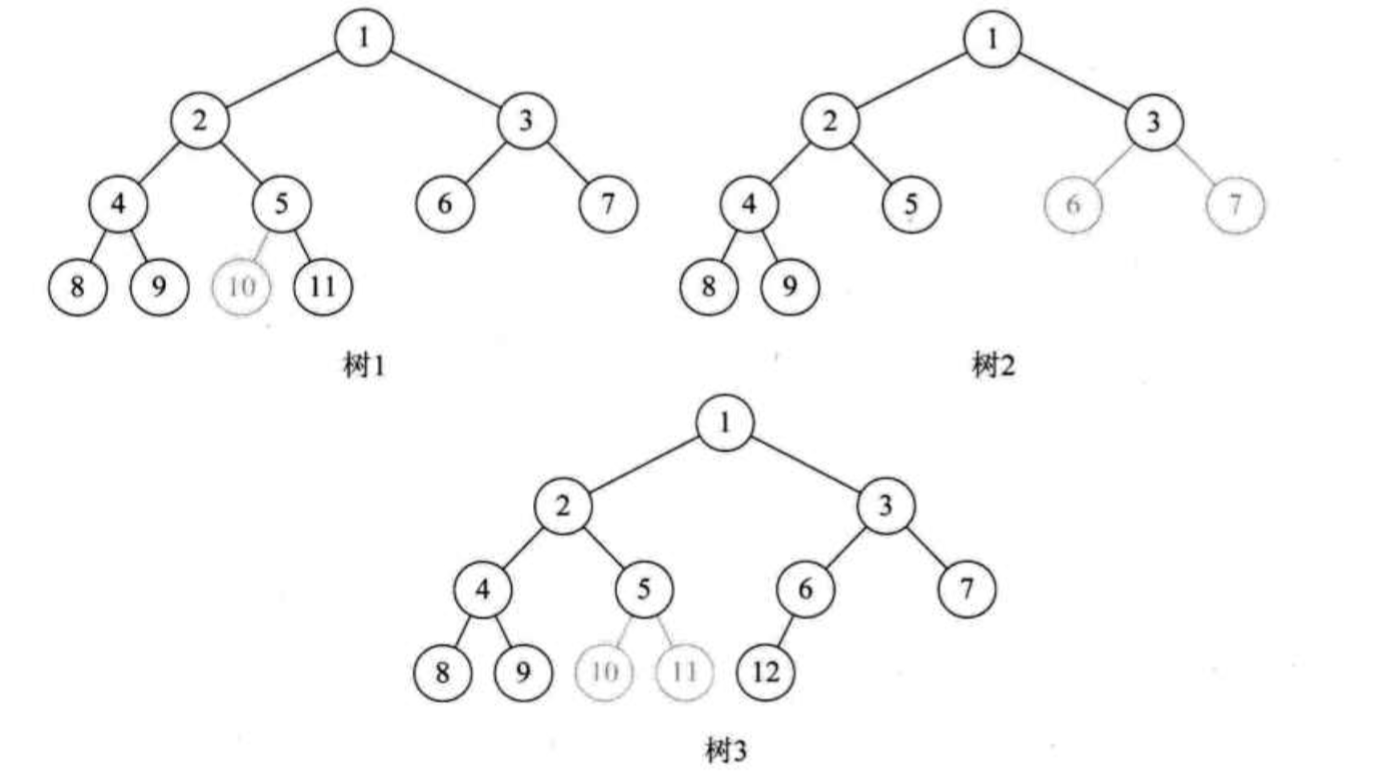
这样的就是完全二叉树:

所以,非满二叉树的完全二叉树的叶子节点层的左边是连续而满的,倒数第二层的右边都是叶子节点。
同时,二叉树也有一些性质十分重要(源于二叉树的结点最多有两个孩子的性质):
1)二叉树的第i层最多有2^(i-1)个节点;
2)拥有h层(高度为h)的二叉树最多有2^(h)-1个节点;
3)对于完全二叉树而言,有n个结点对应二叉树的高度为:lowfloor(log2(n)) + 1。也就是说,数量级是log2(n)。注意,只是完全二叉树有这个性质,因为它能保证最后一层以上的所有层都是满的。
4) 鉴于完全二叉树的性质,对于完全二叉树,我们可以使用顺序存储结构(数组)来存储。且其父节点与子节点的index之间有以下关系:
假设父节点的索引是i,那么其左右孩子的索引是:首先check 2i+1 是否大于节点总数(数组长度),否的话:左节点index: 2i + 1。同理,右节点:2i + 2。
而知道了子节点为i,其父节点的index是:i - 1/2.
5) 普及一个概念:什么是二叉树的度数?(就是这棵二叉树有多少条边)。什么是一个节点的度数?就是这个节点有多少条边连接。
二叉树的遍历:
1、前序遍历:从根节点开始,到哪个节点就打印当前节点的值。然后,求左子树的前序遍历,再求右子树的前序遍历。
2、后序遍历:从根节点开始,到哪个节点我都先不打印,先求左子树的后序遍历,再求右子树的后序遍历,最后打印根。
3、中序遍历:从根节点开始,到哪个节点我都先不打印,先求左子树的中序遍历,然后打印根的值,最后求右子树的中序遍历。
前序和后序遍历可以给出一个二叉树的根节点是哪个,但不能确定根节点的左右两棵子树有哪些节点。只有结合前序或者后序遍历给出的根节点,才能通过中序遍历知道根节点的左右子树有哪些节点。从而,根据前序+中序 --》 后序。或者后序 + 中序 --》 前序。
注意,只有知道了中序+前序/后序 才能确定一棵唯一的二叉树。如果只有前序+后序,是不可以的。
二叉树的存储结构:
1)顺序结构:利用数组来存储二叉树的元素,但如果我们在数组中不存储空节点为null而直接跳过的话,而且当前二叉树不是一棵完全二叉树时,是不能确定这棵二叉树的,因为我们不知道哪些节点是空的。如果,存储了空间点在数组中,遇到了斜树这样的极端情况(每一个节点都只有一个孩子,所以每一层只有一个节点),这种情况的话,极度浪费了很多的数组空间,所以,顺序存储结构是不鼓励采用的。只有遇到了完全二叉树时,顺序存储结构才作为一个选择。
2)链表结构:链表结构就是我们常在编程题中遇到的结构。是适合所有二叉树的存储结构。每个链表元素设置三个域,当前节点值域,左孩子指针域和右孩子指针域。如果没有左/右孩子,则把对应的左/右指针域设为空。当遇到经常要向上求父节点的应用场景时,可以考虑设多一个父节点指针域,提高计算效率(类似于双向链表,但有多对1的关系,2个孩子对着1个父节点)。
建立一个平衡二叉树的Java代码:
然而,在普通链表的实现上,也能充分利用好空的指针域,遍历二叉树成为了遍历链表。这种做法让普通二叉树,转化为线索二叉树。
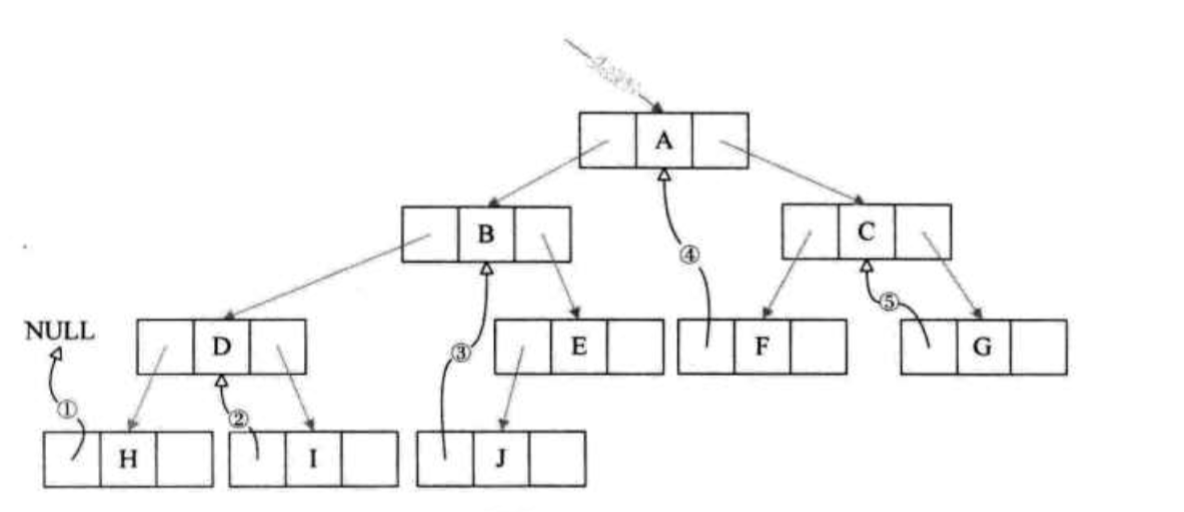
线索二叉树的建造:以中序遍历为例,如果当前节点是叶子节点,把指向中序遍历的前面一个节点的的指针放在当前叶子节点的左孩子指针域,然后把指向后一个节点的指针放在当前叶子节点的右孩子指针域。这两个节点成为当前节点的前继和后继。这样,就能顺着这些叶子节点的线索遍历整个二叉树了。当然,构造的时候,需要在指针域再添加一个flag来辨认,这个指针域指向的是线索还是孩子。整个线索二叉树就如下图所示:
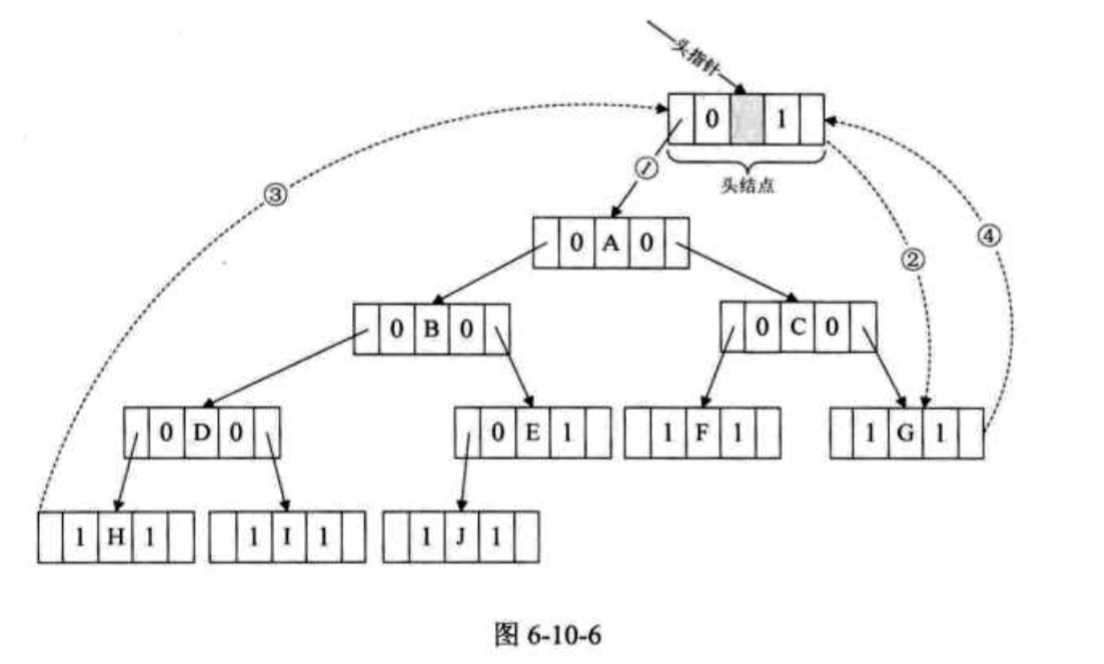
然而,为了方便遍历,通常会设置一个额外的头结点(在归并排序链表的题目,合并链表的时候,也是创建了一个dummy node来实现的),这样就能把最左边的叶子节点的左线索指向这个dummy node。然后把最右边的叶子节点(中序遍历的最后的节点)的右指针域指向dummy node。整个树就是变成这样子:
下面介绍一个很出名的最优权值二叉树:Huffman Tree。霍夫曼树。霍夫曼树的构建在知道查找的值的频率前提下,使得二分查找时,减少经过的分支判断所发明的树。类似的原理,霍夫曼树也能减少字符串编码的长度,这就是压缩的原理。
以压缩字符串的编码为例,如果我们对常见的字符进行短的编码,而随着频率的降低,慢慢将长的编码赋予给那些字符。
举个例子:假如统计的频率是这样的,A 27 B 8 C 15 D 15 E 30 F 5
首先挑最小的两个组成第一个2层的子树,把最小的放在左子树、稍大的放在右子树。
就有了:
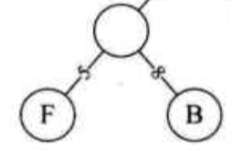
然后得到的根节点作为新的节点,权重是13. 接着把这个新的节点放进剩下的节点的有序序列中,和比新节点大的节点结合组合另一个新的节点。
13<15,所以新的节点在C或者D在左边,以C为例:
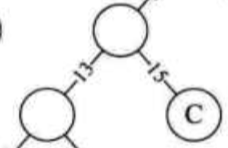
接着,13+15 = 28为新的节点。28 < 30,所以只能用30和28组成新的节点。这时候没有比新节点更大的,就完成了一边的子树了。
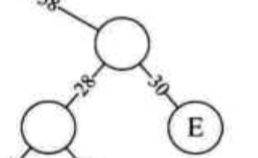
接着,根据剩下的节点还有多个,如果只有1个,则直接根据它和新节点的大小安排它们各自是根节点的左孩子还是右节点。所以,现在首先构造另一边子树。根据15和27,15在左,27在右,构造一个新的节点:
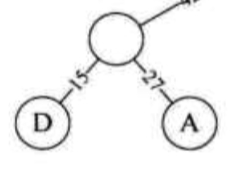
然后把根节点和左右子树结合,得到最终的霍夫曼树:
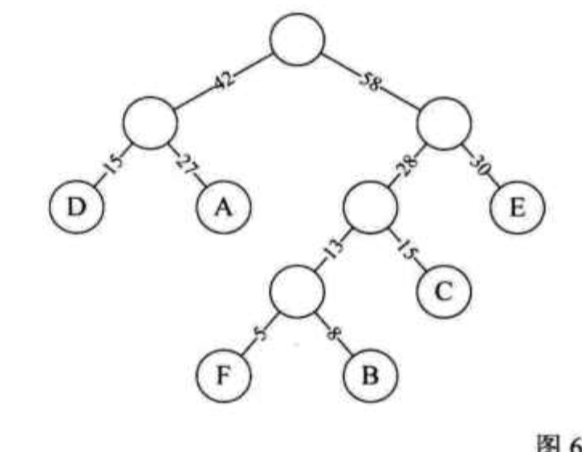
将霍夫曼树转为霍夫曼编码树则是:左边的路径权值为0,右边路径为1即可:
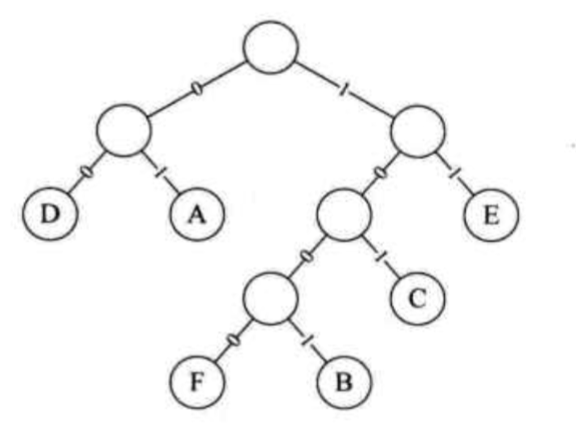
只要通信的双方都有霍夫曼编码树,便可以对应的编码和解码:
收到1001 01 00 101 01 00 1000 11 11 00时,尽量将编码尝试最长解释。
1001是有的,所以是B。
01之后再没有0,所以是A。
然后00之后再也没有,所以D。
接着101之后再也没有,所以是C。
以此类推,接下来是A、D、F、E、E、D。
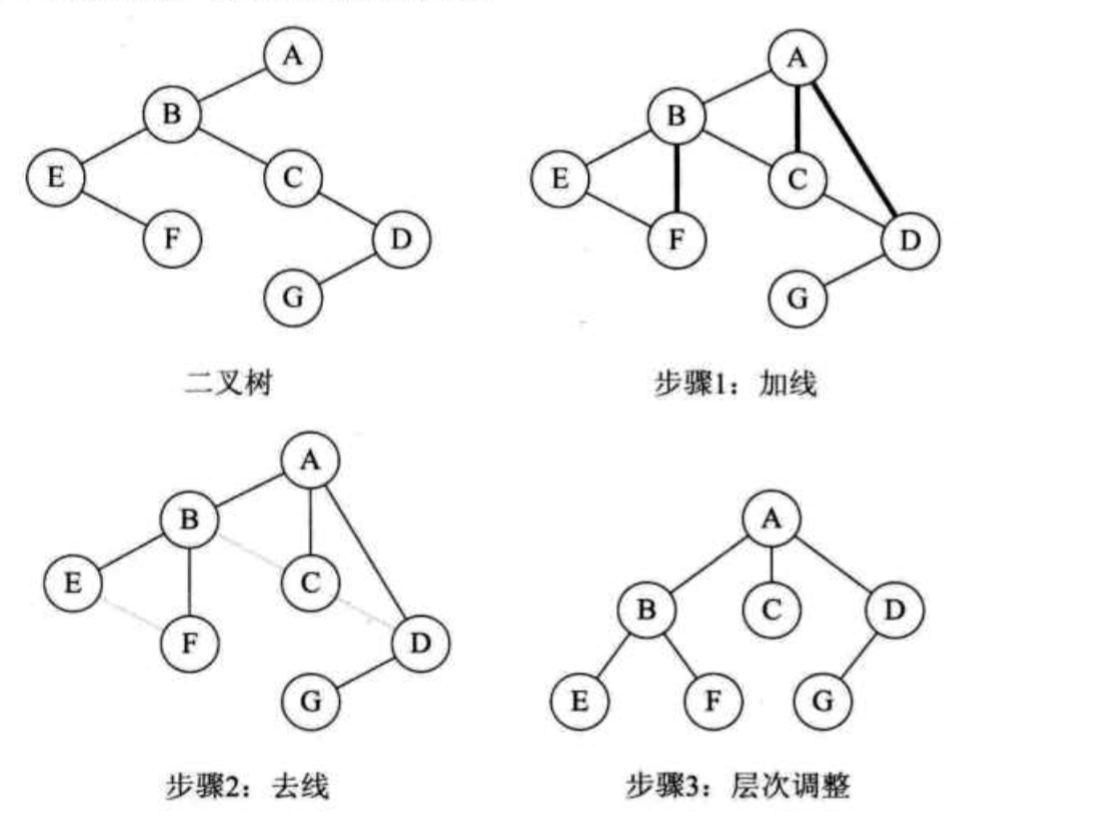
最后,介绍一个将其它树转换成二叉树的方法:
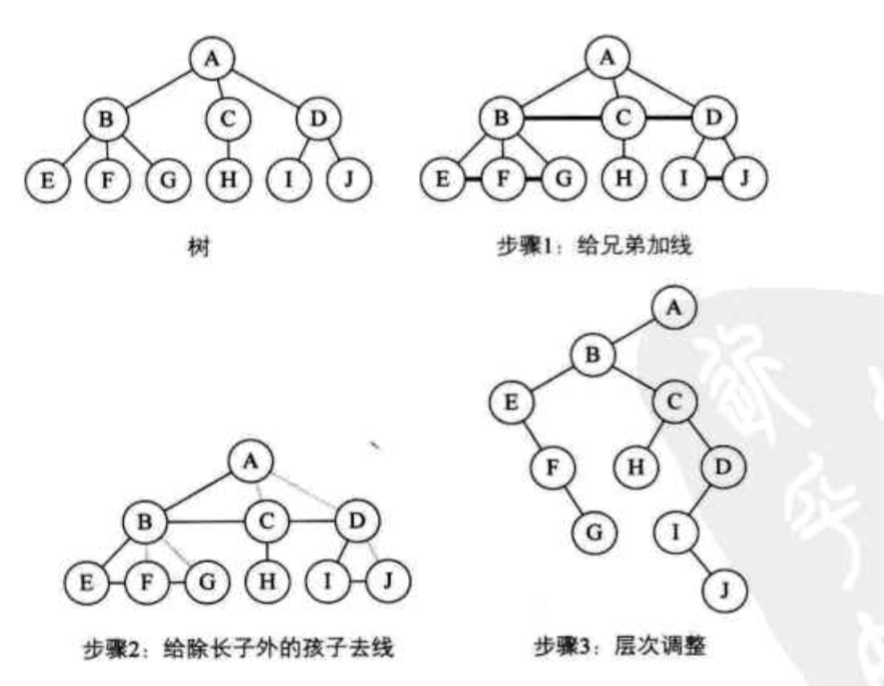
首先,第一步是给同层的兄弟加上连线,然后,除了同层的第一个孩子节点外,其它同父的孩子节点和其父节点取消链接。然后,其它的同父孩子节点变为右子节点和右子节点的右子节点。
相反,变回来也是这样的:凡是右孩子,其实全都是同级的,链接父节点,然后,去掉链接右节点的连线。
特殊的二叉树:完全二叉树和满二叉树。满二叉树是叶子节点层(最后一层)是满的二叉树(其它层当然也是满的)。而完全二叉树则叶子节点层不要求满,但是编号不能断的二叉树。什么是编号不能断?意思是按照顺序存储结构给完全二叉树的节点编号,编号出现中断,譬如最后一层有个叶子节点是父节点的左孩子,但它是空的,但另外一个叶子节点作为同一个父节点的右孩子,不为空。那么,编号就出现了中断。所以,就不是一个完全二叉树。如下图所示:
这样的就是完全二叉树:
所以,非满二叉树的完全二叉树的叶子节点层的左边是连续而满的,倒数第二层的右边都是叶子节点。
同时,二叉树也有一些性质十分重要(源于二叉树的结点最多有两个孩子的性质):
1)二叉树的第i层最多有2^(i-1)个节点;
2)拥有h层(高度为h)的二叉树最多有2^(h)-1个节点;
3)对于完全二叉树而言,有n个结点对应二叉树的高度为:lowfloor(log2(n)) + 1。也就是说,数量级是log2(n)。注意,只是完全二叉树有这个性质,因为它能保证最后一层以上的所有层都是满的。
4) 鉴于完全二叉树的性质,对于完全二叉树,我们可以使用顺序存储结构(数组)来存储。且其父节点与子节点的index之间有以下关系:
假设父节点的索引是i,那么其左右孩子的索引是:首先check 2i+1 是否大于节点总数(数组长度),否的话:左节点index: 2i + 1。同理,右节点:2i + 2。
而知道了子节点为i,其父节点的index是:i - 1/2.
5) 普及一个概念:什么是二叉树的度数?(就是这棵二叉树有多少条边)。什么是一个节点的度数?就是这个节点有多少条边连接。
二叉树的遍历:
1、前序遍历:从根节点开始,到哪个节点就打印当前节点的值。然后,求左子树的前序遍历,再求右子树的前序遍历。
2、后序遍历:从根节点开始,到哪个节点我都先不打印,先求左子树的后序遍历,再求右子树的后序遍历,最后打印根。
3、中序遍历:从根节点开始,到哪个节点我都先不打印,先求左子树的中序遍历,然后打印根的值,最后求右子树的中序遍历。
前序和后序遍历可以给出一个二叉树的根节点是哪个,但不能确定根节点的左右两棵子树有哪些节点。只有结合前序或者后序遍历给出的根节点,才能通过中序遍历知道根节点的左右子树有哪些节点。从而,根据前序+中序 --》 后序。或者后序 + 中序 --》 前序。
注意,只有知道了中序+前序/后序 才能确定一棵唯一的二叉树。如果只有前序+后序,是不可以的。
二叉树的存储结构:
1)顺序结构:利用数组来存储二叉树的元素,但如果我们在数组中不存储空节点为null而直接跳过的话,而且当前二叉树不是一棵完全二叉树时,是不能确定这棵二叉树的,因为我们不知道哪些节点是空的。如果,存储了空间点在数组中,遇到了斜树这样的极端情况(每一个节点都只有一个孩子,所以每一层只有一个节点),这种情况的话,极度浪费了很多的数组空间,所以,顺序存储结构是不鼓励采用的。只有遇到了完全二叉树时,顺序存储结构才作为一个选择。
2)链表结构:链表结构就是我们常在编程题中遇到的结构。是适合所有二叉树的存储结构。每个链表元素设置三个域,当前节点值域,左孩子指针域和右孩子指针域。如果没有左/右孩子,则把对应的左/右指针域设为空。当遇到经常要向上求父节点的应用场景时,可以考虑设多一个父节点指针域,提高计算效率(类似于双向链表,但有多对1的关系,2个孩子对着1个父节点)。
建立一个平衡二叉树的Java代码:
package com.xjieli.datastrc;
import java.util.ArrayList;
import java.util.LinkedList;
class Node{
int val;
Node leftchild;
Node rightchild;
public Node(int inputval){
this.val = inputval;
}
}
class Stack<T>{
private LinkedList<T> storage = new LinkedList<T>();
public int size(){
return storage.size();
}
public void push(T input){
storage.addLast(input);
}
public T peek(){
return storage.getLast();
}
public T pop(){
return storage.removeLast();
}
}
class BinarySearchTree{
private Node root;
public BinarySearchTree(){
root = null;
}
public Node getRoot(){
return this.root;
}
public boolean insertNode(Node new_node){
if(searchNode(new_node.val) == null){
Node parent = findParent(new_node.val);
if(parent == null){
root = new_node;
return true;
}
if(new_node.val < parent.val){
parent.leftchild = new_node;
}else{
parent.rightchild = new_node;
}
return true;
}
return false;
}
public Node searchNode(int inputval){
Node current = root;
while(current != null){
if(current.val == inputval){
return current;
}
if(inputval < current.val){
current = current.leftchild;
}else{
current = current.rightchild;
}
}
return current;
}
public Node findParent(int inputval){
Node parent = null;
Node current = root;
while(current != null){
if(current.val == inputval){
return parent;
}
parent = current;
if(inputval < current.val){
current = current.leftchild;
}else{
current = current.rightchild;
}
}
return parent;
}
public ArrayList<Integer> traversal(Node root){
ArrayList<Integer> result = new ArrayList<Integer>();
if(root == null){
return result;
}
ArrayList<Integer> left = traversal(root.leftchild);
ArrayList<Integer> right = traversal(root.rightchild);
result.addAll(left);
result.add(root.val);
result.addAll(right);
return result;
}
public ArrayList<Integer> traversal_nrecur(Node root){
ArrayList<Integer> result = new ArrayList<Integer>();
Stack<Node> ins = new Stack<Node>();
while(root != null || ins.size()>0){
while(root != null){
ins.push(root);
root = root.leftchild;
}
if(ins.size() > 0){
root = ins.pop();
result.add(root.val);
root = root.rightchild;
}
}
return result;
}
}
public class BinaryTree {
public static void main(String[] args) {
// TODO Auto-generated method stub
int[] input = new int[]{2,3,5,6,1,8,9,};
BinarySearchTree tree = new BinarySearchTree();
for(int temp : input){
tree.insertNode(new Node(temp));
}
ArrayList<Integer> result = tree.traversal_nrecur(tree.getRoot());
for(int ins : result){
System.out.println(ins);
}
}
}然而,在普通链表的实现上,也能充分利用好空的指针域,遍历二叉树成为了遍历链表。这种做法让普通二叉树,转化为线索二叉树。
线索二叉树的建造:以中序遍历为例,如果当前节点是叶子节点,把指向中序遍历的前面一个节点的的指针放在当前叶子节点的左孩子指针域,然后把指向后一个节点的指针放在当前叶子节点的右孩子指针域。这两个节点成为当前节点的前继和后继。这样,就能顺着这些叶子节点的线索遍历整个二叉树了。当然,构造的时候,需要在指针域再添加一个flag来辨认,这个指针域指向的是线索还是孩子。整个线索二叉树就如下图所示:
然而,为了方便遍历,通常会设置一个额外的头结点(在归并排序链表的题目,合并链表的时候,也是创建了一个dummy node来实现的),这样就能把最左边的叶子节点的左线索指向这个dummy node。然后把最右边的叶子节点(中序遍历的最后的节点)的右指针域指向dummy node。整个树就是变成这样子:
下面介绍一个很出名的最优权值二叉树:Huffman Tree。霍夫曼树。霍夫曼树的构建在知道查找的值的频率前提下,使得二分查找时,减少经过的分支判断所发明的树。类似的原理,霍夫曼树也能减少字符串编码的长度,这就是压缩的原理。
以压缩字符串的编码为例,如果我们对常见的字符进行短的编码,而随着频率的降低,慢慢将长的编码赋予给那些字符。
举个例子:假如统计的频率是这样的,A 27 B 8 C 15 D 15 E 30 F 5
首先挑最小的两个组成第一个2层的子树,把最小的放在左子树、稍大的放在右子树。
就有了:
然后得到的根节点作为新的节点,权重是13. 接着把这个新的节点放进剩下的节点的有序序列中,和比新节点大的节点结合组合另一个新的节点。
13<15,所以新的节点在C或者D在左边,以C为例:
接着,13+15 = 28为新的节点。28 < 30,所以只能用30和28组成新的节点。这时候没有比新节点更大的,就完成了一边的子树了。
接着,根据剩下的节点还有多个,如果只有1个,则直接根据它和新节点的大小安排它们各自是根节点的左孩子还是右节点。所以,现在首先构造另一边子树。根据15和27,15在左,27在右,构造一个新的节点:
然后把根节点和左右子树结合,得到最终的霍夫曼树:
将霍夫曼树转为霍夫曼编码树则是:左边的路径权值为0,右边路径为1即可:
只要通信的双方都有霍夫曼编码树,便可以对应的编码和解码:
收到1001 01 00 101 01 00 1000 11 11 00时,尽量将编码尝试最长解释。
1001是有的,所以是B。
01之后再没有0,所以是A。
然后00之后再也没有,所以D。
接着101之后再也没有,所以是C。
以此类推,接下来是A、D、F、E、E、D。
最后,介绍一个将其它树转换成二叉树的方法:
首先,第一步是给同层的兄弟加上连线,然后,除了同层的第一个孩子节点外,其它同父的孩子节点和其父节点取消链接。然后,其它的同父孩子节点变为右子节点和右子节点的右子节点。
相反,变回来也是这样的:凡是右孩子,其实全都是同级的,链接父节点,然后,去掉链接右节点的连线。

相关文章推荐
- Data Structure:Binary Tree
- Data Structure:Binary Tree
- [Data Structure][Tree][Binary Tree]POJ 2255----Tree Recovery
- Data Structure:Binary Tree
- Data Structure:Binary Tree
- Data Structure:Binary Tree
- Data Structure:Binary Tree
- 原创:Data Structure 学习笔记 之一 hash
- sicily 1156 Binary tree
- python 实现的 binary tree
- HDU 4217 Data Structure?
- HDU 4217 Data Structure?(线段树)
- hdu 题目4217 Data Structure?(线段树,单点更新)
- hdu 4217 Data Structure?
- hdu4217 Data Structure? 线段树
- Learning Data Structure_2_线性表、栈和队列
- 关于算法面试中涉及Binary Tree的问题
- binary tree
- Binary Tree
- HDU 4217 Data Structure?(线段树 or 树状数组啊)