intelliJ IDEA进行spark配置和开发
2016-09-26 11:11
281 查看
前言:一直在使用python做数据处理,阅读spark官方文档时到后半部分的MLlib机器学习部分有些机器学习方法竟然没有python,很是遗憾,遂着手准备学学scale,毕竟原生语言,开发起来应该是丝丝入扣,顺滑平坦。
1.下载intelliJ IDEA
下载传送门
建议下载找个注册码安装Ultimate版本。
(在安装时不要一直点,看清楚意思再进行选择,尽量多的把能装上的语言都装上,这样会少不少麻烦。)
如果错过安装时候还是错了安装scale插件,那么按如下步奏走:
进入idea主界面
在线安装:
选择Plugins :
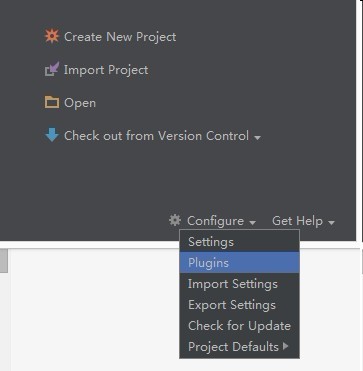
输入scala:
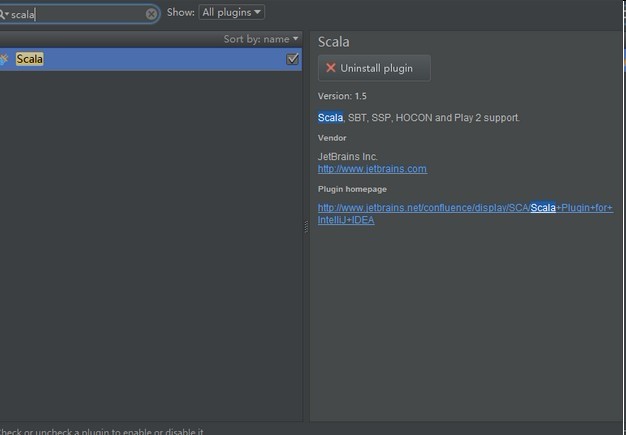
选择右侧的安装即可
2.安装好之后
file->new->project->选择scale
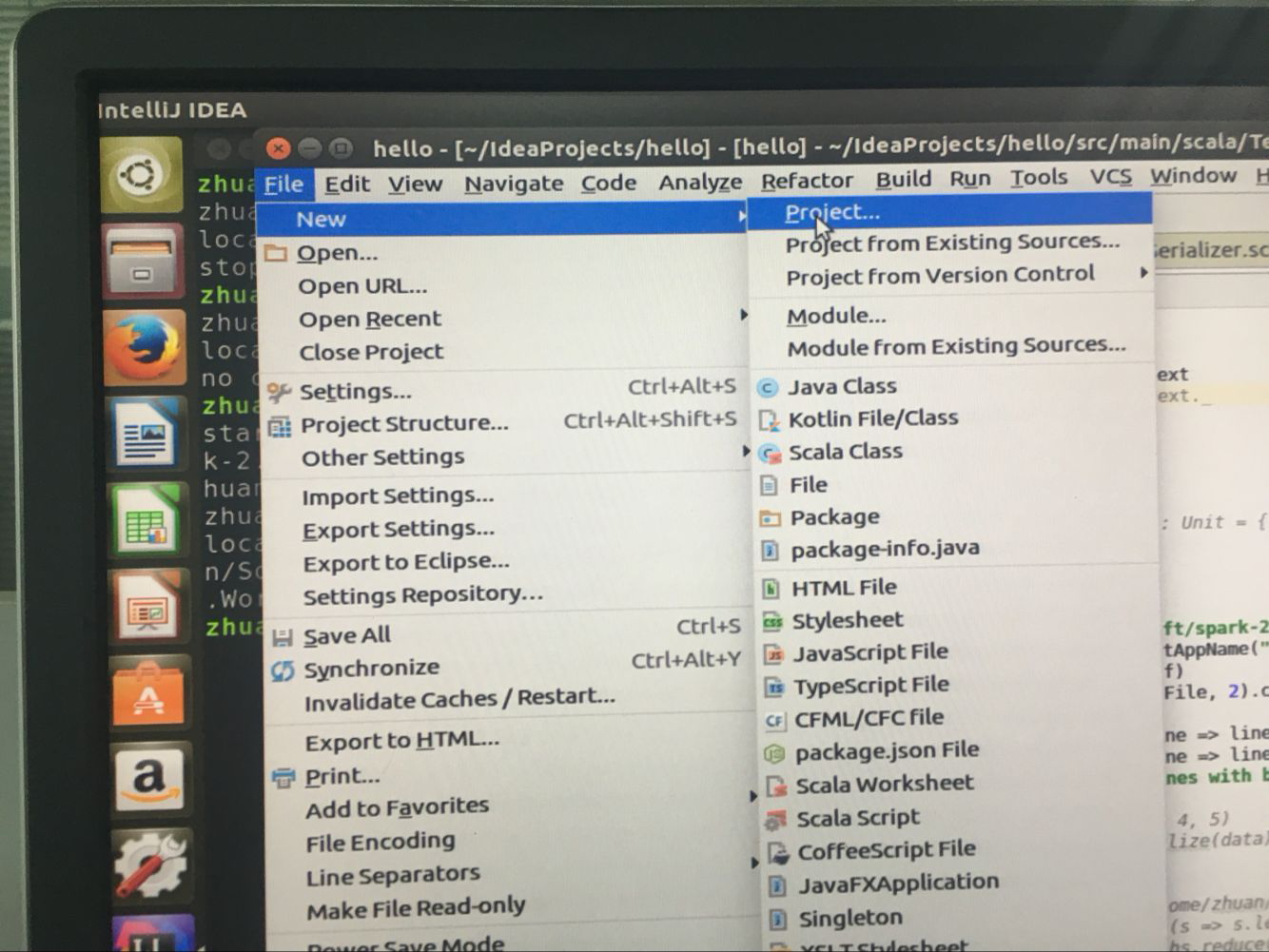
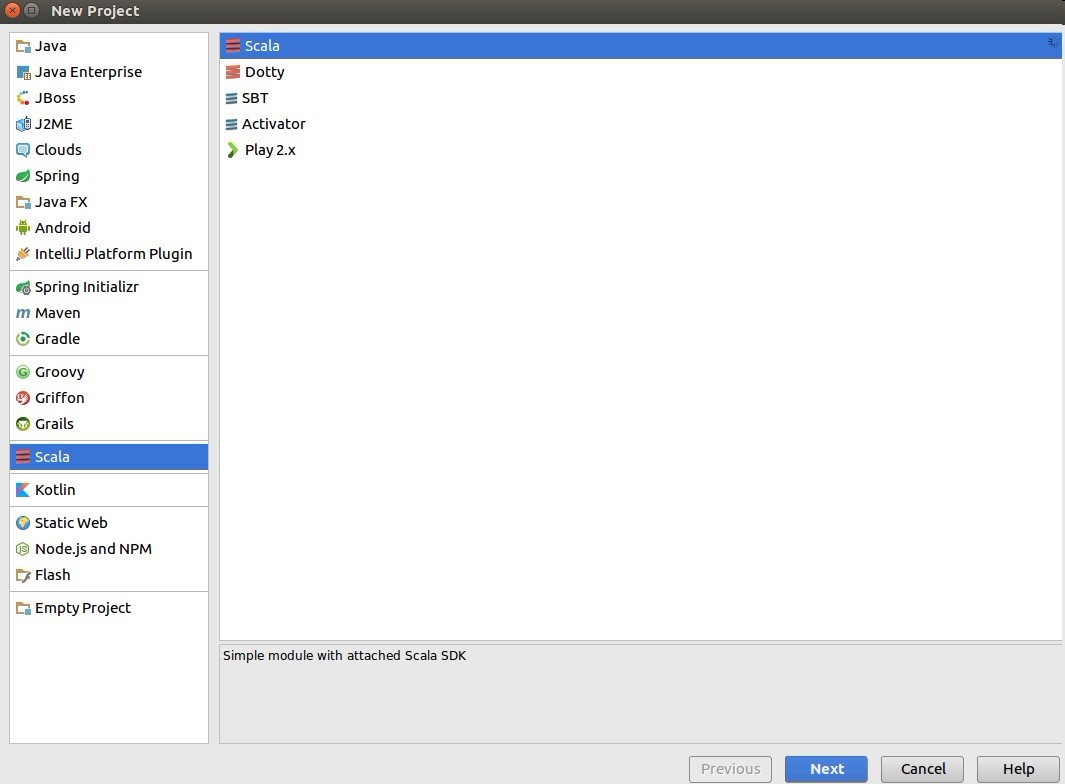
3.新建scale项目完成后,按如下目录进行配置
打开项目,目录如下:
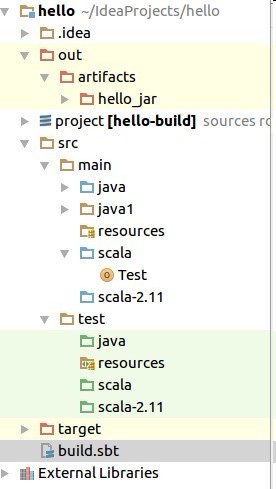
找到build.sbt添加如下配置:
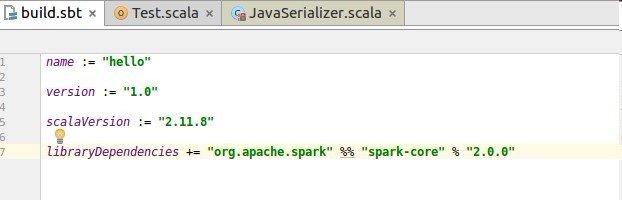
libraryDependencies += “org.apache.spark” %% “spark-core” % “2.0.0”
配置完成如下:
在src->scala->文件夹下创建new scaleClass
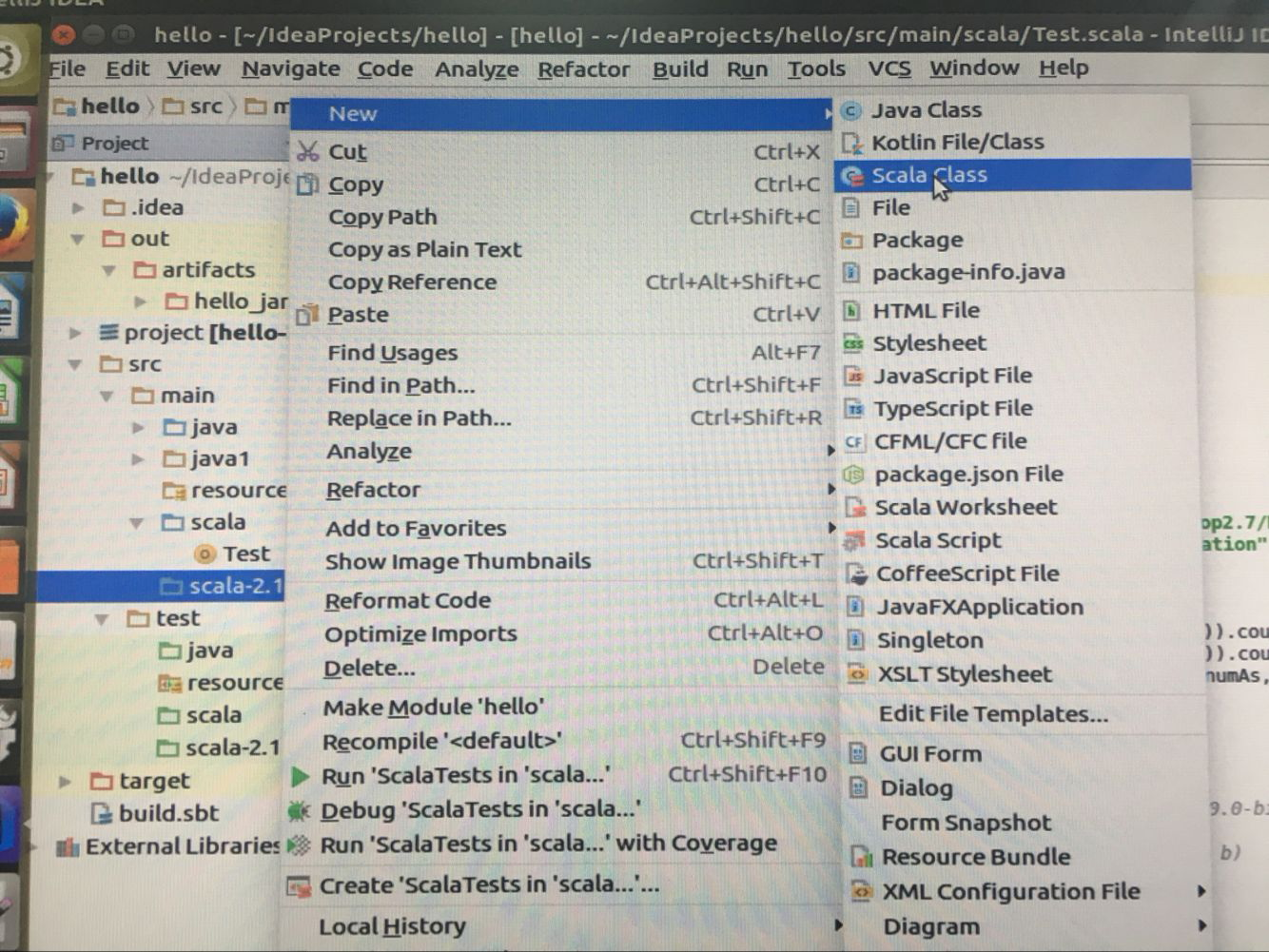
代码入下:
以上代码在打包jar之后可直接运行,相比官网spaekConf需要多设置master 和setJars路径。(根据读者自己的电脑情况需要更该setMaster和setJars)
4.打包jar
file ->project Struceture

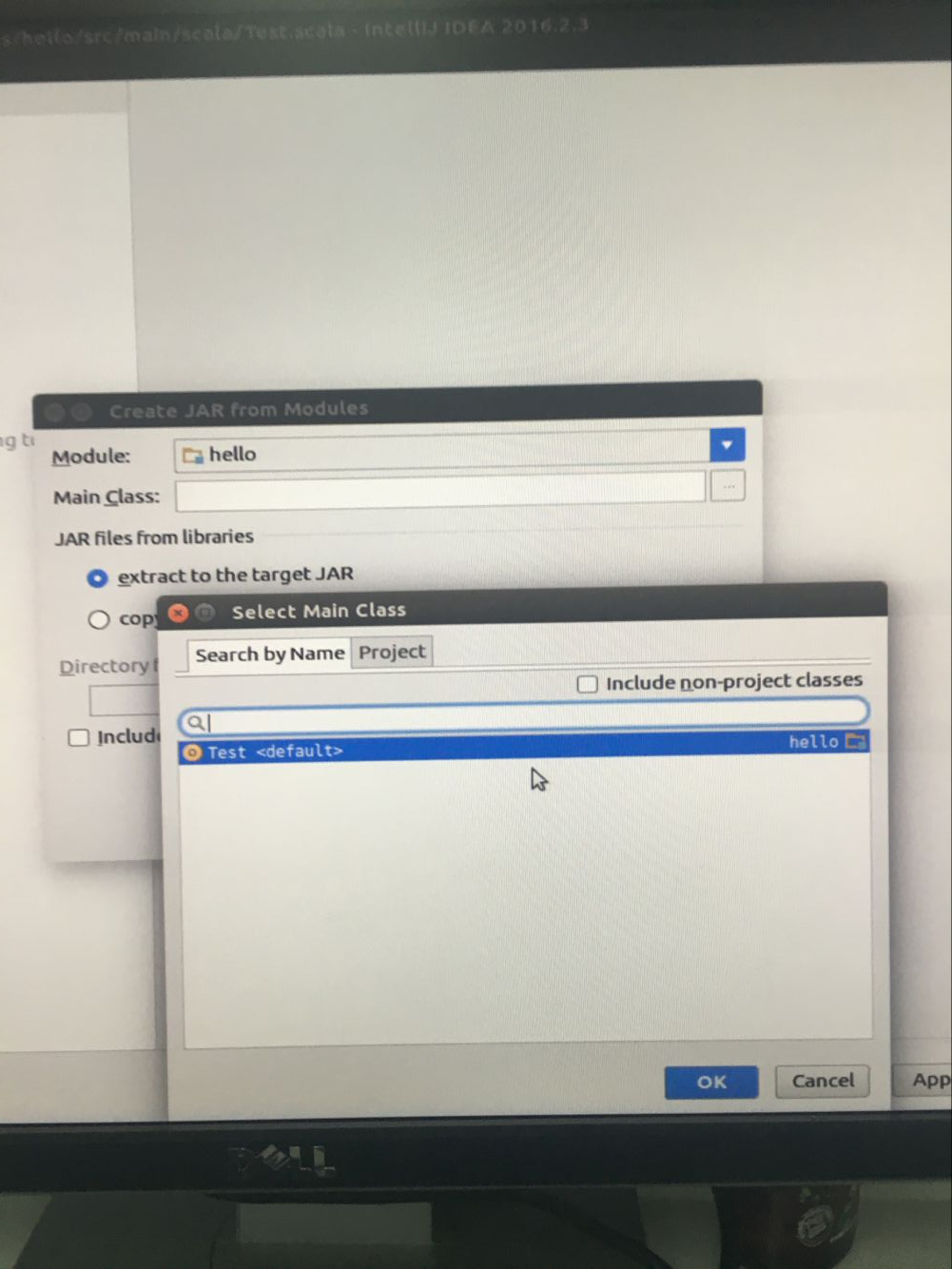
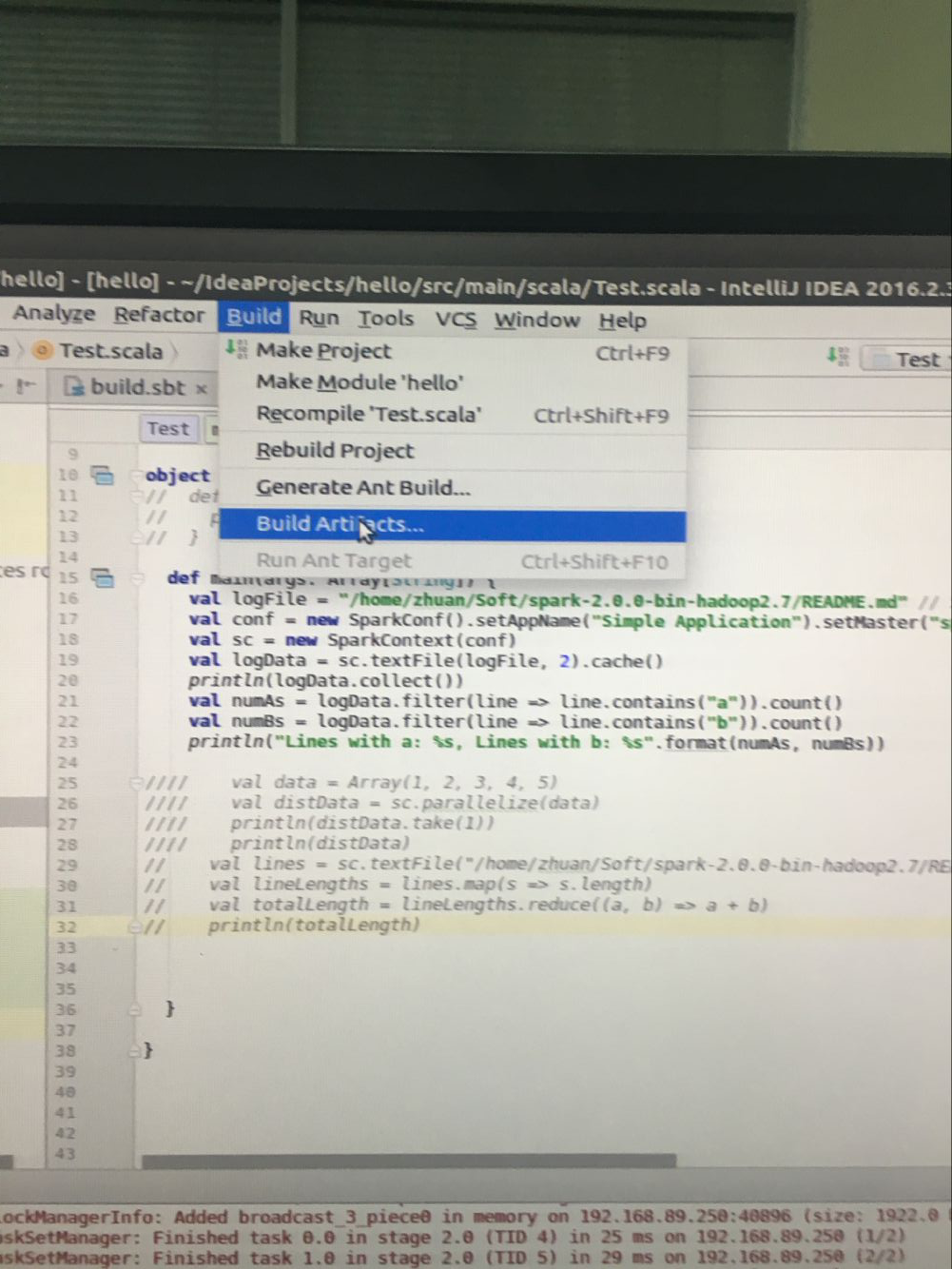
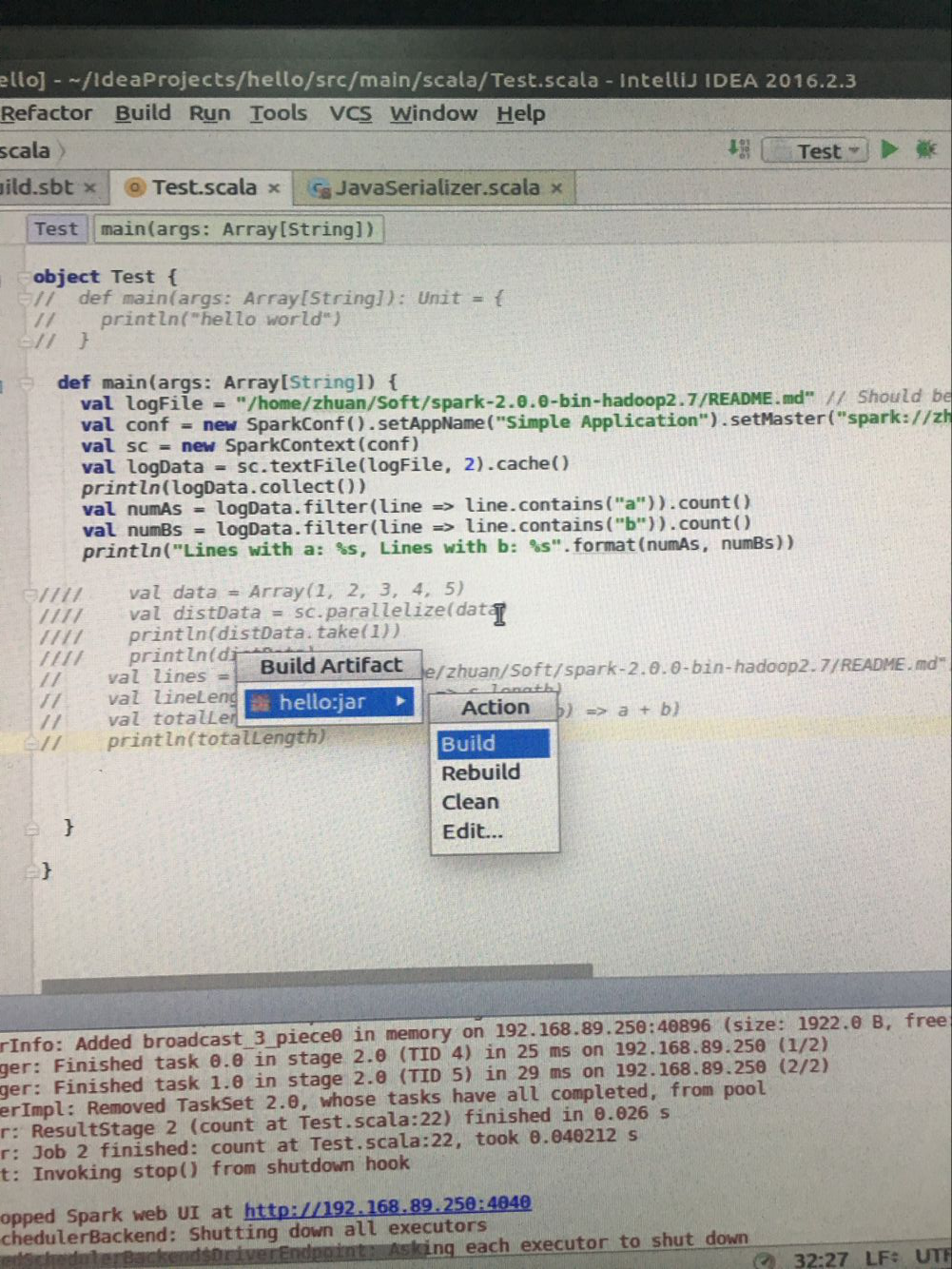
打好jar ,直接点击绿色运行就能直接运行了,每次修改代码都要重复打jar包这个过程,不知道是否有更好的方法。欢迎各位专家指正。
关于导包的问题:
我推荐使用sbt文件安装依赖,
格式如下:
名称可能不清楚的可以进入maven官网搜索查看
1.下载intelliJ IDEA
下载传送门
建议下载找个注册码安装Ultimate版本。
(在安装时不要一直点,看清楚意思再进行选择,尽量多的把能装上的语言都装上,这样会少不少麻烦。)
如果错过安装时候还是错了安装scale插件,那么按如下步奏走:
进入idea主界面
在线安装:
选择Plugins :
输入scala:
选择右侧的安装即可
2.安装好之后
file->new->project->选择scale
3.新建scale项目完成后,按如下目录进行配置
打开项目,目录如下:
找到build.sbt添加如下配置:
libraryDependencies += “org.apache.spark” %% “spark-core” % “2.0.0”
配置完成如下:
在src->scala->文件夹下创建new scaleClass
代码入下:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object Test {
// def main(args: Array[String]): Unit = {
// println("hello world")
// }
def main(args: Array[String]) {
val logFile = "/home/zhuan/Soft/spark-2.0.0-bin-hadoop2.7/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application").setMaster("spark://zhuan-OptiPlex-9020:7077").setJars(List("/home/zhuan/IdeaProjects/hello/out/artifacts/hello_jar/hello.jar"))
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
println(logData.collect())
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
//// val data = Array(1, 2, 3, 4, 5)
//// val distData = sc.parallelize(data)
//// println(distData.take(1))
//// println(distData)
// val lines = sc.textFile("/home/zhuan/Soft/spark-2.0.0-bin-hadoop2.7/README.md")
// val lineLengths = lines.map(s => s.length)
// val totalLength = lineLengths.reduce((a, b) => a + b)
// println(totalLength)
}
}以上代码在打包jar之后可直接运行,相比官网spaekConf需要多设置master 和setJars路径。(根据读者自己的电脑情况需要更该setMaster和setJars)
4.打包jar
file ->project Struceture
打好jar ,直接点击绿色运行就能直接运行了,每次修改代码都要重复打jar包这个过程,不知道是否有更好的方法。欢迎各位专家指正。
关于导包的问题:
我推荐使用sbt文件安装依赖,
格式如下:
#导入机器学习包依赖 libraryDependencies += "org.apache.spark" %% "spark-mllib" % "2.0.0" #导入spark核心包依赖 libraryDependencies += "org.apache.spark" %% "spark-core" % "2.0.0"
名称可能不清楚的可以进入maven官网搜索查看
附
:maven官网传送门def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Simple Application").setMaster("spark://zhuan-OptiPlex-9020:7077").setJars(List("/home/zhuan/IdeaProjects/hello/out/artifacts/hello_jar/hello.jar"))
val sc = new SparkContext(conf)
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()

相关文章推荐
- 使用 IntelliJ IDEA 开发一般 Java 应用程序时配置 Allatori 进行代码混淆
- 使用IntelliJ IDEA配置Spark应用开发环境及源码阅读环境
- 使用 IntelliJ IDEA 开发 Android 应用程序时配置 Allatori 进行代码混淆
- 配置Oracle VM VirtualBox,实现内外网访问笔记,以进行spark、hadoop集群开发测试
- openfire:Openfire源代码在eclipse中的运行配置 + 与spark结合进行二次开发
- 使用IDEA进行Spark开发(一)-IDEA的配置
- Qt简介以及如何配置Qt使用VS2010进行开发
- Eclipse进行C/C++开发——Eclipse+CDT+MinGW的配置与使用详解
- 使用Eclipse进行C/C++开发——Eclipse+CDT+MinGW的配置与使用详解(1)
- Eclipse3.2下进行ArcGIS Server 9.2 Java WebADF开发手记 - 环境配置篇
- 详解如何配置Qt使用VS2010进行开发
- JavaWEB开发时FCKeditor类似office界面的ajax框架,加入后就能做界面类似office,能进行简单的文本编辑操作+配置手册
- 使用Eclipse进行C/C++开发——Eclipse+CDT+MinGW的配置与使用详解(1)
- 使用Eclipse进行C/C++开发——Eclipse+CDT+MinGW的配置与使用详解(1)
- Qt简介以及如何配置Qt使用VS2010进行开发
- Qt简介以及如何配置Qt使用VS2010进行开发
- 一步一步教你使用AgileEAS.NET基础类库进行应用开发-基础篇-ORM访问器及其配置
- 使用Eclipse进行C/C++开发——Eclipse+CDT+MinGW的配置与使用详解(2)
- vs2003 + wxWidGets进行c++开发的环境配置
- eclipse,myeclipse,Tomcat进行JSP开发配置