中文分词器安装配置
2016-09-25 20:46
197 查看
到网上下载ik analyzer包
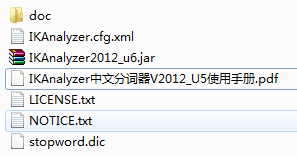
解压后得如下目录:
我们先在
1、 将IKAnalyzer-2012-4x.jar或者

2、 然后在
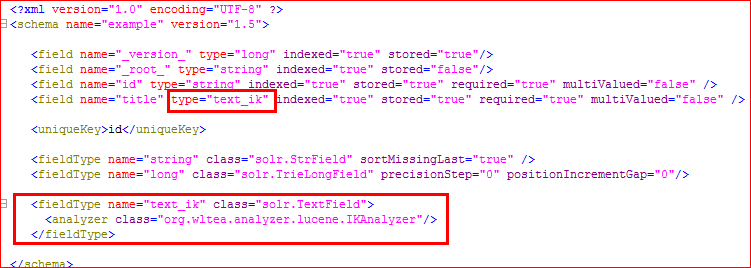
如果哪一个字段的类型是“text_ik”,该字段将进行中文分词,比如(如图),
启动solr测试
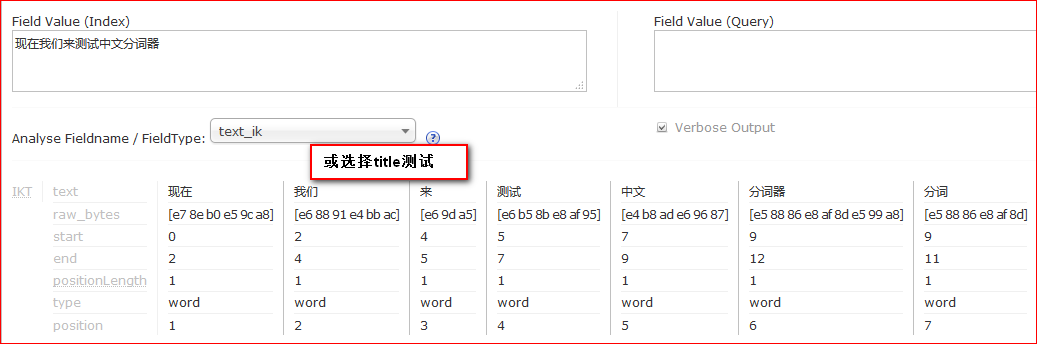
最后测试中文的时候可以选择用
download
解压后得如下目录:
我们先在
solr_home(我的
solo_home是
F:\solr-4.6.0\solr\example\solr)下新建一个lib文件夹,把上述解压后的IKAnalyzer2012FF_u1.jar文件拷贝到刚刚新建的lib文件夹中。然后把IKAnalyzer.cfg.xml和stopword.dic拷贝到F:\solr-4.6.0\solr\example\solr\collection1\conf目录下(也就是跟schema.xml同一个目录下),最后在schema.xml中增加一段配置:
1、 将IKAnalyzer-2012-4x.jar或者
IKAnalyzer2012FF_u1.jar拷贝到
example\solr-webapp\webapp\WEB-INF\lib下;
2、 然后在
example\solr\collection1\conf\schema.xml中添加
fieldType:
<fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
如果哪一个字段的类型是“text_ik”,该字段将进行中文分词,比如(如图),
title字段就可以进行中文分词,其他的字段不能使用中文分词:
启动solr测试
java -jar start.jar:
最后测试中文的时候可以选择用
text_ik(就是上述配置中fieldType name=”text_ik”定义的)测试;也可以选择
title(上述配置字段
field name="title" type="text_ik"的)测试。效果如下:

相关文章推荐
- 你不知道的全文检索---solr安装中文分词器及配置业务字段
- solr 的安装与使用、中文分词器的配置
- solr安装和配置中文分词器
- solr的安装以及配置中文分词器
- solr下配置安装中文分词器和批量导入数据
- solr安装及配置IKAnalyzer中文分词器
- Windows下面安装和配置Solr 4.9(三)支持中文分词器
- elasticsearch ik中文分词器的安装配置使用
- solr5.5.4安装、启动、添加中文分词器、配置。
- solr与中文分词器的安装配置
- pligg9.7beta搭起后HTML编辑器插件的安装——fckeditor的配置与修改变相支持中文文件名
- Wildfire(Jive Messenger)安装和中文支持配置
- NOKIA Seriers60 SDK for Jbuilder 安装配置(中文)
- [转]TeX Live 2008 安装 & 配置中文支持
- RHEL5.1安装VM TOOL及中文乱码终极解决方案[系统配置]
- Domino8安装与配置中文手册
- mplayer安装、配置、中文字幕的调整
- LaTex 安装与中文排版环境配置指南
- Debian(英文环境)下安装SCIM中文输入法以及中文显示配置