WebCrawler Java小爬爬 从入门到放弃 第三章
2016-09-24 21:59
260 查看
正则表达式:
我们已经会了最简单,也是最基础的如何提取网页内容。
接下来就是从中筛选我们想要的内容。
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表通常被用来检索、替换那些符合某个模式(规则)的文本。
对regex先进行简单的了解,推荐一个网站:
http://tool.chinaz.com/regex/
Java里封装了两个类Pattern和Matcher,用于匹配正则表达式。
建议先看下API文档,推荐个博主写的关于这两个类的说明:
http://blog.csdn.net/cclovett/article/details/12448843
我们先进行一个简单的测试:
我们选择CSDN极客头条的第一个链接:
http://www.jianshu.com/p/d0aacb6f0455
然后用正则匹配我们想要的正文。
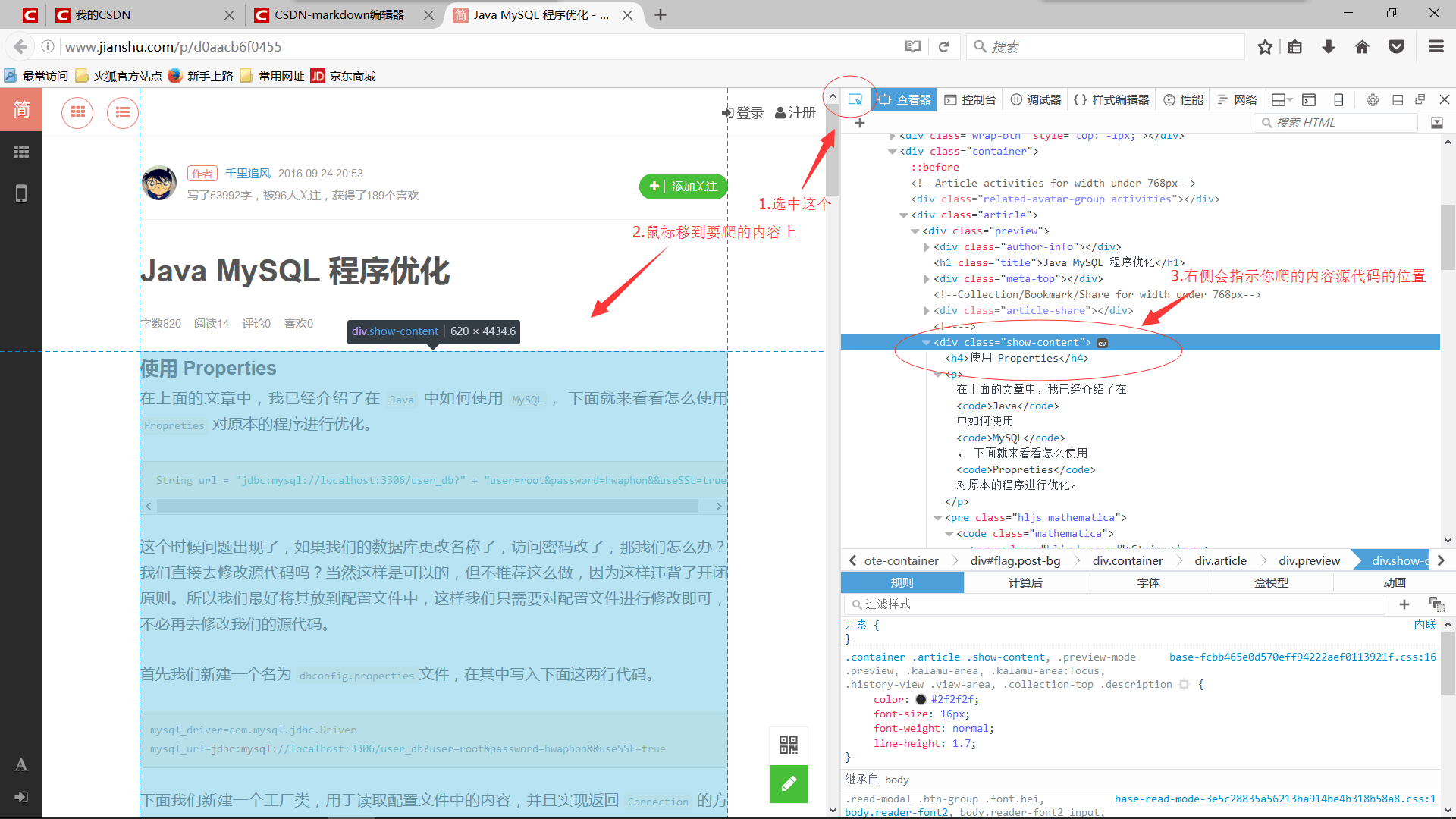
用FireFox打开链接,按F12如下图
然后敲代码 测试
测试完成。
了解下JS里的标记 有时候我们匹配的信息需要用控制符替换掉这些标记
博主十一要认真学学JS,有些地方有问题。
我们已经会了最简单,也是最基础的如何提取网页内容。
接下来就是从中筛选我们想要的内容。
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表通常被用来检索、替换那些符合某个模式(规则)的文本。
对regex先进行简单的了解,推荐一个网站:
http://tool.chinaz.com/regex/
Java里封装了两个类Pattern和Matcher,用于匹配正则表达式。
建议先看下API文档,推荐个博主写的关于这两个类的说明:
http://blog.csdn.net/cclovett/article/details/12448843
我们先进行一个简单的测试:
我们选择CSDN极客头条的第一个链接:
http://www.jianshu.com/p/d0aacb6f0455
然后用正则匹配我们想要的正文。
用FireFox打开链接,按F12如下图
然后敲代码 测试
import java.io.*;
import java.net.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class test {
public test(){
BufferedReader in = null;
URL realURL;
String urlContent = "";
try {
realURL = new URL("http://www.jianshu.com/p/d0aacb6f0455");
//获取网页链接
URLConnection connection = realURL.openConnection();
connection.connect();
//缓冲流读入
in = new BufferedReader(new InputStreamReader(
connection.getInputStream(), "UTF-8"));
String line;
//用while循环将缓冲区内容写到字符串里
while(null != (line = in.readLine())){urlContent += line;}
//进行正则匹配 正则语句: meta charset=\"(.+?)\">
Pattern p = Pattern.compile("meta charset=\"(.+?)\">");
Matcher m = p.matcher(urlContent);
m.find();
//打印当前网页字符集格式
System.out.println(realURL.toString()+" charset is " + m.group(1));
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch
4000
(IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static void main(String[] args){
new test();
}
}测试完成。
了解下JS里的标记 有时候我们匹配的信息需要用控制符替换掉这些标记
博主十一要认真学学JS,有些地方有问题。

相关文章推荐
- WebCrawler Java小爬爬 从入门到放弃 第七章
- WebCrawler Java小爬爬 从入门到放弃 第一章
- WebCrawler Java小爬爬 从入门到放弃 第五章
- WebCrawler Java小爬爬 从入门到放弃 第六章
- WebCrawler Java小爬爬 从入门到放弃 第四章
- WebCrawler Java小爬爬 从入门到放弃 第二章
- java程序员从入门到放弃资源大放送(文末附下载地址)
- Java从入门到高手到放弃
- 基于HTML5+WebSocket+JAVA的棋牌游戏开发,从入门到放弃(一)
- 《Java从入门到放弃》框架入门篇:Struts2的基本数据传递方式 推荐
- java程序员从入门到放弃资源大放送(文末附下载地址)
- 第三章:Java语言基础II 第2\3\4节 For入门(求和思想)
- 《Java从入门到放弃》框架入门篇:Struts2的常用验证方式
- Java语言入门 -- 第三章 Java程序设计基础
- java从入门到放弃
- 《Java从入门到放弃》框架入门篇:Struts2的基本访问方式
- javaweb从入门到不放弃
- Java入门 第二季第三章 继承
- Java入门 第一季第三章 常用的运算符
- 基于HTML5+WebSocket+JAVA的棋牌游戏开发,从入门到放弃(三)