MongoDB的数据复制和数据切片
2016-09-23 15:10
363 查看
MongoDB简介
MongoDB由C++开发,是NoSQL中比较接近关系型数据库的一种。MongoDB中的数据以类似于json的格式存储,性能非常优越,且支持大量的数据存储。但是MongoDB不支持事务性的操作,使得其适用场景受到限制。
MongoDB副本集
MongoDB的数据复制有两种类型:
1)master/slave
2)replica set
第一种为类似于MySQL的主从复制模型,第二种为副本集复制方式。现在主要应用的为副本集复制模型。结构图如下:

一个副本集即为服务于同一数据集的多个MongoDB实例,其中一个为主节点,其余的都为从节点。主节点上能够完成读写操作,从节点仅能用于读操作。主节点需要记录所有改变数据库状态的操作,这些记录保存在oplog中,这个文件存储在local数据库,各个从节点通过此oplog来复制数据并应用于本地,保持本地的数据与主节点的一致。oplog具有幂等性,即无论执行几次其结果一致,这个比mysql的二进制日志更好用。
集群中的各节点还会通过传递心跳信息来检测各自的健康状况。当主节点故障时,多个从节点会触发一次新的选举操作,并选举其中的一个成为新的主节点(通常谁的优先级更高,谁就是新的主节点),心跳信息默认每2秒传递一次。

实现过程
副本集的实现至少需要三个节点,且应该为奇数个节点,可以使用arbiter(仲裁节点)来参与选举。
实验环境:
主节点:192.168.1.132
从节点:192.168.1.139,192.168.1.140
1)安装配置MongoDB
在
24000
各个节点上安装MongoDB服务器端需要的rpm包(安装包的下载地址:http://downloads-distro.mongodb.org/repo/redhat/os/):
配置文件信息:
replSet指定副本集的名称,这个至关重要,这个决定了对应的每一个节点加入的是哪一个副本集的集群。
replIndexPrefetch指定副本集的索引预取,如果有预取功能可以让复制过程更为高效,有3个值none,_id_only,all。none:不预取任何索引,_id_only:预取ID索引,all:预取所有索引。这个预取操作只能定义在从节点上。
在各节点上创建数据存放目录,然后启动服务:
2)配置集群的成员
查看集群信息(此时没有任何节点)
添加集群成员,首先配置cfg定义集群信息,然后执行rs.initiate(cfg)完成节点的添加。在定义集群时,需要指定每一个节点的属性信息,例如_id,host。还有很多属性字段,常见的有priority,votes,arbiterOnly..... 具体的信息可以参考官方网站http://docs.mongodb.org/manual/reference/command/replSetGetConfig/#replsetgetconfig-output。
查看各节点的状态信息:
在创建副本集时,有3种方式:
1、db.runCommand( { replSetInitiate : <config_object> } )
2、rs.initiate(<config_object>)
3、rs.initiate() #先在其中一个节点上初始化,再通过rs.add添加另外的节点
这里采用的是第二种方式,<config_object>即为上述中的cfg文件,对该文件的修改使用replSetInitiate命令。
3)访问测试
在主节点上添加数据(192.168.1.132):
此时在从节点上访问数据会报如下错误:
执行rs.slaveOk()后,数据才可读。
当主节点故障时,从节点会重新投票选举出主节点,继续提供服务,避免单点故障。
主节点上关闭服务:
从节点上查看状态信息:
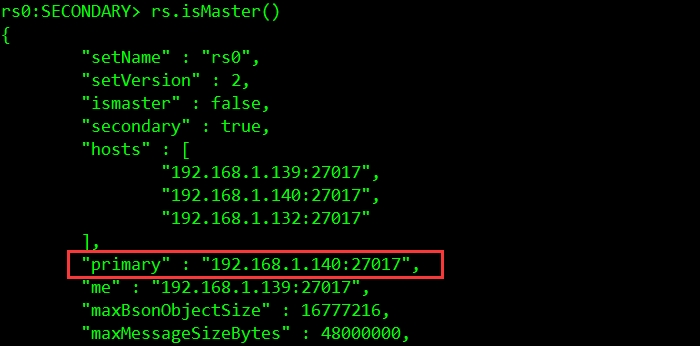
可以看到原来的主节点已经下线(health为0),重新选举的主节点为192.168.1.139。可以通过rs.isMaster()查看当前节点是否为主节点。
4)添加一个从节点
数据库运行一段时间后,可能需要再次添加节点来分散压力。通过rs.add命令添加从节点。添加完成后,该节点需要和主节点同步数据,同步过程有3个步骤:
1、初始同步(initial sync)
2、回滚后追赶(post-rollback catch-up)
3、切分块迁移(sharding chunk migrations)
添加从节点(在主节点上):
查看状态:
执行rs.slaveOk()后,即可实现访问。
5)更改某个节点的优先级
若某个从节点的硬件配置不错,可以对应的调高其优先级,使其在选举过程中能够优先被选举为主节点。例如设置第3个节点的优先级为2(默认均为1),过程如下:
此时会立刻进行选举,优先级最高的为主节点,如下图所示:
MongoDB数据分片
随着数据集的扩大和吞吐量的提升,单个MongoDB服务器可能在cpu,内存或IO这些资源上出现瓶颈,这是需要对MongoDB进行扩展,比较经济的方式是水平扩展,将数据集分布到多个节点上来分散访问压力。这里的每个节点也称作分片,每个分片都是一个独立的数据库。所有的分片组合在一起才是一个完整的数据库。
MongoDB的分片框架中有3个角色:
1)Query Routers:路由
2)Config servers:元数据服务器
3)Shards:数据节点
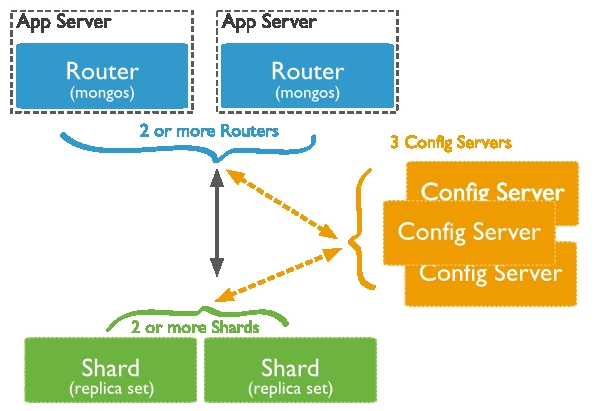
工作机制:Query Routers用于接收用户的请求,将请求路由到对应的分片上(shards)执行,然后将结果返回给客户端。Config servers存储服务器集群的元数据,Query Routers通过使用这些元数据将请求定位至特定的shard节点。Shards节点存储数据,为了提供高可用性和数据一致性,每个shard都可以是一个副本集。在生产环境中,为了避免单点故障,Query
Routers和Config servers往往有多个节点。
实现过程
实验环境:
Config server:192.168.1.106
Query Routers:192.168.1.131
Shared:192.168.1.138,192.168.1.127
1)配置config server
在192.168.1.106上更改配置文件信息:
配置完成后启动服务:

可以看到对应的服务监听在27019上。
2)配置Query
Routers
Query Routers节点只需要安装mongodb-org-mongos即可,无需安装其他的软甲包。
默认情况下,mongos监听于27017端口,在启动mongos是需要指定config服务器的地址。
启动mongos:
也可以直接编辑配置文件:
1)注释dbpath指令
2)添加configdb指令,并指定config服务器的地址
3)启动mongos,命令:mongos -f /etc/mongod.conf
3)配置shard节点
shard(数据节点)的配置与配置mongodb一致,如果不是副本集,把以下两项注销。
在两个shard节点上启动mongod服务:
4)向分区集群中添加各shard服务器或副本集
连接mongos节点,添加shard。由于在mongos节点上仅安装了mongos的包,没有mongo命令,可以在其他节点上使用mongo --host 来连接。
添加shard节点:
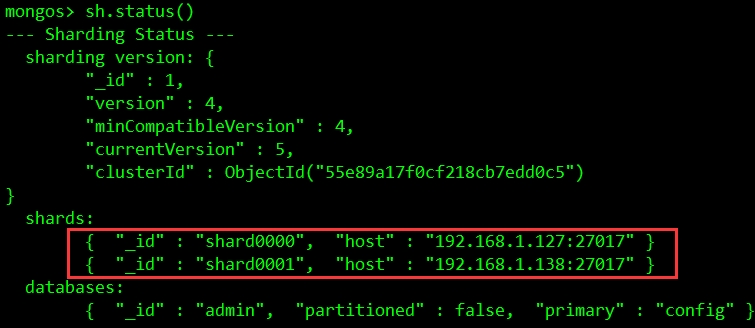
可以看到节点已经添加成功,只是上面还没有数据,没有进行分片。
5)启用sharding功能
启用指定数据库的sharding功能:
最后一行显示student_db数据库的partition为true,已支持数据分片功能。
指定需要分片的Collection及索引:
查看集群的状态信息:
可以看到数据已经分别存储在不同的shard上。
若需要分片时,数据已经存在,则需要对collection中的某一字段先创建索引,然后才能够分片。以上是MongoDB的简单应用。.................^_^
转自:http://ljbaby.blog.51cto.com/10002758/1696180
MongoDB由C++开发,是NoSQL中比较接近关系型数据库的一种。MongoDB中的数据以类似于json的格式存储,性能非常优越,且支持大量的数据存储。但是MongoDB不支持事务性的操作,使得其适用场景受到限制。
MongoDB副本集
MongoDB的数据复制有两种类型:
1)master/slave
2)replica set
第一种为类似于MySQL的主从复制模型,第二种为副本集复制方式。现在主要应用的为副本集复制模型。结构图如下:
一个副本集即为服务于同一数据集的多个MongoDB实例,其中一个为主节点,其余的都为从节点。主节点上能够完成读写操作,从节点仅能用于读操作。主节点需要记录所有改变数据库状态的操作,这些记录保存在oplog中,这个文件存储在local数据库,各个从节点通过此oplog来复制数据并应用于本地,保持本地的数据与主节点的一致。oplog具有幂等性,即无论执行几次其结果一致,这个比mysql的二进制日志更好用。
集群中的各节点还会通过传递心跳信息来检测各自的健康状况。当主节点故障时,多个从节点会触发一次新的选举操作,并选举其中的一个成为新的主节点(通常谁的优先级更高,谁就是新的主节点),心跳信息默认每2秒传递一次。
实现过程
副本集的实现至少需要三个节点,且应该为奇数个节点,可以使用arbiter(仲裁节点)来参与选举。
实验环境:
主节点:192.168.1.132
从节点:192.168.1.139,192.168.1.140
1)安装配置MongoDB
在
24000
各个节点上安装MongoDB服务器端需要的rpm包(安装包的下载地址:http://downloads-distro.mongodb.org/repo/redhat/os/):
replIndexPrefetch指定副本集的索引预取,如果有预取功能可以让复制过程更为高效,有3个值none,_id_only,all。none:不预取任何索引,_id_only:预取ID索引,all:预取所有索引。这个预取操作只能定义在从节点上。
在各节点上创建数据存放目录,然后启动服务:
查看集群信息(此时没有任何节点)
1、db.runCommand( { replSetInitiate : <config_object> } )
2、rs.initiate(<config_object>)
3、rs.initiate() #先在其中一个节点上初始化,再通过rs.add添加另外的节点
这里采用的是第二种方式,<config_object>即为上述中的cfg文件,对该文件的修改使用replSetInitiate命令。
3)访问测试
在主节点上添加数据(192.168.1.132):
主节点上关闭服务:
4)添加一个从节点
数据库运行一段时间后,可能需要再次添加节点来分散压力。通过rs.add命令添加从节点。添加完成后,该节点需要和主节点同步数据,同步过程有3个步骤:
1、初始同步(initial sync)
2、回滚后追赶(post-rollback catch-up)
3、切分块迁移(sharding chunk migrations)
添加从节点(在主节点上):
5)更改某个节点的优先级
若某个从节点的硬件配置不错,可以对应的调高其优先级,使其在选举过程中能够优先被选举为主节点。例如设置第3个节点的优先级为2(默认均为1),过程如下:
MongoDB数据分片
随着数据集的扩大和吞吐量的提升,单个MongoDB服务器可能在cpu,内存或IO这些资源上出现瓶颈,这是需要对MongoDB进行扩展,比较经济的方式是水平扩展,将数据集分布到多个节点上来分散访问压力。这里的每个节点也称作分片,每个分片都是一个独立的数据库。所有的分片组合在一起才是一个完整的数据库。
MongoDB的分片框架中有3个角色:
1)Query Routers:路由
2)Config servers:元数据服务器
3)Shards:数据节点
工作机制:Query Routers用于接收用户的请求,将请求路由到对应的分片上(shards)执行,然后将结果返回给客户端。Config servers存储服务器集群的元数据,Query Routers通过使用这些元数据将请求定位至特定的shard节点。Shards节点存储数据,为了提供高可用性和数据一致性,每个shard都可以是一个副本集。在生产环境中,为了避免单点故障,Query
Routers和Config servers往往有多个节点。
实现过程
实验环境:
Config server:192.168.1.106
Query Routers:192.168.1.131
Shared:192.168.1.138,192.168.1.127
1)配置config server
在192.168.1.106上更改配置文件信息:
可以看到对应的服务监听在27019上。
2)配置Query
Routers
Query Routers节点只需要安装mongodb-org-mongos即可,无需安装其他的软甲包。
启动mongos:
1)注释dbpath指令
2)添加configdb指令,并指定config服务器的地址
3)启动mongos,命令:mongos -f /etc/mongod.conf
3)配置shard节点
shard(数据节点)的配置与配置mongodb一致,如果不是副本集,把以下两项注销。
连接mongos节点,添加shard。由于在mongos节点上仅安装了mongos的包,没有mongo命令,可以在其他节点上使用mongo --host 来连接。
可以看到节点已经添加成功,只是上面还没有数据,没有进行分片。
5)启用sharding功能
启用指定数据库的sharding功能:
指定需要分片的Collection及索引:
若需要分片时,数据已经存在,则需要对collection中的某一字段先创建索引,然后才能够分片。以上是MongoDB的简单应用。.................^_^
转自:http://ljbaby.blog.51cto.com/10002758/1696180

相关文章推荐
- 利用Mongodb的复制集搭建高可用分片,Replica Sets + Sharding的搭建过程
- [置顶] MongoDB基础部分及实现(二)
- 基于MongoDB 2dSphere索引查找最近的点
- LINUX 线上安装 MongoDB 亲测可用!
- guide for node.js and express, jade, mongodb
- MongoDB与NodeJS
- MongoDB 3.0 安全权限访问控制
- mongodb-drill for sql
- mongodb副本集和分片部署
- Mongodb学习总结(1)——常用NoSql数据库比较
- Mongodb学习总结(1)——常用NoSql数据库比较
- mongoDB的查询与修改
- mongoengine|mongodb|flask_sqlalchemy简单使用对比
- MongoDB使用总结
- Mongodb创建collection
- 在SPRING DATA MONGODB中使用聚合统计查询
- mongodb的查询语句学习摘要
- mongodb 集合设置过期时间
- Linux下定时切割Mongodb数据库日志并删除指定天数前的日志记录
- Spring中Mongodb的java实体类映射