008 在大数据中,关于native包的编译步骤
2016-09-22 15:35
267 查看
一。问题的由来:

二。解决问题的方法(所有的操作在root下完成):
1.前期需要的环境,下面的已经在伪分布式中配置好,不再重复
配置好jdk
配置好hadoop
2.上传还需要包

apache-maven-3.0.5-bin.tar.gz和protobuf-2.5.0.tar.gz
maven是项目管理与项目构建自动化工具,在这之前必须保证安装jdk。
protobuf是一种数据化方式。用于通信和存储的序列化,结构化的协议。
3.解压maven到指定的目录
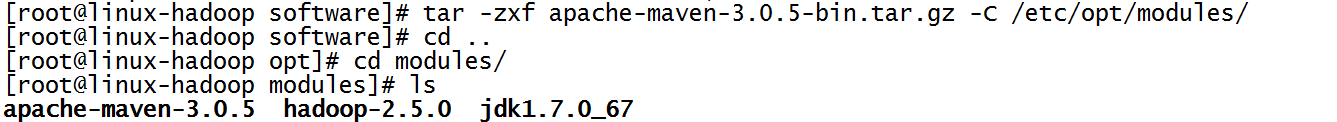
4.配置maven的环境变量和路径(需要在root下)

5.source一下,使环境变量尽快生效

6.退出

7.重新登录,检验mvn

8.安装gcc/gcc-c++

9.make
make是Linux下的一款程序自动维护工具,配合makefile的使用,就能够根据程序中模块的修改情况,自动判断应该对那些模块重新编译,从而保证软件是由最新的模 块构成。
10.解压安装protobuf
关于什么是protobuf:http://blog.csdn.net/caisini_vc/article/details/5599468

11.指定protobuf安装的位置

12.make
大量的编译后的结果太多。。。。。

13.make install

14. 配置环境变量

15.source一下,使配置环境尽快的生效

16.exit后,重新登录,然后检验protoc是否可以使用

17.下载安装cmake ,openssl-devel ,ncurses-devel
CMake是一个跨平台的安装(编译)工具,可以用简单的语句来描述所有平台的安装(编译过程)。
openssl-devel包是第三方软件开发时使用的Lib包,是用于编译的时候连接的库之类的文件。

18.在编译源码包前,首先进入hadoop-2.5.0-src目录,即是需要解压安装hadoop-2.5.0-src

19.编译

20.剩下就是等待即可。
二。解决问题的方法(所有的操作在root下完成):
1.前期需要的环境,下面的已经在伪分布式中配置好,不再重复
配置好jdk
配置好hadoop
2.上传还需要包
apache-maven-3.0.5-bin.tar.gz和protobuf-2.5.0.tar.gz
maven是项目管理与项目构建自动化工具,在这之前必须保证安装jdk。
protobuf是一种数据化方式。用于通信和存储的序列化,结构化的协议。
3.解压maven到指定的目录
4.配置maven的环境变量和路径(需要在root下)
5.source一下,使环境变量尽快生效
6.退出
7.重新登录,检验mvn
8.安装gcc/gcc-c++
9.make
make是Linux下的一款程序自动维护工具,配合makefile的使用,就能够根据程序中模块的修改情况,自动判断应该对那些模块重新编译,从而保证软件是由最新的模 块构成。
10.解压安装protobuf
关于什么是protobuf:http://blog.csdn.net/caisini_vc/article/details/5599468
11.指定protobuf安装的位置
12.make
大量的编译后的结果太多。。。。。
13.make install
14. 配置环境变量
15.source一下,使配置环境尽快的生效
16.exit后,重新登录,然后检验protoc是否可以使用
17.下载安装cmake ,openssl-devel ,ncurses-devel
CMake是一个跨平台的安装(编译)工具,可以用简单的语句来描述所有平台的安装(编译过程)。
openssl-devel包是第三方软件开发时使用的Lib包,是用于编译的时候连接的库之类的文件。
18.在编译源码包前,首先进入hadoop-2.5.0-src目录,即是需要解压安装hadoop-2.5.0-src
19.编译
20.剩下就是等待即可。

相关文章推荐
- Installation error: INSTALL_FAILED_MEDIA_UNAVAILABLE
- quartz集群报错but has failed to stop it. This is very likely to create a memory leak.
- Container With Most Water水箱问题
- connect_timeout interactive_timeout net_read_timeout net_write_timeout wait_timeout
- leetcode 70. Climbing Stairs
- 大数据可视化之矢量切片的生成及渲染
- 503 Service Temporarily Unavailable
- 大数据权威戴文波特:当人机共存成定局,认识两者极限便是决策者的义务
- LightOj1366 - Pair of Touching Circles(求矩形内圆的对数)
- 基于N源码的Activity的启动过程分析
- 视线追逐
- SUBMAIL云通讯平台——如何避免邮件进入垃圾箱的方法
- hdu 5759 2016 Multi-University Training Contest 3 Gardener Bo 解题报告
- 使用AIDL实现进程间的通信之复杂类型传递
- 50款大数据分析神器
- 基于机器学习方法的POI品类推荐算法
- 219. Contains Duplicate II 超时
- 条件变量pthread_cond_wait(&g_cond,&mutex);
- sigwait 函数的使用
- 深入理解主函数main()的输入参数及返回值问题