【Oracle 11g】为何加了索引反而查询变慢
2016-09-21 00:26
351 查看
这里我们探讨数据在磁盘上的物理组织 对索引的开销造成的影响。
一般来讲,主键值彼此接近的行的物理位置也会靠在一起。(表会很自然地按主键顺序聚簇)
在某种情况下,使用这个索引可能很不错,但是在另外一种情况下它却不能很好的工作。从生产系统转储数据并加载到开发系统时,也应该考虑这点。看完了本篇文章的实验,你就能回答这类问题:”为什么在这台机器上运行的完全不同?难道它们不一样吗?“是的,它们确实不一样的,因为数据在磁盘上的物理组织不一样。
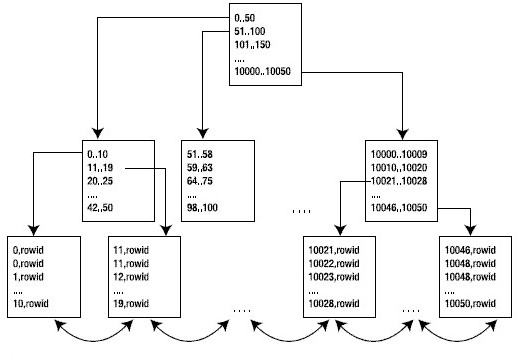
本文讨论的是最长用的B*树索引。下图是典型的B*树索引布局
创建一张表
有插入数据,注意,x是有顺序的。
然后对表创建主键,主键选择x列
这里我们使用oracle标准内置包DBMS_METADATA,查询这个表的定义,可以看到创建的表中有这段(CONSTRAINT “COLOCATED_PK” PRIMARY KEY (“X”) USING INDEX), 默认使用我们创建的主键作为索引。
统计表的统计信息.(关于如下的函数,可以参考Oracle官方文档)
在创建一张表,数据同表colocated。
创建主键
对表colocated进行统计信息收集
从上可以看到,
“2900 consistent gets”获取数据执行了2900次I/O
已用时间: 00: 00: 30.11
从上可以看到,
“21359 consistent gets”获取数据执行了21359次I/O
已用时间: 00: 00: 32.04
补充说明:
关于CLUSTERING_FACTOR ,该数值越接近BLOCKS ,则说明rows越有序;
反之,如果该数值越接近NUM_ROWS , 则说明rows越无序。
(This defines how ordered the rows are in the index. If CLUSTERING_FACTOR approaches the number of blocks in the table, the rows are ordered. If it approaches the number of rows in the table, the rows are randomly ordered. In such a case (clustering factor near the number of rows), it is unlikely that index entries in the same leaf block will point to rows in the same data blocks. 参看原文)
2.重建该表。
这个测试说明在某些情况下,全表扫描快于使用索引查询。
可以看到block大小为8k。
下面看看表中每行占用空间大小
可以看到,随机的某一行占用总计77个字节。(number类型占用空间很少是因为其按照有效数字,正负号,小数位来存储的。所以有效数字越多,占用空间越大)
所以,可以看到,每个块(block)中可以存储多行数据。所以,如果数组是随机存储的,那么如果通过索引访问,则很多块会被重复读取,导致访问变慢。
block是oracle中最小的逻辑存储单元。如图(引用自oracle官网)

本文参考《Oracle_Database_9i10g11g编程艺术深入数据库体系结构》第2版,Thomas Kyte著,苏金国 王小振等译,327~405页。
一般来讲,主键值彼此接近的行的物理位置也会靠在一起。(表会很自然地按主键顺序聚簇)
在某种情况下,使用这个索引可能很不错,但是在另外一种情况下它却不能很好的工作。从生产系统转储数据并加载到开发系统时,也应该考虑这点。看完了本篇文章的实验,你就能回答这类问题:”为什么在这台机器上运行的完全不同?难道它们不一样吗?“是的,它们确实不一样的,因为数据在磁盘上的物理组织不一样。
本文讨论的是最长用的B*树索引。下图是典型的B*树索引布局
实验一、探究磁盘上的物理组织对索引的影响
本文使用数据库是oracle11g,分析或查询工具是sqlplus。可以看到sqlplus将每一行都查询出来了,所以统计的时间是准确的。如果使用toad或者pl/sql developer这种工具,首次只会返回部分数据,在这种客户端看到的时间是不准确的。创建一张表
SQL> create table colocated(x int, y varchar2(80)); 表已创建。
有插入数据,注意,x是有顺序的。
SQL> begin 2 for i in 1..100000 3 loop 4 insert into colocated(x,y) 5 values(i, rpad(dbms_random.random, 75, '*')); 6 end loop; 7 end; 8 /
然后对表创建主键,主键选择x列
SQL> alter table colocated 2 add constraint colocated_pk 3 primary key(x); 表已更改。
这里我们使用oracle标准内置包DBMS_METADATA,查询这个表的定义,可以看到创建的表中有这段(CONSTRAINT “COLOCATED_PK” PRIMARY KEY (“X”) USING INDEX), 默认使用我们创建的主键作为索引。
SQL> SET LONG 5000;
SQL> select dbms_metadata.get_ddl('TABLE', 'COLOCATED') FROM DUAL;
DBMS_METADATA.GET_DDL('TABLE','COLOCATED')
--------------------------------------------------------------------------------
CREATE TABLE "SYS"."COLOCATED"
( "X" NUMBER(*,0),
"Y" VARCHAR2(80),
CONSTRAINT "COLOCATED_PK" PRIMARY KEY ("X")
USING INDEX PCTFREE 10 INITRANS 2 MAXTRANS 255 COMPUTE STATISTICS
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DE
FAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM" ENABLE
) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING
DBMS_METADATA.GET_DDL('TABLE','COLOCATED')
--------------------------------------------------------------------------------
STORAGE(INITIAL 65536 NEXT 1048576 MINEXTENTS 1 MAXEXTENTS 2147483645
PCTINCREASE 0 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT FLASH_CACHE DE
FAULT CELL_FLASH_CACHE DEFAULT)
TABLESPACE "SYSTEM"统计表的统计信息.(关于如下的函数,可以参考Oracle官方文档)
SQL> begin dbms_stats.gather_table_stats(user, 'COLOCATED'); 2 end; 3 / PL/SQL 过程已成功完成。
在创建一张表,数据同表colocated。
SQL> create table disorganized 2 as 3 select x,y 4 from colocated 5 order by y; 表已创建。
创建主键
SQL> alter table disorganized 2 add constraint disorganized_pk 3 primary key(x); 表已更改。
对表colocated进行统计信息收集
SQL> begin dbms_stats.gather_table_stats(user, 'DISORGANIZED'); 2 END; 3 / PL/SQL 过程已成功完成。
第一步,看看有序的物理组织对使用索引进行查询的影响
下面来看看这两个存有相同数据的表的查询性能,打印结果在这里不再展示,只展示查询语句和执行计划以及统计结果。SQL> set autotrace on; SQL> set timing on; SQL> select * from colocated where x between 20000 and 40000;
已用时间: 00: 00: 30.11
执行计划
----------------------------------------------------------
Plan hash value: 1550765370
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20002 | 1582K| 282 (0)| 00:00:04 |
| 1 | TABLE ACCESS BY INDEX ROWID| COLOCATED | 20002 | 1582K| 282 (0)| 00:00:04 |
|* 2 | INDEX RANGE SCAN | COLOCATED_PK | 20002 | | 43 (0)| 00:00:01 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("X">=20000 AND "X"<=40000)
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
2900 consistent gets
0 physical reads
0 redo size
1893673 bytes sent via SQL*Net to client
15078 bytes received via SQL*Net from client
1335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
20001 rows processed从上可以看到,
“2900 consistent gets”获取数据执行了2900次I/O
已用时间: 00: 00: 30.11
第二步,看看无序的物理组织对使用索引进行的查询产生的影响
来看看对照组SQL> select/*+ index ( disorganized disorganized_pk) */ * from disorganized
2 where x between 20000 and 40000;
已用时间: 00: 00: 32.04
执行计划
----------------------------------------------------------
Plan hash value: 2594580634
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20002 | 1582K| 20039(1)| 00:04:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| DISORGANIZED | 20002 | 1582K| 20039(1)| 00:04:01 |
|* 2 | INDEX RANGE SCAN | DISORGANIZED_PK | 20002 | | 43(0)| 00:00:01 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("X">=20000 AND "X"<=40000)
统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
21359 consistent gets
0 physical reads
0 redo size
1893673 bytes sent via SQL*Net to client
15078 bytes received via SQL*Net from client
1335 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
20001 rows processed从上可以看到,
“21359 consistent gets”获取数据执行了21359次I/O
已用时间: 00: 00: 32.04
SQL> select a.index_name,
2 b.num_rows,
3 b.blocks,
4 a.clustering_factor
5 from user_indexes a, user_tables b
6 where index_name in ('COLOCATED_PK', 'DISORGANIZED_PK')
7 and a.table_name = b.table_name
INDEX_NAME NUM_ROWS BLOCKS CLUSTERING_FACTOR
------------------------------ ---------- ---------- -----------------
COLOCATED_PK 100000 1191 1190
DISORGANIZED_PK 100000 1191 99930结果分析:
上述两句SQL都走了索引,表中存储的数据都相同,查询的结果集也相同,但是查询时间差别好大。对于物理上共同放置的数据(COLOCATED),查询时间大幅下降。在某种情况下,使用这个索引可能很不错,但是在另外一种情况下它却不能很好的工作。补充说明:
关于CLUSTERING_FACTOR ,该数值越接近BLOCKS ,则说明rows越有序;
反之,如果该数值越接近NUM_ROWS , 则说明rows越无序。
(This defines how ordered the rows are in the index. If CLUSTERING_FACTOR approaches the number of blocks in the table, the rows are ordered. If it approaches the number of rows in the table, the rows are randomly ordered. In such a case (clustering factor near the number of rows), it is unlikely that index entries in the same leaf block will point to rows in the same data blocks. 参看原文)
如何减小CLUSTERING_FACTOR 值呢?解决方法:
1.使用索引组织表(index organized table, IOT)。存储在堆中的表示无组织的,IOT中的数据则是按主键存储和排序。2.重建该表。
实验二、全表扫描比使用索引更快的例子
再来个测试SQL> select * from disorganized where x between 20000 and 40000
已用时间: 00: 00: 31.49
执行计划
----------------------------------------------------------
Plan hash value: 2727546897
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 20002 | 1582K| 326 (1)| 00:00:04|
|* 1 | TABLE ACCESS FULL| DISORGANIZED | 20002 | 1582K| 326 (1)| 00:00:04 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("X"<=40000 AND "X">=20000)
统计信息
----------------------------------------------------------
218 recursive calls
0 db block gets
2550 consistent gets
1195 physical reads
0 redo size
1813725 bytes sent via SQL*Net to client
15079 bytes received via SQL*Net from client
1335 SQL*Net roundtrips to/from client
4 sorts (memory)
0 sorts (disk)
20001 rows processed这个测试说明在某些情况下,全表扫描快于使用索引查询。
其它补充:
先看看我的数据库中block的大小SQL> show parameter db_block_size NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ db_block_size integer 8192
可以看到block大小为8k。
下面看看表中每行占用空间大小
SQL> select vsize(x),vsize(y) from colocated where rownum=1; VSIZE(X) VSIZE(Y) ---------- ---------- 2 75
可以看到,随机的某一行占用总计77个字节。(number类型占用空间很少是因为其按照有效数字,正负号,小数位来存储的。所以有效数字越多,占用空间越大)
所以,可以看到,每个块(block)中可以存储多行数据。所以,如果数组是随机存储的,那么如果通过索引访问,则很多块会被重复读取,导致访问变慢。
block是oracle中最小的逻辑存储单元。如图(引用自oracle官网)
本文参考《Oracle_Database_9i10g11g编程艺术深入数据库体系结构》第2版,Thomas Kyte著,苏金国 王小振等译,327~405页。

相关文章推荐
- Oracle中的index学习 ---理解索引为何物,为什么会使查询变快
- oracle_为何在查询中索引未被使用
- oracle使用了索引但是查询性能没有改善(oracle的索引陷阱)
- oracle使用了索引但是查询性能没有改善(oracle的索引陷阱) 【转】
- Oracle查询指定索引提高查询效率【转】
- 关于oracle 11g中的索引.
- 如何在oracle中查询所有用户表的表名、主键名称、索引、外键等
- Oracle查询指定索引提高查询效率
- Oracle中通过位图索引提高查询效率
- Oracle 11g最佳20大特性之一-闪回版本查询
- web地图信息格网索引-----基于google map api和oracle查询的生活地图
- Oracle问题小记五:服务启动-索引-子查询-分页存储过程
- ORACLE查询或删除时指定使用索引的写法
- Oracle查询指定索引提高查询效率
- 使用索引的误区之一:没有使用复合索引的前导列导致查询不使用索引——oracle
- 如何在oracle中查询所有用户表的表名、主键名称、索引、外键等
- oracle使用了索引但是查询性能没有改善(oracle的索引陷阱)
- 如何在oracle中查询所有用户表的表名、主键名称、索引、外键等
- 查询oracle表的信息(表,字段,约束,索引)
- Oracle优化你的查询--关于避免索引隐式失效