python 学习之爬虫练习
2016-09-19 13:01
417 查看
通过学习python,写两个简单的爬虫,没用线程,本地抓取速度还不错,有些瑕疵就是抓的图片有些显示不出来,代码做个笔记记录下:
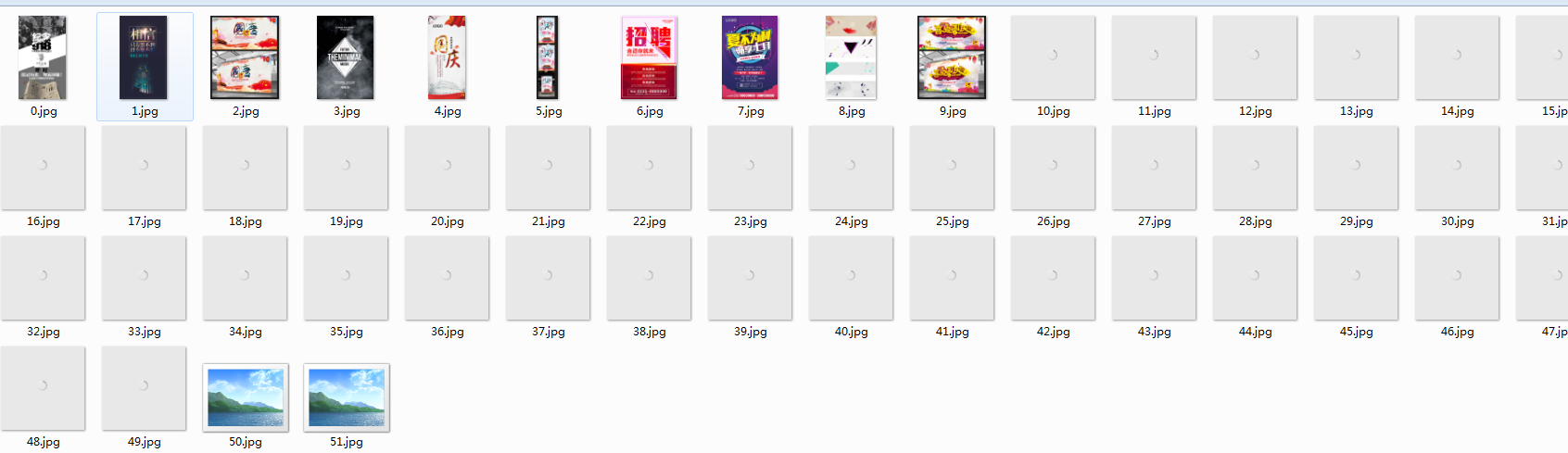
最终的结果如下图:
根据上面的初步代码,优化后加强版的爬虫代码,对于链接的状态异常的抛出异常后在继续执行程序。代码如下:
# -*- coding:utf-8 -*-
import re
import urllib.request
import os
url = "http://www.58pic.com/yuanchuang/0/day-"
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read().decode('gbk')
return html
def getImg(html,num):
reg = r'src="(.*?)" '
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
os.mkdir(r"G:\collect/%d" % num)
filePath = r"G:\collect/%d/" % num
for imgurl in imglist:
f=open(filePath+str(x)+".jpg",'wb')
req=urllib.request.urlopen(imgurl)
buf=req.read()
f.write(buf)
x+=1
for i in range(1,10):
getUrl = url+"%d.html" % i
print(getUrl)
html = getHtml(getUrl)
#print(html)
print(getImg(html,i))最终的结果如下图:
根据上面的初步代码,优化后加强版的爬虫代码,对于链接的状态异常的抛出异常后在继续执行程序。代码如下:
# -*- coding:utf-8 -*-
import re
import urllib.request
import os
url = "http://www.58pic.com/psd/"
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read().decode('gbk')
return html
def getImg(html,num):
reg = r'src="(.+?\.jpg)" class="show-area-pic" id="show-area-pic" alt="(.*?)"'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
print(imglist)
filePath = r"F:\Py/collect/%d/" % num
isCreate = os.path.exists(filePath)
if isCreate == False :
os.mkdir(r"F:\Py/collect/%d" % num)
for img in imglist:
title = img[1]
f=open(filePath+title+".jpg",'wb')
req=urllib.request.urlopen(img[0])
buf=req.read()
f.write(buf)
for i in range(22797263,22797666):
getUrl = url+"%d.html" % i
#status = urllib.request.urlopen(getUrl).code
try:
html = getHtml(getUrl)
#print(html)
getImg(html,i)
except urllib.request.URLError as e:
print(e.code)
print(e.reason)

相关文章推荐
- Python的学习笔记DAY8---爬虫练习之煎蛋网妹子图爬虫
- 【极客学院】-python学习笔记-4-单线程爬虫 (提交表单抓取信息,实战练习)
- PYTHON爬虫学习——urllib库之Debuglog与URLError实战练习
- python中文编码转换 分类: python基础学习 python 小练习 2013-10-11 17:22 331人阅读 评论(0) 收藏
- python数据持久存储:pickle模块的基本使用 分类: python python基础学习 python 小练习 2013-06-17 14:41 209人阅读 评论(0) 收藏
- Python学习总结(二)----python的练习方法
- Python学习总结(二)----python的练习方法
- Learn Python The Hard Way学习(24) - 更多的练习
- 学习python爬虫
- 学习Python之爬虫1
- python基础学习-7(简单爬虫)
- 依次读取文件中的一个字符 分类: python基础学习 python 小练习 2013-08-22 11:14 289人阅读 评论(0) 收藏
- Getting Started Spidering a Site使用Chilkat(python)练习的一个爬虫(from :http://www.example-code.com)
- Python学习笔记: 第五章课后习题练习
- 使用os.popen/commands.getoutput查询指定端口号的服务 分类: python 小练习 open()文件读写 python基础学习 2013-09-17 17:49 798人阅读 评论(0) 收藏
- 猜数字 分类: python 小练习 python基础学习 2013-06-20 15:16 160人阅读 评论(0) 收藏
- python语法学习练习1
- python语法学习练习1
- Python学习笔记 第二部分 - 正则表达式 与 爬虫小实例(抓取豆瓣电影中评分大于等于8分的影片)
- fileinput模块 分类: python基础学习 python 小练习 python Module 2013-08-15 17:18 417人阅读 评论(0) 收藏