MCMC算法—MH算法的Python实现(一)
2016-09-14 16:47
651 查看
针对离散数据概率分布的MCMC算法python实现
对于mcmc算法,如何选择状态转移矩阵对实验结果是否有影响,设计下面几组实验输入为p=[0.9,0.05,0.05],取q为[1/3,1/3,1/3],输出10000000个样本,观察样本的概率分布,代码如下:
#coding=utf-8
'''
Created on 2016年9月14日
基本MCMC算法以及M-H算法的python实现
@author: whz
p:输入的概率分布,离散情况采用元素为概率值的数组表示
N:认为迭代N次马尔可夫链收敛
Nlmax:马尔可夫链收敛后又取的服从p分布的样本数
isMH:是否采用MH算法,默认为True
'''
from __future__ import division
import matplotlib.pyplot as plt
import matplotlib as mpl
import numpy as np
from array import array
def mcmc(p,N=10000,Nlmax=10000,isMH=True):
A = np.array([[1.0 / len(p) for x in range(len(p))] for y in range(len(p))], dtype=np.float64)
X0 = np.random.randint(len(p))
count = 0
samplecount = 0
L = array("d",[X0])
l = array("d")
while True:
X = L[samplecount]
cur = np.argmax(np.random.multinomial(1,A[X]))
count += 1
if isMH:
a = (p[cur]*A[cur][X])/(p[X]*A[X][cur])
alpha = min(a,1)
else:
alpha = p[cur]*A[cur][X]
u = np.random.uniform(0,1)
if u<alpha:
samplecount += 1
L.append(cur)
if count>N:
l.append(cur)
if len(l)>=Nlmax:
break
else:
continue
La = np.frombuffer(L)
la = np.frombuffer(l)
return La,la
def count(q,n):
L = array("d")
l1 = array("d")
l2 = array("d")
for e in q:
L.append(e)
for e in range(n):
l1.append(L.count(e))
for e in l1:
l2.append(e/sum(l1))
return l1,l2
p = np.array([0.9,0.05,0.05])
a = mcmc(p,Nlmax=10000000)[1]
l1 = ['state%d'% x for x in range(len(p))]
plt.pie(count(a,len(p))[0],labels=l1,labeldistance=0.3,autopct='%1.2f%%')
plt.title("sampling")
plt.show()图1可见该样本收敛于0.7691,0.1154,0.1155,与我们的输入的差距相差甚远
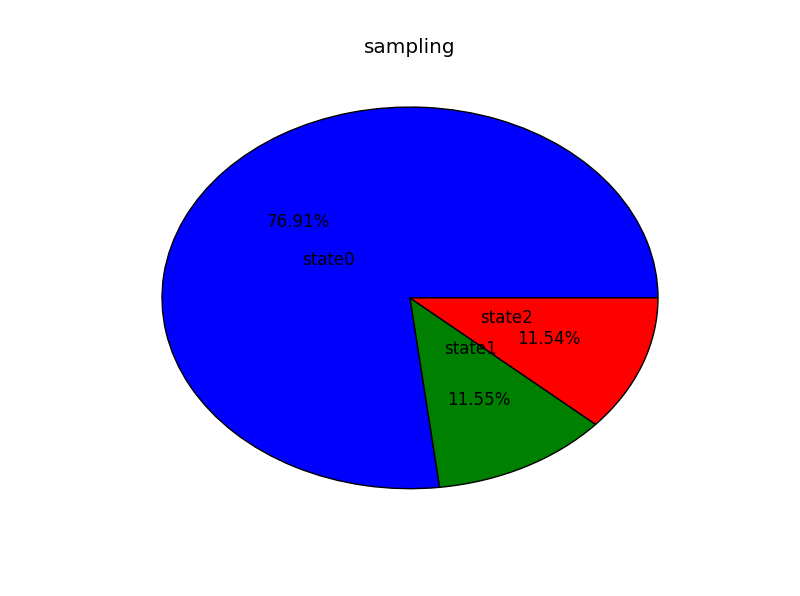
2. 把输入更改成p=[0.8,0.1,0.1],以同样的迭代次数,输出同样数量样本可得到
图2也是同样有很大差距,可以用方差来衡量差距
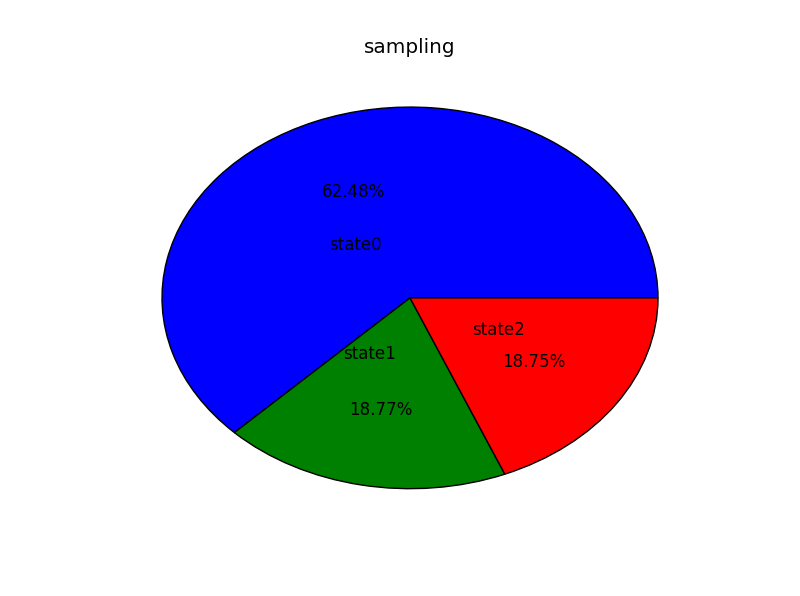
3. 把输入更改成p=[0.6,0.2,0.2],以同样的迭代次数,输出同样数量样本可得到
图3同样还是有着很大的差距

4. 最后把输入更改成p=[1/3,1/3,1/3],以同样的迭代次数,输出同样数量样本可得到
图4这次准确率却很高
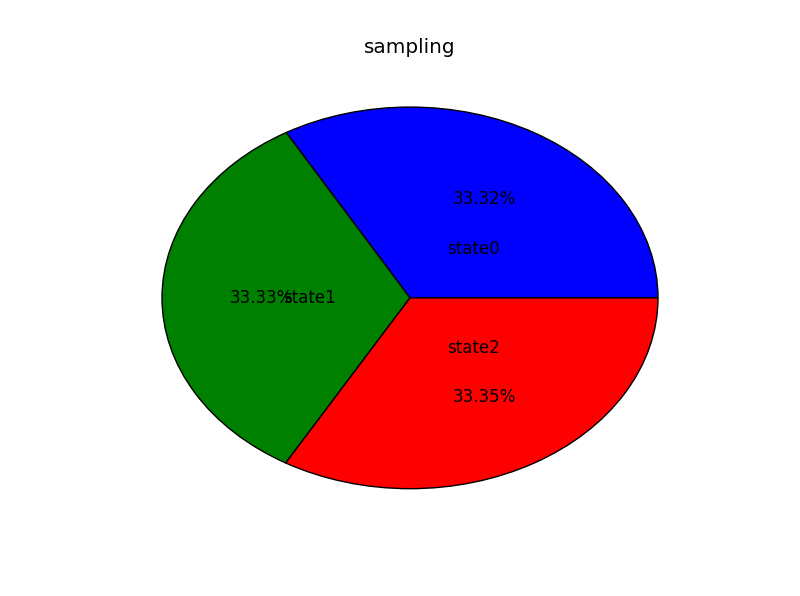
由以上四组实验,猜测使构造的转移矩阵的每一行与输入的分布p(x)相等时,可以达到较高的精度,所以,如下更改代码:
#coding=utf-8
'''
Created on 2016年9月15日
基本MCMC算法以及M-H算法的python实现(离散数据的情况)
@author: whz
p:输入的概率分布,离散情况采用元素为概率值的数组表示
构造的转移矩阵每一行都与输入的p相同
N:认为迭代N次马尔可夫链收敛
Nlmax:马尔可夫链收敛后又取的服从p分布的样本数
isMH:是否采用MH算法,默认为True
'''
from __future__ import division
import matplotlib.pyplot as plt
import numpy as np
from array import array
def mcmc(p,N=10000,Nlmax=10000,isMH=True):
A = np.array([p for y in range(len(p))], dtype=np.float64)
X0 = np.random.randint(len(p))
count = 0
samplecount = 0
L = array("d",[X0])
l = array("d")
while True:
X = L[samplecount]
cur = np.argmax(np.random.multinomial(1,A[X]))
count += 1
if isMH:
a = (p[cur]*A[cur][X])/(p[X]*A[X][cur])
alpha = min(a,1)
else:
alpha = p[cur]*A[cur][X]
u = np.random.uniform(0,1)
if u<alpha:
samplecount += 1
L.append(cur)
if count>N:
l.append(cur)
if len(l)>=Nlmax:
break
else:
continue
La = np.frombuffer(L)
la = np.frombuffer(l)
return La,la
def count(q,n):
L = array("d")
l1 = array("d")
l2 = array("d")
for e in q:
L.append(e)
for e in range(n):
l1.append(L.count(e))
for e in l1:
l2.append(e/sum(l1))
return l1,l2
if __name__ == '__main__':
p = np.array([0.9,0.05,0.05])
a = mcmc(p)[1]
l1 = ['state%d'% x for x in range(len(p))]
plt.pie(count(a,len(p))[0],labels=l1,labeldistance=0.3,autopct='%1.2f%%')
plt.title("sampling")
plt.show()得到如下:
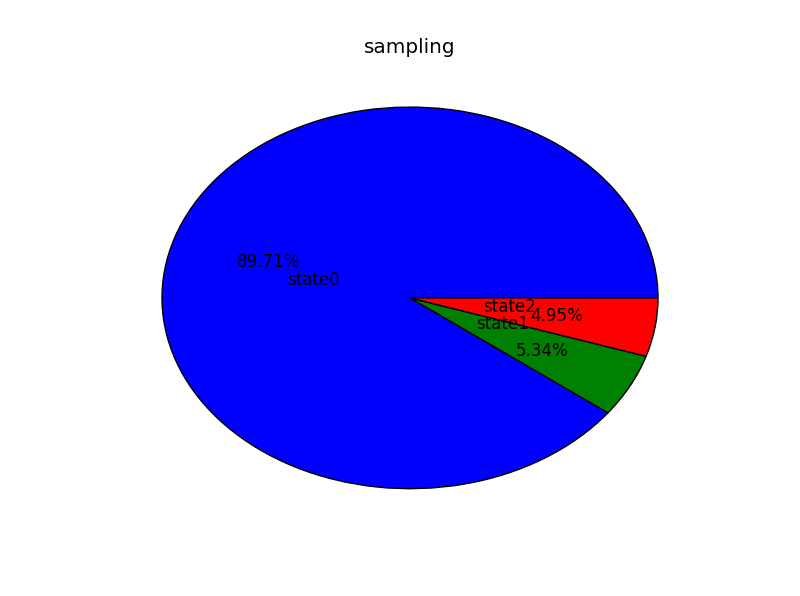
与图1相比,很明显,图5准确率提高很多,依照同样程序,分别更改p,同样也可以得到对应于图2、3、4的准确率高的结果。
结论
要将状态转移矩阵的每一行都设计成与输入概率分布相一致,这样该算法才能得到更好的结果。该算法该实现的适用范围:输入概率分布为离散的,有限的。
思考:虽然无限的离散型的应该也能按照上述的模式计算,但是对于无穷矩阵的计算,本小白还没研究,等着日后思考;而对于连续分布,则没有所谓的概率分布,而替代以概率密度,而且,由于在实现过程中使用了随机数生成,所以可以轻易通过变换随机数的方式生成的连续性分布的样本如果使用mcmc算法未免有点大炮轰蚊子,但若是考虑那些无法显示表出概率密度的连续型分布,我实在是还没想到好的解决办法,待后续解决。

相关文章推荐
- 在python种实现类的静态方法
- python实现的AES双向对称加密解密与用法分析
- 发布一个用Python实现的“法语动词变位工具”
- ·python·用生成器和迭代器实现自己的xrange
- 用Python实现ORM
- 用Python实现语音合成
- 发布一个用Python实现的“法语动词变位工具”
- python中实现Single模式
- Python实现的在线保持
- 用Python实现数据库编程
- 用Python实现GB与BIG5码的转换
- IronPython0.9.4发布了 —— 实现静态编译并提供官方Tutorial
- Python使用Com组件及Access查询分析类实现
- Python实现ASP+ACCESS注入,不用SOCKET
- [python]如何清屏?也就是实现clear?
- C#下的webservcie 实现代码和 在vc和python下的调用实现(原创)
- [转载]Python实现ASP+ACCESS注入的工具源代码
- [Python]Python中实现一个时间(日期)型加几个月的运算
- 用Python实现去掉文章中特定的段落
- 基本A*算法python实现