Scrapy爬取makepolo网站数据深入详解
2016-09-09 23:02
253 查看
题记
之前对爬虫只是概念了解多,实战少。知道网上流行的有号称免费的八爪鱼等(实际导出数据收费)。大致知道,所有爬虫要实现爬取网页信息,需要定义正则匹配规则。
这次,项目紧急,才知道“书到用时方恨少”,有限的理论知识是远远不够的。
首先,Google搜索了不同语言实现的开源爬虫,C++、Java、Python、Ruby等。由于C++写的过于庞大,Java代码不太熟。
Python虽也不熟悉,但看起来不费劲,并且,Python在爬虫领域有很大优势,值得深入研究。
其次,对比选型Python爬虫开源实现,主要包括:Scrapy、PyRailgun等。
最后,定选型。对比国内写的PyRailgun和Scrapy,不论从易用性、Git关注度、广泛性。Scrapy都有明显优势,研究的人非常多。
因此,本文从Scrapy爬取makepolo企业数据说起。
一、Scrapy爬虫使用概括步骤如下
1、创建新的Scrapy工程;2、定义需要提取的Items;
3、写爬虫Spider用于爬取设定的站点,提取Items;
4、写Item Pipeline(管道),用来存储提取的Items。
二、Scrapy爬虫使用详解
前提:
1)爬虫目标网站:http://company.makepolo.com/shandong/2)待爬取内容:以列表形式呈现的公司名称。
3)设备:centos 6.8
4)安装Scrapy参考步骤(目前最好用、快捷版本):
https://www.douban.com/group/topic/51645204/
第1步:创建马可波罗网站爬虫工程。
[root@yang scrapy_testing]# scrapy startproject scrapy_makepoloNew Scrapy project ‘scrapy_makepolo’, using template directory ‘/usr/local/lib/python2.7/site-packages/scrapy/templates/project’, created in:
/home/yang/spider_ycy/scrapy_testing/scrapy_makepolo
You can start your first spider with:
cd scrapy_makepolo
scrapy genspider example example.com
以上内容是提示信息,也就是说创建完毕以后,会形成如下树结构的工程路径:
[root@yang scrapy_testing]# tree scrapy_makepolo/
scrapy_makepolo/
├── scrapy.cfg ‘#工程的配置文件
└── scrapy_makepolo ‘#工程的Python模型,需要在此处导入代码
├── init.py
├── init.pyc
├── init.pyo
├── items.py ‘#工程 Items文件
├── pipelines.py ‘#工程 管道文件
├── settings.py ‘#工程 配置文件
├── settings.pyc
└── spiders ‘#放置爬虫的路径
├── example.py
├── init.py
├── init.pyc
└── init.pyo
第2步:定义你的Item
在items.py文件里定义在抓取网页内容中抽象出来的数据结构的定义,由于这里需要公司名称一个字段,所以,定义的Item结构如下:[root@laoyang scrapy_makepolo]# cat items.py
'# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html from scrapy import Item,Field class ScrapyMakepoloItem(Item): # define the fields for your item here like: # name = scrapy.Field() companyName = Field() #公司名称 pass You have new mail in /var/spool/mail/root
第3步:定义爬虫规则等
1.Spiders是定义的类,scrapy用于爬取指定域名或者域名组信息。2.需要定义用于下载的初始化URL列表,需要定义跟踪列表和解析页面内容以提取items的规则。
3.为了创建Spider,你需要定义scrapy.Spider子类,并需要定义如下的一些属性值:
1)name:用于标识Spider。该名称必须确保唯一性。
2)start_urls:爬虫需要爬取的起点Urls列表。
3)parse()方法:Spider方法,每个页面下载的Response对象是该方法的唯一参数。
该方法作用:解析response数据,并提取爬取的数据。
路径如下:
/home/yangcy/spider_ycy/scrapy_testing/scrapy_makepolo/scrapy_makepolo/spiders [root@laoyang spiders]# ls -al 总用量 24 drwxr-xr-x 2 root root 4096 9月 8 14:20 . drwxr-xr-x 3 root root 4096 9月 8 14:35 .. -rw-r--r-- 1 root root 240 9月 8 14:20 example.py -rw-r--r-- 1 root root 161 9月 7 15:50 __init__.py -rw-r--r-- 1 root root 177 9月 8 14:20 __init__.pyc -rw-r--r-- 1 root root 177 9月 7 16:04 __init__.pyo
将example.py改名为 ScrapyMakepolo.py,并做如下的规则定义。
[root@laoyang spiders]# cat ScrapyMakepolo.py
# -*- coding: utf-8 -*-
from scrapy.spiders import Spider, Rule
from scrapy.selector import Selector
from scrapy_makepolo.items import ScrapyMakepoloItem
from scrapy.linkextractors import LinkExtractor
import re
from scrapy.spiders import CrawlSpider
class ScrapyMakepoloSpider(CrawlSpider):
name = "MakepoloSpider"
allowed_domains = ["company.makepolo.com"]
start_urls = [
"http://company.makepolo.com/shandong/1",
]
rules = (
Rule(LinkExtractor(allow=('shandong/([\d]+)', ),),callback='parse_item',follow=True),
)
def parse_item(self, response):
sel = response.selector
posts = sel.xpath('//div[@class="colist"]/div[@class="colist_item"]')
items = []
for p in posts:
item = ScrapyMakepoloItem()
companyName = p.xpath('h2[@class="colist_item_title"]/a/text()').extract_first()
item["companyName"] = (companyName is not None and [companyName.encode("utf-8")] or [""])[0]
items.append(item)
return items第4步: 写Item Pipeline(管道),用来存储提取的Items。
将结果输出到item.json文件中。[root@laoyang scrapy_makepolo]# cat pipelines.py # -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import json class ScrapyMakepoloPipeline(object): def __init__(self): self.file = open("item.json", "w+") def process_item(self, item, spider): record = json.dumps(dict(item), ensure_ascii=False)+"\n" self.file.write(record) return item
第5步:修改配置setting.py.
主要修改: ITEM_PIPELINES 为pipelines.py 中定义的管道接口类ScrapyMakepoloPipeline。[root@laoyang scrapy_makepolo]# cat settings.py # -*- coding: utf-8 -*- # Scrapy settings for scrapy_makepolo project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # http://doc.scrapy.org/en/latest/topics/settings.html # http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html # http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html BOT_NAME = 'scrapy_makepolo' SPIDER_MODULES = ['scrapy_makepolo.spiders'] NEWSPIDER_MODULE = 'scrapy_makepolo.spiders' # Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'scrapy_makepolo.pipelines.ScrapyMakepoloPipeline': 1, }
至此,所有配置完毕。
第6步:执行。
scrapy crawl MakepoloSpider其中:
MakepoloSpider为ScrapyMakepolo.py中的name定义。
执行结果如下所示:
[root@laoyang scrapy_makepolo]# tail -f item.json
{"companyName": "章丘市宇龙机械有限公司"}
{"companyName": "济南松岳机器有限责任公司"}
{"companyName": "山东双一集团销售部"}
{"companyName": "山东景盛泉酒业"}
{"companyName": "郓城皮家烧鸡有限公司"}
{"companyName": "胶州市煜德手机通讯服务部"}
{"companyName": "宁津县天福建筑新材料有限公司"}
{"companyName": "聊城市建兴金属材料有限公司"}
{"companyName": "山东益母草有限公司"}
..........去重后结果数:
[root@laoyang scrapy_cnblogs-master]# cat sd_mkbl_uniq.txt | wc -l 9521
三、scrapy爬取马可波罗网站思路详解:
步骤1:进入到马可波罗山东企业首页:http://company.makepolo.com/shandong/
步骤2:查看其页面结构,知道其支持通过下一页按钮进入下一页。
第1页链接:http://company.makepolo.com/shandong/1第2页链接:http://company.makepolo.com/shandong/2
……
第1000页链接:http://company.makepolo.com/shandong/1000
由此看出网站以序号作为参数来表示页数,这样看来爬虫的规则就比较简单实现。
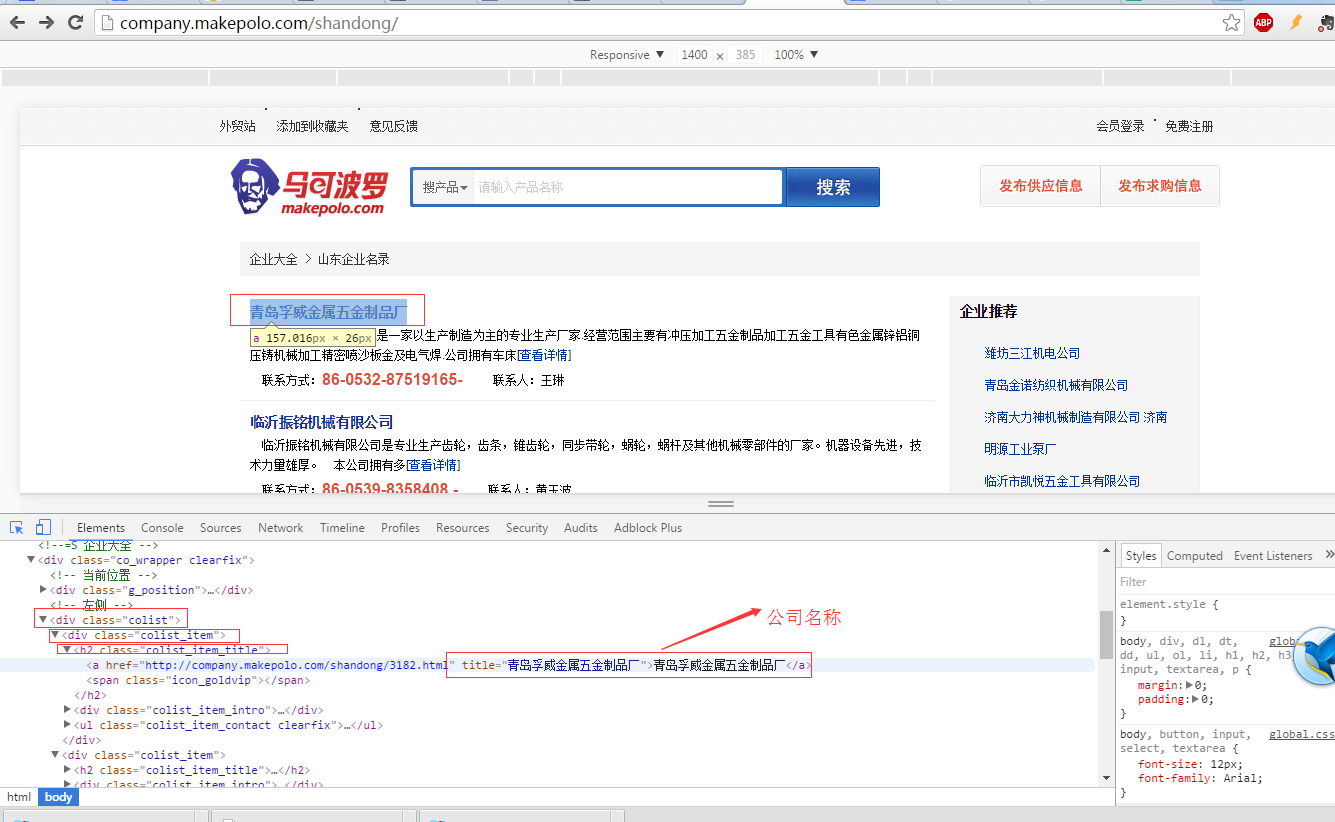
步骤3:定义爬虫规则。
‘shandong/([\d]+)’ ,这个就是爬虫的规则,数字为对应数字的页面,这样无论有多少页都可以通过遍历规则遍历到。1)如果页面数量很少时:可以在start_urls列表中,将要爬取的页面都列出来,
2)如果页面数量很多时:要继承CrawlSpider爬虫类,使用Spider就不行了。(该问题排查了30分钟以上,才解决)
在规则定义(rules)时,如果要对爬取的网页进行处理,而不是简单的需要Url列表堆砌。
这时,需要定义一个回调函数,在爬取到符合条件的网页时调用,并且设置follow=Ture,定义如下:
rules = (
Rule(LinkExtractor(allow=('shandong/([\d]+)', ),),callback='parse_item',follow=True),
)四、小结
想融汇贯通Scrapy进行网络数据分析,个人感觉:网页数据爬取正则标示,xpath解析非常重要。这也是我接下来要深入研究的重点。也想进一步就其他网站做进一步深入爬取、分析。
参考
[1]http://doc.scrapy.org/en/latest/intro/tutorial.htmlhttp://www.cnblogs.com/rwxwsblog/p/4557123.html
[2]学习python:https://learnpythonthehardway.org/book/
[3]http://www.pycoding.com/2016/03/14/scrapy-04.html
2016-9-9 pm23:03 思于家中床前
作者:铭毅天下
转载请标明出处,原文地址:
http://blog.csdn.net/laoyang360/article/details/52491147
如果感觉本文对您有帮助,请点击‘顶’支持一下,您的支持是我坚持写作最大的动力,谢谢!

相关文章推荐
- 详解Data Binding - 通过几个简单示例深入了解WinForm数据绑定特性
- 深入Memcache的Session数据的多服务器共享详解
- 深入理解计算机系统(3.3)---数据传送(或者说复制)指令详解
- 使用Scrapy爬取一个网站的数据
- 减少网站跳转时间,增强网站数据安全——HSTS 详解
- 【译文】详解Data Binding - 通过几个简单示例深入了解WinForm数据绑定特性
- kafka数据同步Elasticsearch深入详解
- Python3 大型网络爬虫实战 004 — scrapy 大型静态商城网站爬虫项目编写及数据写入数据库实战 — 实战:爬取淘宝
- 网站分析数据的三种收集方式详解
- Scrapy爬取电商网站京东奶粉商品价格数据-附各种问题解决
- 深入php数据采集的详解
- 一个网站的诞生02--用Scrapy抓取数据
- 网站分析数据(即用户行为数据)的三种收集方式详解
- 网站分析数据收集方式详解
- OpenGL深入探索——OpenGL/GLSL数据传递小记(3.x) 【包含UBO详解】
- 深入理解计算机系统(3.3)---数据传送(或者说复制)指令详解
- 深入php数据采集的详解
- iOS CoreData详解(六)深入理解数据模型
- 深入网络协议来理解数据传输三(http协议详解)
- Scrapy爬虫抓取网站数据