解析storm的KafkaSpout
2016-09-09 10:57
435 查看
KafkaSpout的源码
KafkaSpout在配置使用时必须传入一个SpoutConfig,而这个SpoutConfig里卖弄保存有全部的kafka的配置:
从代码里可以看到SpoutConfig继承了KafkaConfig,因为strom需要将代码分发到Supervisor因此实现了Serializable序列化接口,可以将代码发送到各个Supervisor节点上!
附上Topology
附上storm确定开始位置的代码
最后附上一张kafk保存在zk中的json信息截图
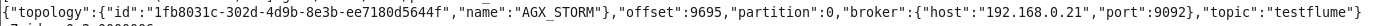
package storm.kafka;
import backtype.storm.Config;
import backtype.storm.metric.api.IMetric;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import kafka.message.Message;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import storm.kafka.PartitionManager.KafkaMessageId;
import java.util.*;
// TODO: need to add blacklisting
// TODO: need to make a best effort to not re-emit messages if don't have to
public class KafkaSpout extends BaseRichSpout {
public static class MessageAndRealOffset {
public Message msg;
public long offset;
public MessageAndRealOffset(Message msg, long offset) {
this.msg = msg;
this.offset = offset;
}
}
static enum EmitState {
EMITTED_MORE_LEFT,
EMITTED_END,
NO_EMITTED
}
public static final Logger LOG = LoggerFactory.getLogger(KafkaSpout.class);
String _uuid = UUID.randomUUID().toString();
SpoutConfig _spoutConfig;
SpoutOutputCollector _collector;
PartitionCoordinator _coordinator;
DynamicPartitionConnections _connections;
ZkState _state;
long _lastUpdateMs = 0;
int _currPartitionIndex = 0;
public KafkaSpout(SpoutConfig spoutConf) {
_spoutConfig = spoutConf;
}
@Override
public void open(Map conf, final TopologyContext context, final SpoutOutputCollector collector) {
_collector = collector;
Map stateConf = new HashMap(conf);
List<String> zkServers = _spoutConfig.zkServers;
if (zkServers == null) {
zkServers = (List<String>) conf.get(Config.STORM_ZOOKEEPER_SERVERS);
}
Integer zkPort = _spoutConfig.zkPort;
if (zkPort == null) {
zkPort = ((Number) conf.get(Config.STORM_ZOOKEEPER_PORT)).intValue();
}
stateConf.put(Config.TRANSACTIONAL_ZOOKEEPER_SERVERS, zkServers);
stateConf.put(Config.TRANSACTIONAL_ZOOKEEPER_PORT, zkPort);
stateConf.put(Config.TRANSACTIONAL_ZOOKEEPER_ROOT, _spoutConfig.zkRoot);
_state = new ZkState(stateConf);
_connections = new DynamicPartitionConnections(_spoutConfig, KafkaUtils.makeBrokerReader(conf, _spoutConfig));
// using TransactionalState like this is a hack
int totalTasks = context.getComponentTasks(context.getThisComponentId()).size();
if (_spoutConfig.hosts instanceof StaticHosts) {
_coordinator = new StaticCoordinator(_connections, conf, _spoutConfig, _state, context.getThisTaskIndex(), totalTasks, _uuid);
} else {
_coordinator = new ZkCoordinator(_connections, conf, _spoutConfig, _state, context.getThisTaskIndex(), totalTasks, _uuid);
}
context.registerMetric("kafkaOffset", new IMetric() {
KafkaUtils.KafkaOffsetMetric _kafkaOffsetMetric = new KafkaUtils.KafkaOffsetMetric(_spoutConfig.topic, _connections);
@Override
public Object getValueAndReset() {
List<PartitionManager> pms = _coordinator.getMyManagedPartitions();
Set<Partition> latestPartitions = new HashSet();
for (PartitionManager pm : pms) {
latestPartitions.add(pm.getPartition());
}
_kafkaOffsetMetric.refreshPartitions(latestPartitions);
for (PartitionManager pm : pms) {
_kafkaOffsetMetric.setLatestEmittedOffset(pm.getPartition(), pm.lastCompletedOffset());
}
return _kafkaOffsetMetric.getValueAndReset();
}
}, _spoutConfig.metricsTimeBucketSizeInSecs);
context.registerMetric("kafkaPartition", new IMetric() {
@Override
public Object getValueAndReset() {
List<PartitionManager> pms = _coordinator.getMyManagedPartitions();
Map concatMetricsDataMaps = new HashMap();
for (PartitionManager pm : pms) {
concatMetricsDataMaps.putAll(pm.getMetricsDataMap());
}
return concatMetricsDataMaps;
}
}, _spoutConfig.metricsTimeBucketSizeInSecs);
}
@Override
public void close() {
_state.close();
}
@Override
public void nextTuple() {
List<PartitionManager> managers = _coordinator.getMyManagedPartitions();
for (int i = 0; i < managers.size(); i++) {
try {
// in case the number of managers decreased
_currPartitionIndex = _currPartitionIndex % managers.size();
EmitState state = managers.get(_currPartitionIndex).next(_collector);
if (state != EmitState.EMITTED_MORE_LEFT) {
_currPartitionIndex = (_currPartitionIndex + 1) % managers.size();
}
if (state != EmitState.NO_EMITTED) {
break;
}
} catch (FailedFetchException e) {
LOG.warn("Fetch failed", e);
_coordinator.refresh();
}
}
long now = System.currentTimeMillis();
if ((now - _lastUpdateMs) > _spoutConfig.stateUpdateIntervalMs) {
commit();
}
}
@Override
public void ack(Object msgId) {
KafkaMessageId id = (KafkaMessageId) msgId;
PartitionManager m = _coordinator.getManager(id.partition);
if (m != null) {
m.ack(id.offset);
}
}
@Override
public void fail(Object msgId) {
KafkaMessageId id = (KafkaMessageId) msgId;
PartitionManager m = _coordinator.getManager(id.partition);
if (m != null) {
m.fail(id.offset);
}
}
@Override
public void deactivate() {
commit();
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(_spoutConfig.scheme.getOutputFields());
}
private void commit() {
_lastUpdateMs = System.currentTimeMillis();
for (PartitionManager manager : _coordinator.getMyManagedPartitions()) {
manager.commit();
}
}
}KafkaSpout在配置使用时必须传入一个SpoutConfig,而这个SpoutConfig里卖弄保存有全部的kafka的配置:
package storm.kafka;
import java.io.Serializable;
import java.util.List;
public class SpoutConfig extends KafkaConfig implements Serializable {
public List<String> zkServers = null;//记录配置的消费的zk节点信息
public Integer zkPort = null;//zk的端口
public String zkRoot = null;//保存kafka消费信息的节点位置
public String id = null;//当前spout的消费组名称,如果多个spout名称一样,将共享消费进度,否则将不共享消费进度
// setting for how often to save the current kafka offset to ZooKeeper
public long stateUpdateIntervalMs = 2000; //设置线程多久将消费进度保存到zk上
// Exponential back-off retry settings. These are used when retrying messages after a bolt
// calls OutputCollector.fail().
public long retryInitialDelayMs = 0; //设置发送boult中初始化的时间,0为没限制
public double retryDelayMultiplier = 1.0;
public long retryDelayMaxMs = 60 * 1000;//发送到boult后超过多长时间为失败
public SpoutConfig(BrokerHosts hosts, String topic, String zkRoot, String id) {
super(hosts, topic);
this.zkRoot = zkRoot;
this.id = id;
}
}从代码里可以看到SpoutConfig继承了KafkaConfig,因为strom需要将代码分发到Supervisor因此实现了Serializable序列化接口,可以将代码发送到各个Supervisor节点上!
package storm.kafka;
import backtype.storm.spout.MultiScheme;
import backtype.storm.spout.RawMultiScheme;
import java.io.Serializable;
public class KafkaConfig implements Serializable {
public final BrokerHosts hosts;//设置kafka从哪里获取相关的配置信息
public final String topic;//从哪个topic开始消费
public final String clientId;//设置客户端标识
public int fetchSizeBytes = 1024 * 1024;//发给Kafka的每个FetchRequest中,用此指定想要的response中总的消息的大小
public int socketTimeoutMs = 10000;//设置的超时时间
public int fetchMaxWait = 10000;//设置的在broker无消息时的等待时间
public int bufferSizeBytes = 1024 * 1024;//SimpleConsumer所使用的SocketChannel的读缓冲区大小
public MultiScheme scheme = new RawMultiScheme();//设置从服务器读取的byte[]流反序列化方式
public boolean ignoreZkOffsets = false;//是否强制从Kafka中offset最小的开始读起
public long startOffsetTime = kafka.api.OffsetRequest.EarliestTime();//从哪里的offset开始读取消息,默认从消息的最前端开始,有两种方式可选
public long maxOffsetBehind = Long.MAX_VALUE;//KafkaSpout读取的进度与目标进度相差多少,相差太多,Spout会丢弃中间的消息
public boolean useStartOffsetTimeIfOffsetOutOfRange = true;//如果所请求的offset对应的消息在Kafka中不存在,是否使用startOffsetTime
public int metricsTimeBucketSizeInSecs = 60;//多长时间统计一次消息
public KafkaConfig(BrokerHosts hosts, String topic) {
this(hosts, topic, kafka.api.OffsetRequest.DefaultClientId());
}
public KafkaConfig(BrokerHosts hosts, String topic, String clientId) {
this.hosts = hosts;
this.topic = topic;
this.clientId = clientId;
}
}附上Topology
package test;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import storm.kafka.BrokerHosts;
import storm.kafka.KafkaSpout;
import storm.kafka.SpoutConfig;
import storm.kafka.StringScheme;
import storm.kafka.ZkHosts;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
public class TestMain {
public static void main(String[] args) throws Exception {
Config conf = new Config();
conf.setDebug(false);//关闭调试
String zks = "192.168.0.11:2181";//设置zk的地址
String topic = "testflume";//消费的topic名称
String zkRoot = "/kafka"; // 消费信息保存在zk的地址
String id = "test";//客户端的ID
BrokerHosts brokerHosts = new ZkHosts(zks, "/brokers");//kafka和zk整合时设置的kafka根路径
SpoutConfig spoutConf = new SpoutConfig(brokerHosts, topic, zkRoot, id);
spoutConf.scheme = new SchemeAsMultiScheme(new StringScheme());
spoutConf.ignoreZkOffsets = false;
// spoutConf.startOffsetTime = kafka.api.OffsetRequest.LatestTime();//从最新消息的开始读取
spoutConf.startOffsetTime = kafka.api.OffsetRequest.EarliestTime();//从最旧的消息开始读取
spoutConf.zkPort = 2181;//设置zk的端口
List<String> servers = new ArrayList<>();
servers.add("192.168.0.11");
spoutConf.zkServers = servers;//设置zk的地址
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("log-reader", new KafkaSpout(spoutConf));//设置spout的名称
builder.setBolt("bolt1", new Bolt1(), 2).shuffleGrouping("log-reader");//设置bolt的名称和分组的字段
//提交任务
if (args != null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopologyWithProgressBar("AGX", conf,
builder.createTopology());
} else {
conf.setMaxTaskParallelism(3);
conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("AGX_STORM", conf, builder.createTopology());
Thread.sleep(100000000000l);
cluster.shutdown();
}
}
/**
* 对kafka发来的数据进行第一次处理
*
* @author hasee
*
*/
public static class Bolt1 implements IRichBolt {
OutputCollector _collector;
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
_collector = collector;
}
public void execute(Tuple input) {
try {
String msg = input.getString(0);
System.out.println("开始消费消息:" + msg);
_collector.ack(input);
} catch (Exception e) {
e.printStackTrace();
} finally {
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "click", "browse"));
}
@Override
public void cleanup() {
// TODO Auto-generated method stub
}
@Override
public Map<String, Object> getComponentConfiguration() {
// TODO Auto-generated method stub
return null;
}
}
}附上storm确定开始位置的代码
package storm.kafka;
import backtype.storm.Config;
import backtype.storm.metric.api.CombinedMetric;
import backtype.storm.metric.api.CountMetric;
import backtype.storm.metric.api.MeanReducer;
import backtype.storm.metric.api.ReducedMetric;
import backtype.storm.spout.SpoutOutputCollector;
import com.google.common.collect.ImmutableMap;
import kafka.javaapi.consumer.SimpleConsumer;
import kafka.javaapi.message.ByteBufferMessageSet;
import kafka.message.MessageAndOffset;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import storm.kafka.KafkaSpout.EmitState;
import storm.kafka.KafkaSpout.MessageAndRealOffset;
import storm.kafka.trident.MaxMetric;
import java.util.*;
public class PartitionManager {
public static final Logger LOG = LoggerFactory.getLogger(PartitionManager.class);
private final CombinedMetric _fetchAPILatencyMax;
private final ReducedMetric _fetchAPILatencyMean;
private final CountMetric _fetchAPICallCount;
private final CountMetric _fetchAPIMessageCount;
Long _emittedToOffset;
// _pending key = Kafka offset, value = time at which the message was first submitted to the topology
private SortedMap<Long,Long> _pending = new TreeMap<Long,Long>();
private final FailedMsgRetryManager _failedMsgRetryManager;
// retryRecords key = Kafka offset, value = retry info for the given message
Long _committedTo;
LinkedList<MessageAndRealOffset> _waitingToEmit = new LinkedList<MessageAndRealOffset>();
Partition _partition;
SpoutConfig _spoutConfig;
String _topologyInstanceId;
SimpleConsumer _consumer;
DynamicPartitionConnections _connections;
ZkState _state;
Map _stormConf;
long numberFailed, numberAcked;
public PartitionManager(DynamicPartitionConnections connections, String topologyInstanceId, ZkState state, Map stormConf, SpoutConfig spoutConfig, Partition id) {
_partition = id;
_connections = connections;
_spoutConfig = spoutConfig;
_topologyInstanceId = topologyInstanceId;
_consumer = connections.register(id.host, id.partition);
_state = state;
_stormConf = stormConf;
numberAcked = numberFailed = 0;
_failedMsgRetryManager = new ExponentialBackoffMsgRetryManager(_spoutConfig.retryInitialDelayMs,
_spoutConfig.retryDelayMultiplier,
_spoutConfig.retryDelayMaxMs);
String jsonTopologyId = null;
Long jsonOffset = null;
//确定开始位置的代码位置在这里
String path = committedPath();//计算出配置文件的位置
try {
Map<Object, Object> json = _state.readJSON(path);//取出配置文件
LOG.info("Read partition information from: " + path + " --> " + json );
if (json != null) {
jsonTopologyId = (String) ((Map<Object, Object>) json.get("topology")).get("id");
jsonOffset = (Long) json.get("offset");//获得上次读取的位置
}
} catch (Throwable e) {
LOG.warn("Error reading and/or parsing at ZkNode: " + path, e);
}
Long currentOffset = KafkaUtils.getOffset(_consumer, spoutConfig.topic, id.partition, spoutConfig);//取出kafka最新的offset
//判断配置读取出来的是不是空,如果是空按照kafka的位置开始读取,否则重上次位置开始
if (jsonTopologyId == null || jsonOffset == null) { // failed to parse JSON?
_committedTo = currentOffset;
LOG.info("No partition information found, using configuration to determine offset");
} else if (!topologyInstanceId.equals(jsonTopologyId) && spoutConfig.ignoreZkOffsets) {
_committedTo = KafkaUtils.getOffset(_consumer, spoutConfig.topic, id.partition, spoutConfig.startOffsetTime);
LOG.info("Topology change detected and ignore zookeeper offsets set to true, using configuration to determine offset");
} else {
_committedTo = jsonOffset;
LOG.info("Read last commit offset from zookeeper: " + _committedTo + "; old topology_id: " + jsonTopologyId + " - new topology_id: " + topologyInstanceId );
}
if (currentOffset - _committedTo > spoutConfig.maxOffsetBehind || _committedTo <= 0) {
LOG.info("Last commit offset from zookeeper: " + _committedTo);
Long lastCommittedOffset = _committedTo;
_committedTo = currentOffset;
LOG.info("Commit offset " + lastCommittedOffset + " is more than " +
spoutConfig.maxOffsetBehind + " behind latest offset " + currentOffset + ", resetting to startOffsetTime=" + spoutConfig.startOffsetTime);
}
LOG.info("Starting Kafka " + _consumer.host() + ":" + id.partition + " from offset " + _committedTo);
_emittedToOffset = _committedTo;
_fetchAPILatencyMax = new CombinedMetric(new MaxMetric());
_fetchAPILatencyMean = new ReducedMetric(new MeanReducer());
_fetchAPICallCount = new CountMetric();
_fetchAPIMessageCount = new CountMetric();
}
public Map getMetricsDataMap() {
Map ret = new HashMap();
ret.put(_partition + "/fetchAPILatencyMax", _fetchAPILatencyMax.getValueAndReset());
ret.put(_partition + "/fetchAPILatencyMean", _fetchAPILatencyMean.getValueAndReset());
ret.put(_partition + "/fetchAPICallCount", _fetchAPICallCount.getValueAndReset());
ret.put(_partition + "/fetchAPIMessageCount", _fetchAPIMessageCount.getValueAndReset());
return ret;
}
//开始发送消息
//returns false if it's reached the end of current batch
public EmitState next(SpoutOutputCollector collector) {
if (_waitingToEmit.isEmpty()) {
fill();
}
while (true) {
MessageAndRealOffset toEmit = _waitingToEmit.pollFirst();
if (toEmit == null) {
return EmitState.NO_EMITTED;
}
Iterable<List<Object>> tups = KafkaUtils.generateTuples(_spoutConfig, toEmit.msg);
if ((tups != null) && tups.iterator().hasNext()) {
for (List<Object> tup : tups) {
collector.emit(tup, new KafkaMessageId(_partition, toEmit.offset));
}
break;
} else {
ack(toEmit.offset);
}
}
if (!_waitingToEmit.isEmpty()) {
return EmitState.EMITTED_MORE_LEFT;
} else {
return EmitState.EMITTED_END;
}
}
private void fill() {
long start = System.nanoTime();
Long offset;
// Are there failed tuples? If so, fetch those first.
offset = this._failedMsgRetryManager.nextFailedMessageToRetry();
final boolean processingNewTuples = (offset == null);
if (processingNewTuples) {
offset = _emittedToOffset;
}
ByteBufferMessageSet msgs = null;
try {
msgs = KafkaUtils.fetchMessages(_spoutConfig, _consumer, _partition, offset);
} catch (TopicOffsetOutOfRangeException e) {
_emittedToOffset = KafkaUtils.getOffset(_consumer, _spoutConfig.topic, _partition.partition, kafka.api.OffsetRequest.EarliestTime());
LOG.warn("Using new offset: {}", _emittedToOffset);
// fetch failed, so don't update the metrics
//fix bug [STORM-643] : remove outdated failed offsets
if (!processingNewTuples) {
// For the case of EarliestTime it would be better to discard
// all the failed offsets, that are earlier than actual EarliestTime
// offset, since they are anyway not there.
// These calls to broker API will be then saved.
Set<Long> omitted = this._failedMsgRetryManager.clearInvalidMessages(_emittedToOffset);
LOG.warn("Removing the failed offsets that are out of range: {}", omitted);
}
return;
}
long end = System.nanoTime();
long millis = (end - start) / 1000000;
_fetchAPILatencyMax.update(millis);
_fetchAPILatencyMean.update(millis);
_fetchAPICallCount.incr();
if (msgs != null) {
int numMessages = 0;
for (MessageAndOffset msg : msgs) {
final Long cur_offset = msg.offset();
if (cur_offset < offset) {
// Skip any old offsets.
continue;
}
if (processingNewTuples || this._failedMsgRetryManager.shouldRetryMsg(cur_offset)) {
numMessages += 1;
if (!_pending.containsKey(cur_offset)) {
_pending.put(cur_offset, System.currentTimeMillis());
}
_waitingToEmit.add(new MessageAndRealOffset(msg.message(), cur_offset));
_emittedToOffset = Math.max(msg.nextOffset(), _emittedToOffset);
if (_failedMsgRetryManager.shouldRetryMsg(cur_offset)) {
this._failedMsgRetryManager.retryStarted(cur_offset);
}
}
}
_fetchAPIMessageCount.incrBy(numMessages);
}
}
public void ack(Long offset) {
if (!_pending.isEmpty() && _pending.firstKey() < offset - _spoutConfig.maxOffsetBehind) {
// Too many things pending!
_pending.headMap(offset - _spoutConfig.maxOffsetBehind).clear();
}
_pending.remove(offset);
this._failedMsgRetryManager.acked(offset);
numberAcked++;
}
public void fail(Long offset) {
if (offset < _emittedToOffset - _spoutConfig.maxOffsetBehind) {
LOG.info(
"Skipping failed tuple at offset=" + offset +
" because it's more than maxOffsetBehind=" + _spoutConfig.maxOffsetBehind +
" behind _emittedToOffset=" + _emittedToOffset
);
} else {
LOG.debug("failing at offset=" + offset + " with _pending.size()=" + _pending.size() + " pending and _emittedToOffset=" + _emittedToOffset);
numberFailed++;
if (numberAcked == 0 && numberFailed > _spoutConfig.maxOffsetBehind) {
throw new RuntimeException("Too many tuple failures");
}
this._failedMsgRetryManager.failed(offset);
}
}
public void commit() {
long lastCompletedOffset = lastCompletedOffset();
if (_committedTo != lastCompletedOffset) {
LOG.debug("Writing last completed offset (" + lastCompletedOffset + ") to ZK for " + _partition + " for topology: " + _topologyInstanceId);
Map<Object, Object> data = (Map<Object, Object>) ImmutableMap.builder()
.put("topology", ImmutableMap.of("id", _topologyInstanceId,
"name", _stormConf.get(Config.TOPOLOGY_NAME)))
.put("offset", lastCompletedOffset)
.put("partition", _partition.partition)
.put("broker", ImmutableMap.of("host", _partition.host.host,
"port", _partition.host.port))
.put("topic", _spoutConfig.topic).build();
_state.writeJSON(committedPath(), data);
_committedTo = lastCompletedOffset;
LOG.debug("Wrote last completed offset (" + lastCompletedOffset + ") to ZK for " + _partition + " for topology: " + _topologyInstanceId);
} else {
LOG.debug("No new offset for " + _partition + " for topology: " + _topologyInstanceId);
}
}
private String committedPath() {
return _spoutConfig.zkRoot + "/" + _spoutConfig.id + "/" + _partition.getId();
}
public long lastCompletedOffset() {
if (_pending.isEmpty()) {
return _emittedToOffset;
} else {
return _pending.firstKey();
}
}
public Partition getPartition() {
return _partition;
}
public void close() {
commit();
_connections.unregister(_partition.host, _partition.partition);
}
static class KafkaMessageId {
public Partition partition;
public long offset;
public KafkaMessageId(Partition partition, long offset) {
this.partition = partition;
this.offset = offset;
}
}
}最后附上一张kafk保存在zk中的json信息截图

相关文章推荐
- storm-kafka spout获取数据的异常解决办法
- storm整合kafka,spout作为kafka的消费者
- storm-kafka-0.8-plus 源码解析
- storm-kafka源码走读之KafkaSpout
- kafkaspout+storm
- Flume sink Kafka Spout Storm Bolt Hbase or Redis (Flume)
- STORM入门之(集成KafkaSpout)
- (三)storm-kafka源码走读之如何构建一个KafkaSpout
- Flume sink Kafka Spout Storm Bolt Hbase or Redis (Kafka)
- storm中KafkaSpout的选择
- Flume sink Kafka Spout Storm Bolt Hbase or Redis (Storm)
- (五)storm-kafka源码走读之KafkaSpout
- Kafka+Storm+HBase项目Demo(5)--topology,spout,bolt使用
- (三)storm-kafka源代码走读之怎样构建一个KafkaSpout
- Storm opaqueTridentKafkaSpout+HBaseMapState实例
- storm的kafkaSpout实例
- Storm-kafka集成——1.1.0版本storm中tuple取KafkaSpout数据详解
- Storm之——LocalCluster提交storm KafkaSpout重复消费
- storm 0.10.0 kafkaSpout 总是读取旧消息 offset丢失问题
- Storm-Kafka源代码解析