Win7 pySpark安装
2016-09-07 16:02
225 查看
版权声明:如需转载,请注明出处http://blog.csdn.net/a819825294
目录(?)[+]
序
安装
pyCharm wordCount示例
pySpark学习地址
(1)jdk-8u91-windows-x64.exe
(2)spark-1.3.0-bin-hadoop2.4.tgz
(2)spark-1.3.0-bin-hadoop2.4.tgz先进行解压。假设目录为E:\spark-1.3.0-bin-hadoop2.4
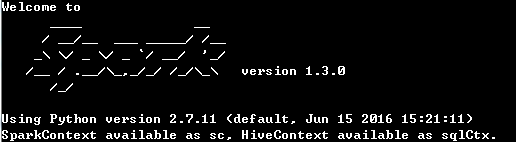
(3)配置环境变量Path,添加E:\spark-1.3.0-bin-hadoop2.4\bin。这时,你可以利用打开cmd,输入pySpark。没有问题的话,你可以看到下图
(4)要想在PyCharm中调用pySpark,需要加载包。将E:\spark-1.3.0-bin-hadoop2.4\python文件夹下pySpark文件夹拷贝到C:\Anaconda2\Lib\site-packages**(注:我的python安装目录是这个路径,可能有的读者是C:\Python27\Lib\site-packages)**
代码中words.txt内容如下
然后运行,然后报错,哈哈哈
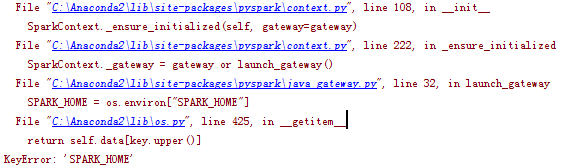
其实是还有一个地方没有配置
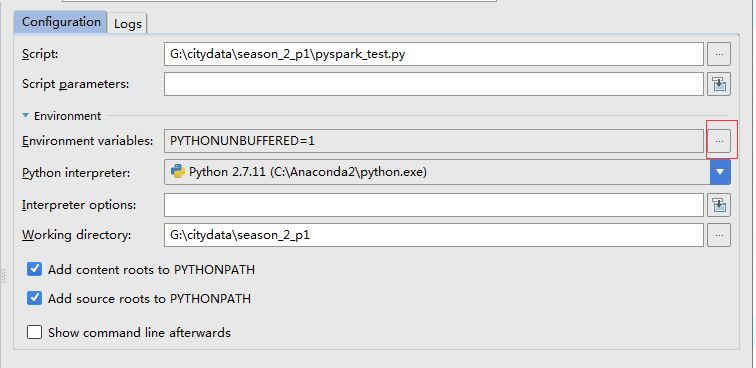
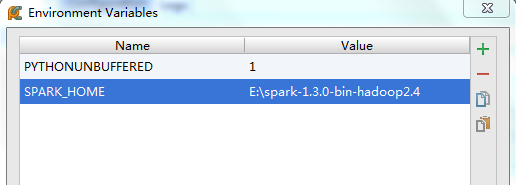
在pyCharm的菜单栏里找到Run => Edit Configurations,点击下面红色标记的地方,添加环境变量。
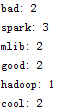
再次运行,就会得到如下结果
(2)在上面解压的文件夹E:\spark-1.3.0-bin-hadoop2.4\examples\src\main\python中有很多示例代码,可以进行学习,本文中的wordCount就是用的上面的代码(进行了一点点修改)。
版权声明:如需转载,请注明出处http://blog.csdn.net/a819825294
目录(?)[+]
序
安装
pyCharm wordCount示例
pySpark学习地址
1.序
由于笔者目前用Python比较多,所以想安装下pySpark,并且在pyCharm中调用。(1)jdk-8u91-windows-x64.exe
(2)spark-1.3.0-bin-hadoop2.4.tgz
2.安装
(1)jdk默认安装(2)spark-1.3.0-bin-hadoop2.4.tgz先进行解压。假设目录为E:\spark-1.3.0-bin-hadoop2.4
(3)配置环境变量Path,添加E:\spark-1.3.0-bin-hadoop2.4\bin。这时,你可以利用打开cmd,输入pySpark。没有问题的话,你可以看到下图
(4)要想在PyCharm中调用pySpark,需要加载包。将E:\spark-1.3.0-bin-hadoop2.4\python文件夹下pySpark文件夹拷贝到C:\Anaconda2\Lib\site-packages**(注:我的python安装目录是这个路径,可能有的读者是C:\Python27\Lib\site-packages)**
3.pyCharm wordCount示例
新建wordCount.py文件,写代码<code class="hljs livecodeserver has-numbering">import sys <span class="hljs-built_in">from</span> operator import <span class="hljs-built_in">add</span> <span class="hljs-built_in">from</span> pyspark import SparkContext <span class="hljs-keyword">if</span> __name__ == <span class="hljs-string">"__main__"</span>: sc = SparkContext(appName=<span class="hljs-string">"PythonWordCount"</span>) <span class="hljs-keyword">lines</span> = sc.textFile(<span class="hljs-string">'words.txt'</span>) counts = <span class="hljs-keyword">lines</span>.flatMap(lambda x: x.<span class="hljs-built_in">split</span>(<span class="hljs-string">' '</span>)) \ .map(lambda x: (x, <span class="hljs-number">1</span>)) \ .reduceByKey(<span class="hljs-built_in">add</span>) output = counts.collect() <span class="hljs-keyword">for</span> (<span class="hljs-built_in">word</span>, count) <span class="hljs-operator">in</span> output: print <span class="hljs-string">"%s: %i"</span> % (<span class="hljs-built_in">word</span>, count) sc.stop()</code><ul class="pre-numbering"><li>1</li><li>2</li><li>3</li><li>4</li><li>5</li><li>6</li><li>7</li><li>8</li><li>9</li><li>10</li><li>11</li><li>12</li><li>13</li><li>14</li><li>15</li><li>16</li><li>17</li></ul><div class="save_code tracking-ad" style="display: none;" data-mod="popu_249"><a target=_blank href="javascript:;" target="_blank"><img src="http://static.blog.csdn.net/images/save_snippets.png" alt="" /></a></div><ul class="pre-numbering"><li>1</li><li>2</li><li>3</li><li>4</li><li>5</li><li>6</li><li>7</li><li>8</li><li>9</li><li>10</li><li>11</li><li>12</li><li>13</li><li>14</li><li>15</li><li>16</li><li>17</li></ul>
代码中words.txt内容如下
<code class="hljs has-numbering">good bad cool hadoop spark mlib good spark mlib cool spark bad</code><ul class="pre-numbering"><li>1</li><li>2</li><li>3</li><li>4</li></ul><div class="save_code tracking-ad" style="display: none;" data-mod="popu_249"><a target=_blank href="javascript:;" target="_blank"><img src="http://static.blog.csdn.net/images/save_snippets.png" alt="" /></a></div><ul class="pre-numbering"><li>1</li><li>2</li><li>3</li><li>4</li></ul>
然后运行,然后报错,哈哈哈
其实是还有一个地方没有配置
在pyCharm的菜单栏里找到Run => Edit Configurations,点击下面红色标记的地方,添加环境变量。
再次运行,就会得到如下结果
4.pySpark学习地址
(1)http://spark.apache.org/docs/latest/api/python/pyspark.html(2)在上面解压的文件夹E:\spark-1.3.0-bin-hadoop2.4\examples\src\main\python中有很多示例代码,可以进行学习,本文中的wordCount就是用的上面的代码(进行了一点点修改)。

相关文章推荐
- 课后第6题
- 会话技术(Cookie,Session)
- VMware Workstation威睿工作站详解
- 五大常用算法——分治法,动态规划,回溯法,分支界限法,贪心算法
- SQL保留关键字不能用作表名
- 关于ImageMagick出现无效参数(invalid parameter)的解决方法
- 会话技术(Cookie,Session)
- 工厂模式(Factory)
- 【python】用setup安装自定义模块和包
- python2.7 print不换行输出
- Mybatis批量新增,修改
- 真正从零开始,TensorFlow详细安装入门图文教程!
- 身份证加密BlowFish
- 如何设置从U盘启动安装win7系统
- Linux系统中如何添加自己的库文件路径
- IT-硬件--硬盘接口对比
- Java 单例模式 安全问题
- Linux基础篇之udev:设备管理器
- 备忘录模式——论微信撤回
- 理解Spring 容器设计理念