基于python开发hadoop shell
2016-09-05 20:01
453 查看
Hadoop是一个分布式计算框架,提供了一个分布式文件系统(HDFS)和一个分布式计算架构(MapReduce)的开源实现。
Hadoop支持一系列子命令,例如fs, jar, distcp等等,具体可以在命令行下输入
由于用户在进行Hadoop相关的管理任务时,执行流(一系列命令的连续调用)往往是连贯和高度相关的,例如
这类命令适合放在一个统一的会话(Session)中进行管理(类比ftp或者sftp,此类软件就是通过一个命令行shell管理FTP会话),这也是本文中设计这样一个shell的基本初衷。
想象一下,如果将这类命令放到shell中执行,由于用户可能会执行其他的系统任务,从而分散了用户的注意力,使其不能专注于与Hadoop管理及配置相关的任务。而通过将Hadoop相关的命令封装到一个交互式shell中,可以使用户集中精力于Hadoop相关管理及操作,提高工作效率。同时,考虑到用户在调用Hadoop时可能需要调用系统命令,程序仍然支持通过
本程序实现了以下功能:
封装了Hadoop中的几个基本子命令,如fs, jar, distcp, daemonlog, classpath, checknative, archive等等。
增加了这些子命令的帮助信息,方便用户调用时即时获取帮助。
增加了Hadoop集群管理相关的几个命令sysctrl以及start, restart, stop, status命令,用于管理集群的启动/重启/关闭以及状态监控。
本项目完整代码可以在CSDN下载:https://code.csdn.net/hijack00/hadoop_shell。
命令行运行
利用
在hadoop shell中可以通过

输入
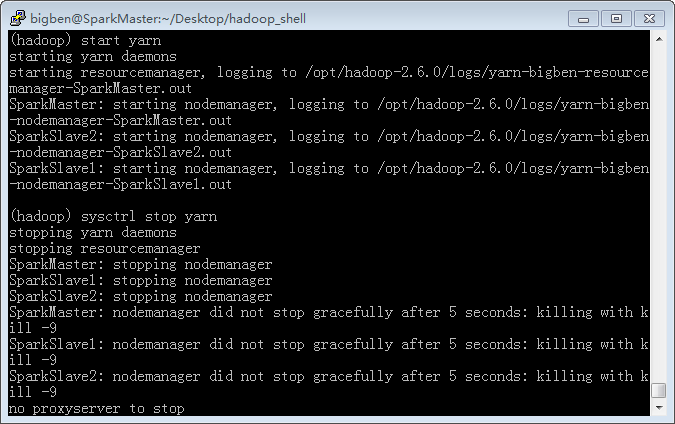
利用sysctrl启动HDFS
查看集群状态,可以看到status命令执行结果和在命令行直接执行
用

通过

利用
通过
输入

最后附上项目完整代码:
Hadoop支持一系列子命令,例如fs, jar, distcp等等,具体可以在命令行下输入
hadoop --help进行查看。本文中通过python cmd模块开发了一个交互式hadoop shell程序,可以在一个交互式shell里面调用Hadoop的常用子命令。同时在shell里面也支持通过
!调用shell命令。关于利用python创建一个小型交互式应用程序的话题,参考我的博客利用python cmd模块开发小型命令行应用程序
由于用户在进行Hadoop相关的管理任务时,执行流(一系列命令的连续调用)往往是连贯和高度相关的,例如
start-dfs.sh,
start-yarn.sh,
hadoop fs等等。用户首先启动HDFS或者yarn集群,之后通过
fs子命令对HDFS进行操作,或者通过
jar子命令提交作业到yarn集群中执行,当完成所有任务之后,用户需要关闭集群。这一围绕Hadoop的工作流,是一个连贯的过程,涉及到大量与Hadoop管理和配置相关的命令的调用,应该尽量避免被打断(例如在这一过程中编译某个程序或者收发邮件),否则会影响工作效率和用户体验。
这类命令适合放在一个统一的会话(Session)中进行管理(类比ftp或者sftp,此类软件就是通过一个命令行shell管理FTP会话),这也是本文中设计这样一个shell的基本初衷。
想象一下,如果将这类命令放到shell中执行,由于用户可能会执行其他的系统任务,从而分散了用户的注意力,使其不能专注于与Hadoop管理及配置相关的任务。而通过将Hadoop相关的命令封装到一个交互式shell中,可以使用户集中精力于Hadoop相关管理及操作,提高工作效率。同时,考虑到用户在调用Hadoop时可能需要调用系统命令,程序仍然支持通过
!调用shell命令。
本程序实现了以下功能:
封装了Hadoop中的几个基本子命令,如fs, jar, distcp, daemonlog, classpath, checknative, archive等等。
增加了这些子命令的帮助信息,方便用户调用时即时获取帮助。
增加了Hadoop集群管理相关的几个命令sysctrl以及start, restart, stop, status命令,用于管理集群的启动/重启/关闭以及状态监控。
本项目完整代码可以在CSDN下载:https://code.csdn.net/hijack00/hadoop_shell。
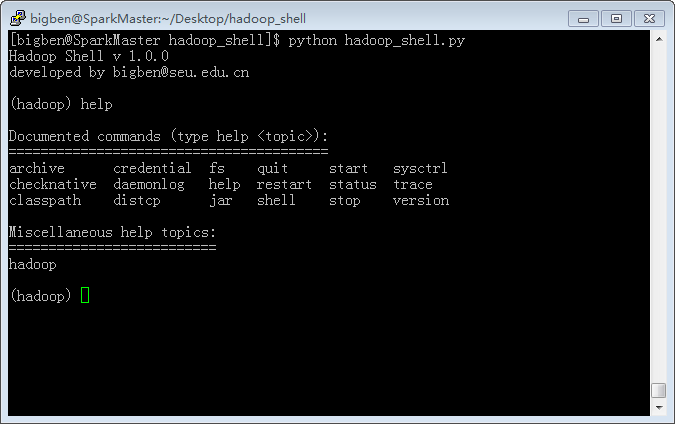
命令行运行
python hadoop_shell.py或者
hadoop_shell.py进入hadoop shell交互式会话环境。输入
help或
?获取帮助信息
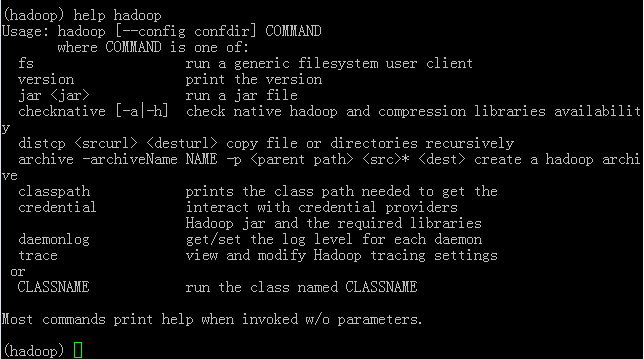
利用
help hadoop查看所有支持的Hadoop子命令的帮助信息
在hadoop shell中可以通过
!执行系统中shell命令,这样可以在不离开hadoop shell会话环境的基础上临时调用某些必要的shell命令。
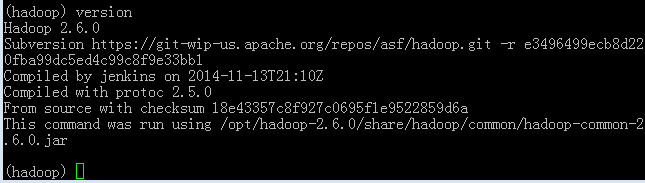
输入
version命令查看Hadoop版本信息
hadoop_shell.py文件中新增加了
sysctrl和
start,
restart,
stop用于集群的管理,包括启动/重启/关闭Hadoop集群。同时提供
status用于查看集群当前工作状态。sysctrl第一个参数为
start|restart|stop,第二个参数为
dfs|yarn|all,实际上是封装了对
${HADOOP_HOME}/scripts/{start|stop}.{dfs|yarn|all}.sh的调用。而start, restart, stop命令则可以看做是sysctrl start|restart|stop的一个快捷方式。在目前的实现中,
status命令实际上是调用了
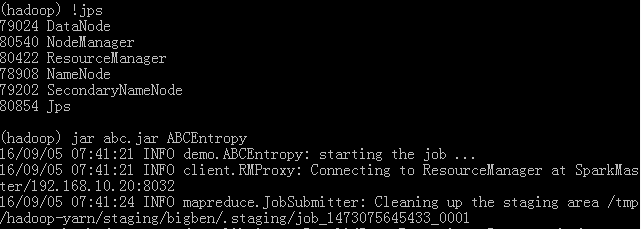
jps命令查看当前正在运行的java进程,用于确定集群是否正常启动。
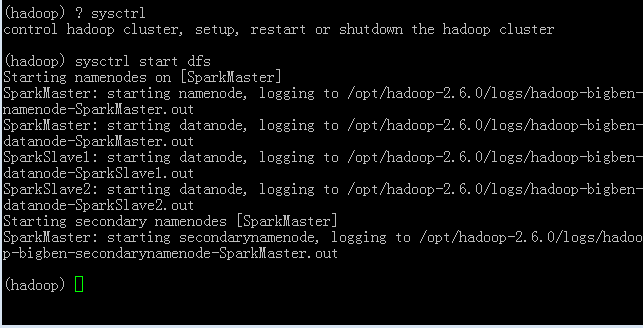
利用sysctrl启动HDFS
查看集群状态,可以看到status命令执行结果和在命令行直接执行
jps命令是一样的。由于DataNode和NameNode等等都已正常运行,可认为HDFS已经正常启动。
用
start|stop命令或者
sysctrl命令启动或关闭yarn集群
通过
help <command>可以获得子命令的详细帮助信息。
利用
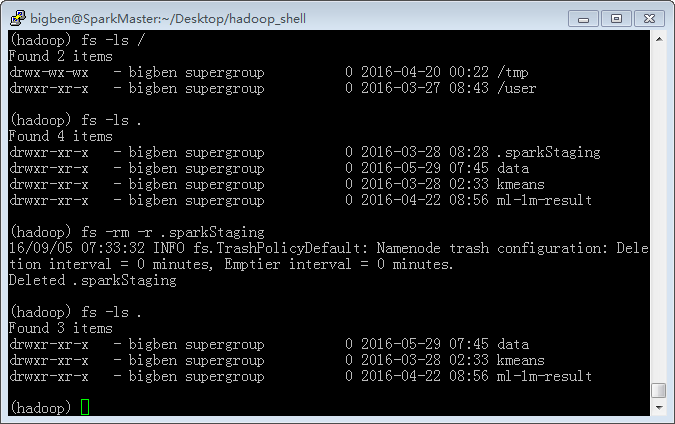
fs命令对HDFS文件进行管理
通过
jar命令提交任务到yarn集群上执行
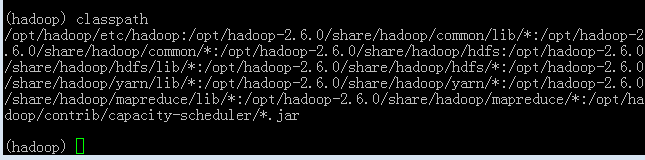
classpath命令执行结果
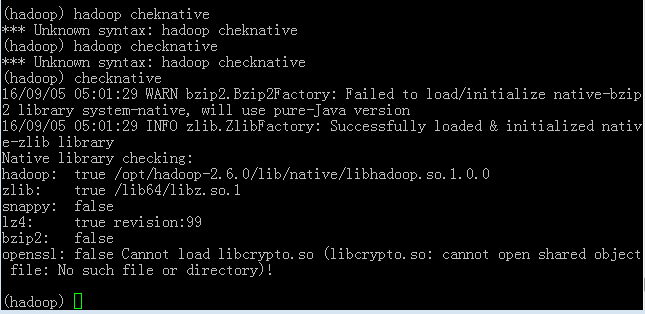
checknative命令执行结果
输入
quit退出交互式环境
最后附上项目完整代码:
# -*- coding:utf-8 -*-
#
import os, sys
import cmd
import subprocess
import shlex
class Shell(cmd.Cmd):
def __init__(self):
cmd.Cmd.__init__(self)
self.prompt = '(hadoop) '
def do_help(self, args):
"pirnt help message"
'List available commands with "help" or detailed help with "help cmd".'
if args:
try:
func = getattr(self, 'help_' + args)
except AttributeError:
try:
doc = getattr(self, 'do_' + args).__doc__
if doc:
self.stdout.write("%s\n\n" % str(doc))
return
except AttributeError:
pass
self.stdout.write("%s\n" % str("*** No help on %s" % (args,)))
return
func()
else:
names = dir(self.__class__)
cmds_doc = []
cmds_undoc = []
help = {}
for name in names:
if name[:5] == 'help_':
help[name[5:]] = 1
names.sort()
prevname = ''
for name in names:
if name[:3] == 'do_':
if name == prevname:
continue
prevname = name
cmd = name[3:]
if cmd in help:
cmds_doc.append(cmd)
del help[cmd]
elif getattr(self, name).__doc__:
cmds_doc.a
d59b
ppend(cmd)
else:
cmds_undoc.append(cmd)
self.stdout.write("%s\n" % str(self.doc_leader))
self.print_topics(self.doc_header, cmds_doc, 15,80)
self.print_topics(self.misc_header, help.keys(),15,80)
self.print_topics(self.undoc_header, cmds_undoc, 15,80)
def help_hadoop(self):
self.do_shell("hadoop --help")
def help_version(self):
print("print the version\n")
def help_classpath(self):
print("prints the class path needed to get the Hadoop jar and the required libraries\n")
def help_checknative(self):
self.do_shell("hadoop checknative -h")
def help_distcp(self):
self.do_shell("hadoop distcp")
def help_archive(self):
self.do_shell("hadoop archive")
def help_credential(self):
self.do_shell("hadoop credential")
def help_daemonlog(self):
self.do_shell("hadoop daemonlog")
def help_trace(self):
self.do_shell("hadoop trace")
def help_fs(self):
self.do_shell("hadoop fs")
def help_jar(self):
self.do_shell("hadoop jar")
def do_version(self, args):
"print the version"
self.do_shell("hadoop version")
def do_checknative(self, args):
"check native hadoop and compression libraries availability"
self.do_shell("hadoop checknative " + args)
def do_classpath(self, args):
"prints the class path needed to get the Hadoop jar and the required libraries"
self.do_shell("hadoop classpath")
def do_distcp(self, args):
"copy file or directories recursively"
self.do_shell("hadoop distcp " + args)
def do_archive(self, args):
"create a hadoop archive"
self.do_shell("hadoop archive " + args)
def do_credential(self, args):
"interact with credential providers"
self.do_shell("hadoop credential" + args)
def do_daemonlog(self, args):
"get/set the log level for each daemon"
self.do_shell("hadoop daemonlog" + args)
def do_trace(self, args):
"view and modify Hadoop tracing settings"
self.do_shell("hadoop trace" + args)
def do_fs(self, args):
"run a generic filesystem user client"
self.do_shell("hadoop fs " + args)
def do_jar(self, args):
"run a jar file"
self.do_shell("hadoop jar " + args)
def do_sysctrl(self, args):
"control hadoop cluster, setup, restart or shutdown the hadoop cluster"
args = shlex.split(args);
action = "start"
instance = "all"
if (len(args) == 0):
print("sysctrl <start|stop|restart> [all|dfs|yarn]")
return
# parse "action"
if (len(args) >= 1):
if (args[0] not in ("start", "restart", "stop")):
self.stdout.write("%s\n" % \
str("*** Invalid action %s. (start|restart|stop)" % (args[0],)))
return
action = args[0]
# parse "instance"
if (len(args) >= 2):
if (args[1] not in ("all", "dfs", "yarn")):
self.stdout.write("%s\n" % \
str("*** Invalid instance %s. (all|dfs|yarn)" % (args[1],)))
return
instance = args[1]
if action == "start":
self.do_shell("start-" + instance + ".sh")
elif action == "stop":
self.do_shell("stop-" + instance + ".sh")
elif action == "restart":
self.do_shell("stop-" + instance + ".sh" + " && " "start-" + instance + ".sh")
def do_start(self, args):
"start hadoop cluster"
self.do_sysctrl("start " + args)
def do_restart(self, args):
"restart hadoop cluster"
self.do_sysctrl("restart " + args)
def do_stop(self, args):
"stop hadoop cluster"
self.do_sysctrl("stop " + args)
def do_status(self, args):
"get hadoop cluster status"
self.do_shell("jps")
def do_shell(self, args):
"run a shell commad"
if not args is None:
subshell = subprocess.Popen(args, shell=True, stdin=None, stdout=None)
subshell.communicate()
# subshell.terminate()
print("")
def do_quit(self, args):
"exit hadoop shell"
return True
if __name__ == "__main__":
shell = Shell()
try:
shell.cmdloop("Hadoop Shell v 1.0.0\ndeveloped by bigben@seu.edu.cn\n")
except KeyboardInterrupt as e:
print "\nUser aborted"
except Exception as e:
print e
print '\nBye!\n'

相关文章推荐
- android wifi 无线调试
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- 详解HDFS Short Circuit Local Reads
- 运维入门
- 动态清空 nohup 输出文件
- install and upgrade scrapy
- install scrapy with pip and easy_install
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Hadoop_2.1.0 MapReduce序列图