SPARK中的基本概念
2016-09-05 12:48
169 查看
基本概念
以下内容主要参考自《大数据Spark企业实战》一书(作者:王家林)Application:用户编写的Spark程序,包含Driver和Executor代码。
Driver:运行main函数并且创建和关闭SparkContext的程序。
Executor:运行在Worker节点上的一个进程,该进程负责运行某些Task,并且负责将数据存放在内存或磁盘中。在Spark On Yarn模式下,其进程名称为CoarseGrainedExecutorBackend。一个arseGrainedExecutorBackend进程有且只有一个executor对象,它持有一个线程池,每个线程可以执行一个Task。
Cluster Manager:指的是在集群上获取资源的外部服务,目前有三种:
1) Standalone:Spark原生的资源管理器,由Master负责资源分配。
2) Apache Mesos:与Hadoop MapReduce兼容性良好的一种资源调度框架。
3) Hadoop Yarn:主要指Yarn中的ResourceManager。
Worker:集群中任何可以运行Application代码的节点。在Standalone模式中指的是通过slave文件配置的Worker节点,在Spark On Yarn模式中指的是NodeManager节点。
Task:被送到某个Executor上的工作单元,是运行Application的基本单位,多个Task组成一个Stage,而Task的调度和管理由TaskSchedule负责。
Job:包含多个Task组成的并行计算,往往由Spark Action触发产生。一个Application中可能会产生多个Job
Stage:每个Job会被拆分成很多组TaskSet,每个TaskSet中有很多Task。TaskSet的名称就是Stage。Stage的划分和调度由DAGScheduler负责。Stage有非最终的Stage(即Shuffle Map Stage)和最终的Stage(即Result Stage)两种。Stage的边界一般就是发生Shuffle的地方。
RDD:弹性分布式数据集,它是已被分区、被序列化、不可变的、有容错性的,并且能够被并行操作的数据集,是Spark最基本的计算单元,也是最核心的东西。RDD可以通过一系列算子进行操作,主要有Transformation和Action操作。
共享变量:在Spark Application运行时,可能需要一些变量,提供给Task或Driver使用。Spark提供了两种共享变量,一种是可以缓存到各个节点的广播变量,另一种是只支持加法操作,实现求和的累加变量。
宽依赖:一个子RDD的分区依赖于父RDD的所有分区。
窄依赖:一个父RDD的分区最多只被一个子RDD的分区所引用。
DAGScheduler:DAGScheduler接收用户提交的job,并将job划分为不同的Stage(划分Stage的依据是RDD之间的依赖关系),并在每一个Stage上产生一系列Task,将Stage提交给TaskScheduler。
TaskScheduler:将TaskSet(Stage)提交给Worker集群运行,每个Executor运行什么Task就在此处分配的。TaskScheduler负责具体启动任务、监控和汇报task运行情况。TaskScheduler是一个trait,它的实现主要用于与DAGScheduler交互,负责任务的具体调度和运行,其核心接口是submitTasks和cancelTasks。
SchedulerBacked:SchedulerBacked也是一个trait.它的实现与底层资源调度系统(如Mesos,Yarn)进行交互,配合TaskScheduler实现具体任务执行所需的资源分配。核心接口是receiveOffers
引用一个例子:
术语总是难以理解的,因为它取决于所处的上下文。在很多情况下,你可能习惯于“将Job提交给一个cluster”,但是对于spark而言却是提交了一个driver程序。也就是说,对于Job,spark有它自己的定义,如下:
A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you’ll see this term used in the driver’s logs.
在这个例子中,假设你需要做如下一些事情:
1. 将一个包含人名和地址的文件加载到RDD1中
2. 将一个包含人名和电话的文件加载到RDD2中
3. 通过name来Join RDD1和RDD2,生成RDD3
4. 在RDD3上做Map,给每个人生成一个HTML展示卡作为RDD4
5. 将RDD4保存到文件
6. 在RDD1上做Map,从每个地址中提取邮编,结果生成RDD5
7. 在RDD5上做聚合,计算出每个邮编地区中生活的人数,结果生成RDD6
8. Collect RDD6,并且将这些统计结果输出到stdout
根据以上要求,如图:
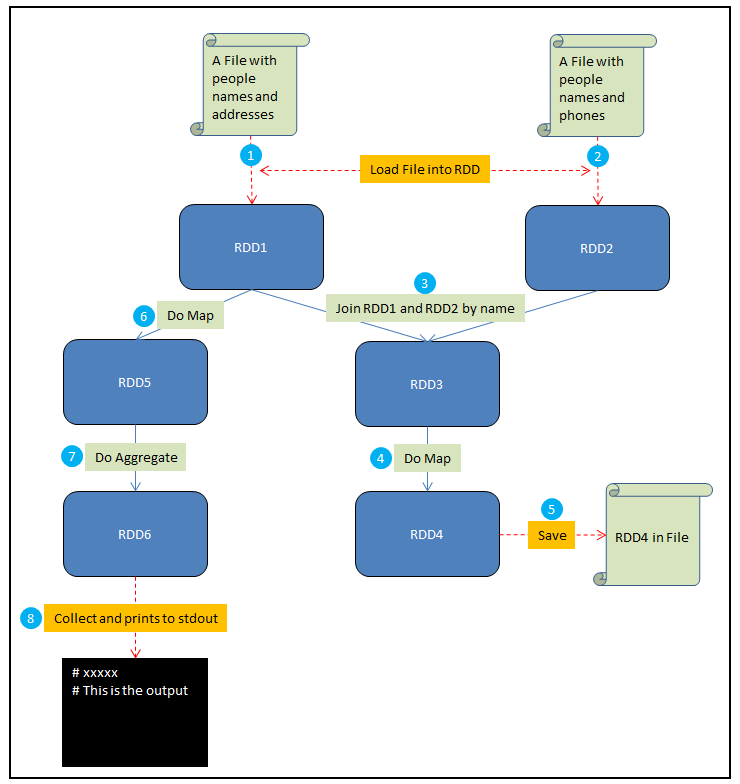
其中红色虚线表示输入和输出,蓝色实线是对RDD的操作,圆圈中的数字对应了以上的8个步骤。接下来解释driver program, job和stage这几个概念:
Driver program是全部的代码,运行所有的8个步骤。
第五步中的save和第八步中的collect都是Spark Job。Spark中每个action对应着一个Job,transformation不是Job。
其他的步骤(1、2、3、4、6、7)被Spark组织成stages,每个job则是一些stage序列的结果。对于一些简单的场景,一个job可以只有一个stage。但是对于数据重分区的需求(比如第三步中的join),或者任何破坏数据局域性的事件,通常会导致更多的stage。可以将stage看作是能够产生中间结果的计算。这种计算可以被持久化,比如可以把RDD1持久化来避免重复计算。
以上全部三个概念解释了某个算法被拆分的逻辑。相比之下,task是一个特定的数据片段,在给定的executor上,它可以跨越某个特定的stage。
到了这里,很多概念就清楚了。驱动程序就是执行了一个Spark Application的main函数和创建Spark Context的进程,它包含了这个application的全部代码。Spark Application中的每个action会被Spark作为Job进行调度。每个Job是一个计算序列的最终结果,而这个序列中能够产生中间结果的计算就是一个stage。
转载自:
http://blog.csdn.net/u014729236/article/details/45364753
http://blog.csdn.net/jiangwlee/article/details/50774561

相关文章推荐
- Spark中文手册4:Spark之基本概念(2)
- spark源码阅读笔记RDD(一)RDD的基本概念
- SPARK中的基本概念
- 『 Spark 』2. spark 基本概念解析
- 【Spark】Spark基本概念
- Spark基本概念
- SPARK中的基本概念
- Spark学习笔记 --- SparkStreaming 中基本概念
- Spark1.0.0 运行架构基本概念
- Spark中文手册5:Spark之基本概念(3)
- Spark基本概念与执行流程
- SPARK中的基本概念
- Spark实践项目4:Spark基本概念
- Spark基本概念简介
- <<Spark Streaming Programming Guide>> - Part 2 基本概念
- Spark的几个基本概念:Driver和Job,Stage
- Spark RDD基本概念与基本用法
- SPARK中的基本概念
- spark基本概念
- Spark基本概念快速入门