统计文件中数据出现的次数并排序
2016-09-04 20:34
351 查看
文件中保存的是好多行采集的数据,统计出现次数最多的前n个数据。
sort排序后相同的数据会连续出现此时再使用uniq进行去重,-c的含义是添加一行出现次数的数据。
文件里的数据:
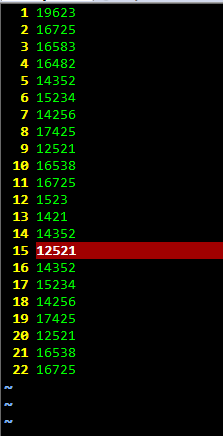
执行命令后:
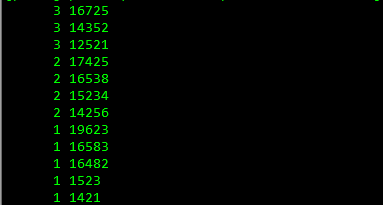
sort排序后相同的数据会连续出现此时再使用uniq进行去重,-c的含义是添加一行出现次数的数据。
awk '{print $1}' data_file | sort | uniq -c | sort -r -k1 > data_sort文件里的数据:
执行命令后:

相关文章推荐
- Linux socket 初步
- Linux Kernel 4.0 RC5 发布!
- linux lsof详解
- linux 文件权限
- Linux 执行数学运算
- 10 篇对初学者和专家都有用的 Linux 命令教程
- Linux 与 Windows 对UNICODE 的处理方式
- Ubuntu12.04下QQ完美走起啊!走起啊!有木有啊!
- 解決Linux下Android开发真机调试设备不被识别问题
- 运维入门
- 运维提升
- Linux 自检和 SystemTap
- Ubuntu Linux使用体验
- c语言实现hashmap(转载)
- Linux 信号signal处理机制
- linux下mysql添加用户
- Scientific Linux 5.5 图形安装教程
- Linux 下无损图片压缩小工具介绍