#Paper Reading# Leveraging Multi-Domain Prior Knowledge in Topic Models
2016-09-03 23:46
501 查看
论文题目:Leveraging Multi-Domain Prior Knowledge in Topic Models
论文地址:http://www.ijcai.org/Proceedings/13/Papers/306.pdf
论文大体内容:
现在的主题模型主要有LDA[1],NMF[2]以及基于这两大类的一系列改进模型,但大部分都是仅针对一个dataset。作者提出,我们人的学习过程是一个迭代学习的过程,像以前学习到的知识,对我们现在面临的问题会是一个很好的solution。因此,作者提出一个叫MDK-LDA(LDA with Multi-Domain Knowledge)的模型,能够根据之前topic model学习到的知识,指导下一次的学习。
1、作者提出使用s-set来表示单词的集合,这个集合中的单词在这个领域中含有相同的语义。这个先验知识就类似于must-link,就是必连关系。而本文中,作者不使用cannot-link的关系,即必不连。
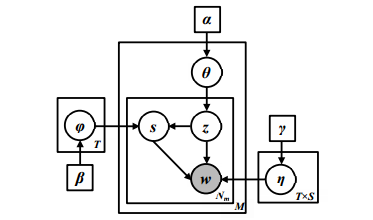
2、作者将LDA模型改进,具体的framework如图。
3、具体伪代码如图。

4、Baseline:作者对比了3个baseline,包括:
①LDA[1],最原始、基本的LDA算法,使用狄利克雷分布计算主题概率的非监督式主题模型;
②LDA with GPU[3],在LDA中使用GPU(generalized Pólya urn[5])模型进行改进处理;
③DF-LDA[4],基于knowledge base的主题模型,使用了must-link与cannot-link的方法;
5、Dataset:作者使用了Amazon网站上的评论数据集,包括“Watch,” “Camera,” “Cellphone,” “Computer,” “Food” and “Personal Care”共6个领域各500个评论。经过一系列预处理并将每个评论按句子拆分,让每个句子看作单独的文档进行处理。
6、参数设置:使用了1000次Gibbs迭代,并设置α=1,β=0.1,主题数量设定为T=15。
7、作者按照 Watch → Camera → Cellphone → Computer → Food → Personal Care 这个顺序进行实验,分别验证相近主题下先验知识的作用,以及主题语义差距大的情况下先验知识的表现。作者还对比了仅使用以前的知识,仅使用当前的知识,同时使用以前的知识和当前的知识,3种情况下模型的表现。
8、实验结论:作者发现,MDK-LDA模型比baseline的效果好很多,而对于在相近主题下,使用以前的知识+当前的知识表现得最好,而在主题语义差距大的情况下,如果加入以前的知识,会相当于给模型加入了noise,导致仅使用当前的知识比同时使用以前的知识+当前的知识的表现要好。
9、思考:
我们人类学习东西,其实是一个渐进,迭代的过程,而且一项知识,会适用于各个地方,比如今天学习到的数学知识,明天能用它来学习物理,从而一步一步提高自己的知识储备,从而在新环境、新问题下能够想出一个适用的解决方案。而我们学习、使用Machine Learning的目标,就是要让机器能够跟人一样思考、学习。所以,跨领域学习,迁移学习,持续性学习必将是Machine Learning的下一步。
参考资料:
[1]、http://www.jmlr.org/papers/v3/blei03a.html
[2]、http://papers.nips.cc/paper/1861-alg
[3]、http://dl.acm.org/citation.cfm?id=2145462
[4]、http://dl.acm.org/citation.cfm?id=1553378
[5]、https://en.wikipedia.org/wiki/P%C3%B3lya_urn_model
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!
论文地址:http://www.ijcai.org/Proceedings/13/Papers/306.pdf
论文大体内容:
现在的主题模型主要有LDA[1],NMF[2]以及基于这两大类的一系列改进模型,但大部分都是仅针对一个dataset。作者提出,我们人的学习过程是一个迭代学习的过程,像以前学习到的知识,对我们现在面临的问题会是一个很好的solution。因此,作者提出一个叫MDK-LDA(LDA with Multi-Domain Knowledge)的模型,能够根据之前topic model学习到的知识,指导下一次的学习。
1、作者提出使用s-set来表示单词的集合,这个集合中的单词在这个领域中含有相同的语义。这个先验知识就类似于must-link,就是必连关系。而本文中,作者不使用cannot-link的关系,即必不连。
2、作者将LDA模型改进,具体的framework如图。
3、具体伪代码如图。
4、Baseline:作者对比了3个baseline,包括:
①LDA[1],最原始、基本的LDA算法,使用狄利克雷分布计算主题概率的非监督式主题模型;
②LDA with GPU[3],在LDA中使用GPU(generalized Pólya urn[5])模型进行改进处理;
③DF-LDA[4],基于knowledge base的主题模型,使用了must-link与cannot-link的方法;
5、Dataset:作者使用了Amazon网站上的评论数据集,包括“Watch,” “Camera,” “Cellphone,” “Computer,” “Food” and “Personal Care”共6个领域各500个评论。经过一系列预处理并将每个评论按句子拆分,让每个句子看作单独的文档进行处理。
6、参数设置:使用了1000次Gibbs迭代,并设置α=1,β=0.1,主题数量设定为T=15。
7、作者按照 Watch → Camera → Cellphone → Computer → Food → Personal Care 这个顺序进行实验,分别验证相近主题下先验知识的作用,以及主题语义差距大的情况下先验知识的表现。作者还对比了仅使用以前的知识,仅使用当前的知识,同时使用以前的知识和当前的知识,3种情况下模型的表现。
8、实验结论:作者发现,MDK-LDA模型比baseline的效果好很多,而对于在相近主题下,使用以前的知识+当前的知识表现得最好,而在主题语义差距大的情况下,如果加入以前的知识,会相当于给模型加入了noise,导致仅使用当前的知识比同时使用以前的知识+当前的知识的表现要好。
9、思考:
我们人类学习东西,其实是一个渐进,迭代的过程,而且一项知识,会适用于各个地方,比如今天学习到的数学知识,明天能用它来学习物理,从而一步一步提高自己的知识储备,从而在新环境、新问题下能够想出一个适用的解决方案。而我们学习、使用Machine Learning的目标,就是要让机器能够跟人一样思考、学习。所以,跨领域学习,迁移学习,持续性学习必将是Machine Learning的下一步。
参考资料:
[1]、http://www.jmlr.org/papers/v3/blei03a.html
[2]、http://papers.nips.cc/paper/1861-alg
[3]、http://dl.acm.org/citation.cfm?id=2145462
[4]、http://dl.acm.org/citation.cfm?id=1553378
[5]、https://en.wikipedia.org/wiki/P%C3%B3lya_urn_model
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!

相关文章推荐
- #Paper Reading# Online Knowledge-Based Model for Big Data Topic Extraction
- PaperReading: SDNRacer: Detecting Concurrency Violations in Software-Defined Networks
- #Paper Reading# Lifelong aspect extraction from big data knowledge engineering
- READING NOTE: Towards Accurate Multi-person Pose Estimation in the Wild
- Reading papers_15(Graph cuts optimization for multi-limb human segmentation in depth maps)
- #Paper Reading# Topic Modeling using Topics from Many Domains, Lifelong Learning and Big Data
- #Paper Reading# Recent Advances in Document Summarization
- [eZ publish] multi sub domain with multi language in eZ publish
- [Paper 学习笔记] Multi-Scale 3D Convolutional Neural Networks for Lesion Segmentation in Brain MRI
- #Paper Reading# Mining Aspect-Specific Opinion using a Holistic Lifelong Topic Model
- Paper Reading - In Search of an Understandable Consensus Algorithm(Raft)
- #Paper Reading# Robust Word-Network Topic Model for Short Texts
- #Paper Reading# Multi-Document Summarization via Sentence-Level Semantic Analysis and SMF
- programming all the time in the office, reading paper at home!
- #Paper Reading# Summarizing Answers in Non-Factoid Community Question-Answering
- #Paper Reading# Manifold-Ranking Based Topic-Focused Multi-Document Summarization
- #Paper Reading# Multi-document Summarization Based on Cluster Using Non-negative Matrix
- [Drupal] multi site with subdomain running the same code in Drupal
- paper reading in 1/1/2016~1/3/2016
- #Paper Reading# Fast Online EM for Big Topic Modeling