TIMIT数据库(一):介绍
2016-09-03 10:51
465 查看
数据是大数据时代互联网巨头们傲视群雄的秘密武器。当我们想要接触一个数据驱动型的新领域(如语音识别)时,往往囿于没有足够成熟的数据做实验而举步维艰。幸运的是,有很多机构将他们的成熟的数据公开出来,供我们学习、研究,TIMIT数据库就是其中之一。
TIMIT全称The DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus, 是由德州仪器(TI)、麻省理工学院(MIT)和坦福研究院(SRI)合作构建的声学-音素连续语音语料库。TIMIT数据集的语音采样频率为16kHz,一共包含6300个句子,由来自美国八个主要方言地区的630个人每人说出给定的10个句子,所有的句子都在音素级别(phone level)上进行了手动分割,标记。70%的说话人是男性;大多数说话者是成年白人。
在给定的10个句子,包括:
2个方言句子(SA, dialect sentences),对于每个人这2个方言句子都是相同的;
5个音素紧凑句子(SX, phonetically compact sentences),这5个是从MIT所给的450个因素分布平衡的句子中选出,目的是为了尽可能的包含所有的音素对。
3个音素发散句子(SI, phonetically diverse sentences),这3个是由TI从已有的Brown 语料库(the Brown Coupus)和剧作家对话集(the Playwrights Dialog)中随机选择的,目的是为了增加句子类型和音素文本的多样性,使之尽可能的包括所有的音位变体(allophonic contexts)。
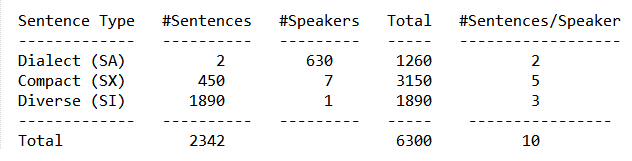
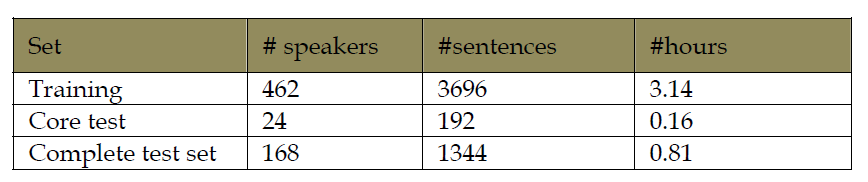
TIMIT官方文档建议按照7:3的比例将数据集划分为训练集(70%)和测试集(30%),但一般只用到SX和SI的句子,也就是说训练集包括由462个人所讲的3696个句子,全部测试集(complete test set)包括由168个人所讲的1344个句子,核心测试集(Core test)包括由24个所讲的192个句子,训练集和测试集没有重合。具体如下:
TIMIT的原始录音是基于61个音素的,如下所示:
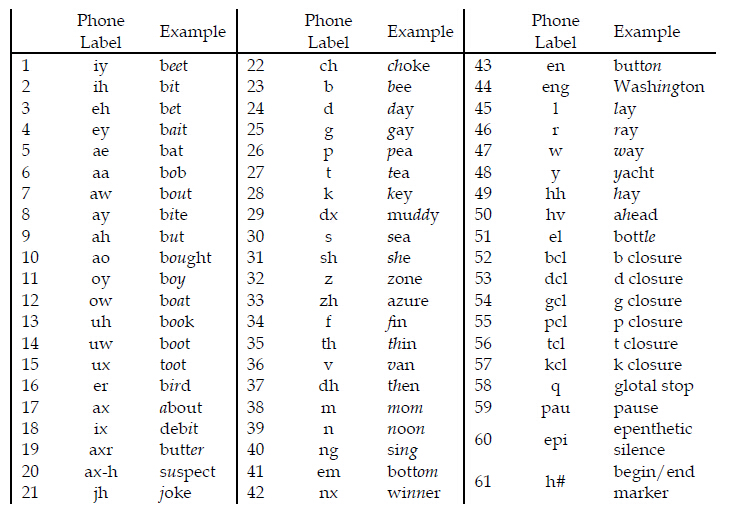
由于在实际中61个音素考虑的情况太多,因而在训练时有些研究者整合为48个音素,当评估模型时,李开复在他的成名作(Lee & Hon, 1989)所提出的将61个音素合并为39个音素方法被广为使用。
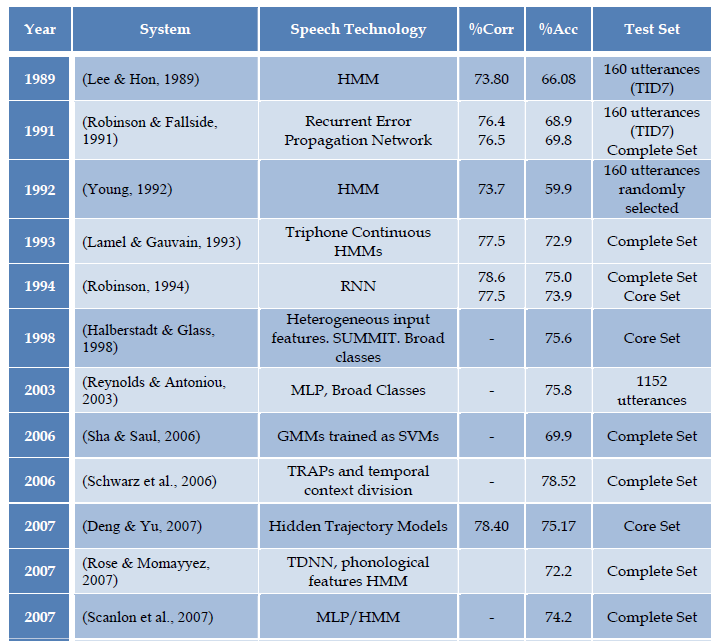
下面列出近年来在TIMIT数据库上进行语音识别实验的研究成果,有兴趣可以查看相关论文。
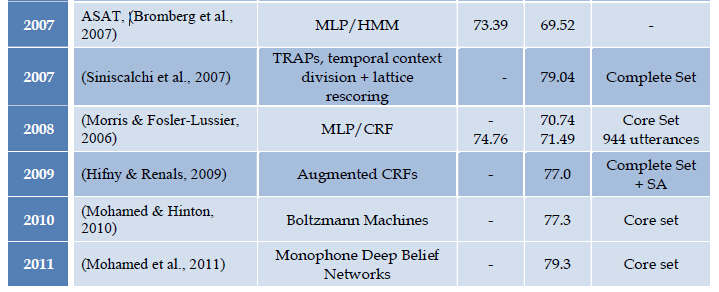
TIMIT语料库多年来已经成为语音识别社区的一个标准数据库,在今天仍被广为使用。其原因主要有两个方面:
数据集中的每一个句子都在音素级别上进行了手动标记,同时提供了说话人的编号,性别,方言种类等多种信息;
数据集相对来说比较小,可以在较短的时间内完成整个实验;同时又足以展现系统的性能。
下一篇: TIMIT数据库(二):文件目录及结构
参考文献:
Lopes, Carla, and Fernando Perdigao. “Phone recognition on the TIMIT database.” Speech Technologies/Book 1 (2011): 285-302.
Lee, K-F., and H-W. Hon. “Speaker-independent phone recognition using hidden Markov models.” IEEE Transactions on Acoustics, Speech, and Signal Processing 37.11 (1989): 1641-1648.
Documentation for TIMIT
TIMIT全称The DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus, 是由德州仪器(TI)、麻省理工学院(MIT)和坦福研究院(SRI)合作构建的声学-音素连续语音语料库。TIMIT数据集的语音采样频率为16kHz,一共包含6300个句子,由来自美国八个主要方言地区的630个人每人说出给定的10个句子,所有的句子都在音素级别(phone level)上进行了手动分割,标记。70%的说话人是男性;大多数说话者是成年白人。
在给定的10个句子,包括:
2个方言句子(SA, dialect sentences),对于每个人这2个方言句子都是相同的;
5个音素紧凑句子(SX, phonetically compact sentences),这5个是从MIT所给的450个因素分布平衡的句子中选出,目的是为了尽可能的包含所有的音素对。
3个音素发散句子(SI, phonetically diverse sentences),这3个是由TI从已有的Brown 语料库(the Brown Coupus)和剧作家对话集(the Playwrights Dialog)中随机选择的,目的是为了增加句子类型和音素文本的多样性,使之尽可能的包括所有的音位变体(allophonic contexts)。
TIMIT官方文档建议按照7:3的比例将数据集划分为训练集(70%)和测试集(30%),但一般只用到SX和SI的句子,也就是说训练集包括由462个人所讲的3696个句子,全部测试集(complete test set)包括由168个人所讲的1344个句子,核心测试集(Core test)包括由24个所讲的192个句子,训练集和测试集没有重合。具体如下:
TIMIT的原始录音是基于61个音素的,如下所示:
由于在实际中61个音素考虑的情况太多,因而在训练时有些研究者整合为48个音素,当评估模型时,李开复在他的成名作(Lee & Hon, 1989)所提出的将61个音素合并为39个音素方法被广为使用。
下面列出近年来在TIMIT数据库上进行语音识别实验的研究成果,有兴趣可以查看相关论文。
TIMIT语料库多年来已经成为语音识别社区的一个标准数据库,在今天仍被广为使用。其原因主要有两个方面:
数据集中的每一个句子都在音素级别上进行了手动标记,同时提供了说话人的编号,性别,方言种类等多种信息;
数据集相对来说比较小,可以在较短的时间内完成整个实验;同时又足以展现系统的性能。
下一篇: TIMIT数据库(二):文件目录及结构
参考文献:
Lopes, Carla, and Fernando Perdigao. “Phone recognition on the TIMIT database.” Speech Technologies/Book 1 (2011): 285-302.
Lee, K-F., and H-W. Hon. “Speaker-independent phone recognition using hidden Markov models.” IEEE Transactions on Acoustics, Speech, and Signal Processing 37.11 (1989): 1641-1648.
Documentation for TIMIT

相关文章推荐
- SQL的详细语法介绍——对于学习数据库最基础知识二
- 介绍三种功能强大的数据库表格控件
- jTDS官方介绍(OpenCms v6.2版MS Sqlserver数据库支持所用JDBC驱动)
- 使用Tomcat-5.5.20配置数据库连接池详细介绍
- 用SqlDataAdapter更新数据库的方法介绍
- 介绍几种 ADO.net 中的数据库连接方式
- 开源的数据库连接池 SQL Relay 介绍
- 介绍一个简单的数据库开发平台——mcis应用服务器中间件
- 数据库中数据挖掘的基本技术介绍
- 以地籍库为例介绍AutoCAD数据库连接
- 介绍Matisse--专为.NET的后关系型数据库part 1
- 介绍一个完全托管代码的对象数据库DB4O
- 开源嵌入式数据库Berkeley DB的介绍
- 新建oracle数据库(各种方式)-数据库开发介绍
- 用SqlDataAdapter更新数据库的方法介绍
- SQL的详细语法介绍——对于学习数据库最基础知识[转]
- 三层数据库与应用程序服务器的小型介绍(Delphi&BCB)(原创)
- 数据库连接之jtds介绍
- 使用Tomcat-5.5.20配置数据库连接池详细介绍
- 介绍如何使用Connection对象连接数据库