谈谈深度学习中的 Batch_Size
2016-09-01 16:14
531 查看
谈谈深度学习中的 Batch_Size
Batch_Size(批尺寸)是机器学习中一个重要参数,涉及诸多矛盾,下面逐一展开。
首先,为什么需要有 Batch_Size 这个参数?
Batch 的选择,首先决定的是下降的方向。如果数据集比较小,完全可以采用全数据集 ( Full Batch Learning )的形式,这样做至少有 2 个好处:其一,由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。其二,由于不同权重的梯度值差别巨大,因此选取一个全局的学习率很困难。
Full Batch Learning 可以使用Rprop 只基于梯度符号并且针对性单独更新各权值。
对于更大的数据集,以上 2 个好处又变成了 2 个坏处:其一,随着数据集的海量增长和内存限制,一次性载入所有的数据进来变得越来越不可行。其二,以 Rprop 的方式迭代,会由于各个 Batch 之间的采样差异性,各次梯度修正值相互抵消,无法修正。这才有了后来 RMSProp 的妥协方案。
既然 Full Batch Learning 并不适用大数据集,那么走向另一个极端怎么样?
所谓另一个极端,就是每次只训练一个样本,即 Batch_Size = 1。这就是在线学习(Online Learning)。线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆。对于多层神经元、非线性网络,在局部依然近似是抛物面。使用在线学习,每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。
可不可以选择一个适中的 Batch_Size 值呢?
当然可以,这就是批梯度下降法(Mini-batches Learning)。因为如果数据集足够充分,那么用一半(甚至少得多)的数据训练算出来的梯度与用全部数据训练出来的梯度是几乎一样的。
在合理范围内,增大 Batch_Size 有何好处?
内存利用率提高了,大矩阵乘法的并行化效率提高。
跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
盲目增大 Batch_Size 有何坏处?
内存利用率提高了,但是内存容量可能撑不住了。
跑完一次 epoch(全数据集)所需的迭代次数减少,要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢。
Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化。
调节 Batch_Size 对训练效果影响到底如何?
这里跑一个 LeNet 在 MNIST 数据集上的效果。MNIST 是一个手写体标准库,我使用的是 Theano 框架。这是一个 Python 的深度学习库。安装方便(几行命令而已),调试简单(自带
Profile),GPU / CPU 通吃,官方教程相当完备,支持模块十分丰富(除了
CNNs,更是支持 RBM / DBN / LSTM / RBM-RNN / SdA / MLPs)。在其上层有 Keras 封装,支持
GRU / JZS1, JZS2, JZS3 等较新结构,支持 Adagrad / Adadelta / RMSprop / Adam 等优化算法。
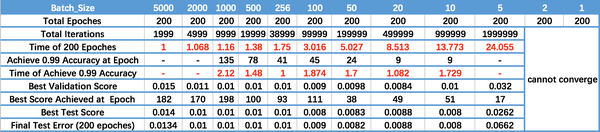
运行结果如上图所示,其中绝对时间做了标幺化处理。运行结果与上文分析相印证:
Batch_Size 太小,算法在 200 epoches 内不收敛。
随着 Batch_Size 增大,处理相同数据量的速度越快。
随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。
由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
欢迎一起讨论。
编辑于
2015-11-08 24
条评论 感谢
分享
收藏 • 没有帮助 •
举报
• 禁止转载
收起
11赞同
反对,不会显示你的姓名

纳米酱,理论物理跳深度学习坑ing
bonnenuit、Wang
Gu、高航 等人赞同
批训练的引入最大好处是针对非凸损失函数来做的, 毕竟非凸的情况下, 全样本就算工程上算的动, 也会卡在局部优上, 批表示了全样本的部分抽样实现, 相当于人为引入修正梯度上的采样噪声,使“一路不通找别路”更有可能搜索最优值。
楼上很多说到随机梯度收敛问题,物理上是这样的理解,
增加噪音扩大了你的行动范围,不会受限于局部。
然而过大的行动范围使得你的选择过多而”迷茫“。
这是一个损失函数局部优有“多坑人”和局部优“数目太多好难选”之间的竞争,竞争平衡点才是你最终的训练值。故此,最终的训练值是一个分布,大伙们一般取平均来证明自己的模型多牛逼。
物理上,就是能量(坑好深)和熵(选择多)的竞争结果,而且复杂系统中,能量和熵一辈子都在竞争,讨论自由能最小值在非凸问题上的意义,比直接讨论损失函数的最小值更有意义。
然而,这种牛逼,不仅依赖模型,而且依赖数据本身。调参需要预先建立竞争平衡的理论模型,单纯用软件刷指标只能用在某个数据集上,不具有转移性。纯浪费电!
这些观点在大部分复杂物理系统的采样,自旋玻璃的研究,蛋白质折叠构象搜索上,都有广泛的认识。但是工业界被凸优化影响过多了,除了特征选择和防止过拟合外可以通过直觉建立,遇到非凸优化问题,基本不可能拍脑袋调出一个通用的(如果数学上可以,物理上应该最先发现,然而并没有)。于是,即便在物理上遇到这种问题,目前很low,而且节省成本的方法就是烧钱增加计算蛮力点。矛盾到我笑尿了。
关于深度学习中的非凸优化,可以参考LeCun今年来对深度学习和自旋玻璃之间的联系,以及随机微分方程同增强采样之间的研究。
发布于
2015-11-10 2
条评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
1赞同
反对,不会显示你的姓名

年月Soiliml,打电竞!啃代码!搞算法!请叫我男孩子!
张馨宇 赞同
搞机器学习大忌就是不做实验想当然,话说这种问题题主跑几组不同的batch不就知道了...调参调参不调哪来的参~
另外,运用在不同的领域,不同的网络结构,不同的训练方法,batch的取法,用法和影响也不一样。不知道题主问的是哪种batch?
发布于
2015-11-30 5
条评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
0赞同
反对,不会显示你的姓名

宇文叔,我是认真的
我也看到过说理论上batchsize=1是最好的,不过实际上调的时候,可能因为我调参的能力比较有限,确实batchsize太小会出现网络收敛不稳定,最后结果比较差的情况,这个在ImageNet和其他数据库上都遇到过,而batchsize太大确实也会影响随机性的引入。目前一般调ImageNet的时候,大家都喜欢把显存占满,不过小一些的库,个人感觉还是应该大大小小都尝试一下。不知道各路大神有没有什么好办法指点一下。。
发布于
2015-07-28 添加评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
14赞同
反对,不会显示你的姓名

Yinghong
li,正在经历到目前为止的人生最重要的一年
PainKilller、李浩、陈程鹏 等人赞同
caffe小菜鸟也来答一下,感觉就是大batch size在显存能允许的情况下收敛速度是比较快的但有时的确会有陷入局部最小的情况,小batch size引入的随机性会更大些,有时候能有更好的效果,但是就是收敛速度慢一些……
还有就是除了batch size这个参数外,如果在solver setting中有momentum这个参数的话也要注意batch size的选取,具体参考一下caffe的tutorial
关于训练参数怎么选取可以参考以下一些文章:
Bengio的 Practical recommendations for gradient-based learning
http://link.springer.com/chapter/10.1007/978-3-642-35289-8_26
Lecun 和 Bottou的 Efficient Backprop
http://link.springer.com/chapter/10.1007/978-3-642-35289-8_3
还有一个代码上的细节,就是caffe的代码实现上选取一个batch的时候似乎是按着数据库的图片顺序选取输入图片的,所以在生成数据库的时候切记要shuffle一下图片顺序~
供题主参考,求大神指正~
发布于
2015-07-25 1
条评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
13赞同
反对,不会显示你的姓名
匿名用户
李浩、王小明、孔秋强 等人赞同
看你GPU显存,显存大就把batch size设大点,反之亦然。一般情况下对学习效果没影响。
补充点细节:
事实上从优化的角度来说最快的是纯stochastic,即batch size为1。
关于这一点参见Leon Bottou的分析:http://leon.bottou.org/publications/pdf/compstat-2010.pdf。当然,文中的分析适用于large
scale的情况下,但deep neural net适用的条件之一就是有大量数据。另外http://cilvr.nyu.edu/lib/exe/fetch.php?media=deeplearning:dl-optimization.pdf 的第11页也有比较stochastic和batch的优劣。
拿Yann Lecun在上述第二个链接第10页中举的toy example来说,如果事实上只有100个数据点,但有人各复制了10遍拿给你,你不知道。这时候你如果做batch gradient descent,更只用了100个点效果一样;而做stochastic gradient descent则相当于做了10个epoch。相近的计算量后者效果显然更好。至于mini batch,要你取的每个mini batch都很diverse的情况才会效果好。
当然你会说,现实中哪会有100个数据各重复10遍就直接拿来用的?没错,是不会,但现实中的数据,尤其是large scale的数据中,必然有大量的redundancy,不然你也很难学出有较好泛化性的model。因此stochastic在large scale总是优于batch。
那为什么还要用mini batch呢?这是由于GPU并行运算的性质,同时把多组数据传过去一起运算比一条一条运算来的快,因而mini batch只是为了充分利用GPU memory而做出的妥协。既然如此,batch size也调到刚好能塞进显存就差不多了。
编辑于
2015-07-21 1
条评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
0赞同
反对,不会显示你的姓名

Zhang
fusu,语音识别,声纹识别
可以考虑两个极端:A.全部数据作为一个batch和 B.每个采样作为一个batch
A.如果用全部数据作为一个batch,优点有如下:
1. 这样理论上是可以得到全局收敛的
2. 可以用一些加速收敛算法,比如L-BFGS之类的
3. 便于并行计算
但是同样存在缺点:
如果数据集过大,训练会很慢的
B.每个采样作为一个batch,优点有如下
1. B方法在每个采样上的参数修正方向会与整体最优的方向有出入。这条看似是个缺点,实际上,DNN因为是非线性模型,有很多参数,现有目标函数会有很多局部极值,这就会导致模型不精确。因为A方法每次修正依赖于现有模型和所有数据,很难跳出这些局部极值,所以A方法是一种很依赖于初始模型的方法。而B方法基于每个采样去修正,修正幅度大了以后,就容易跳出这些局部极值,避免过拟合发生。B方法一般不依赖于初始模型,所以可以用来训练初始的神经网络。之后再用A方法或者下面介绍的C方法优化
2. 速度在大部分情况比A方法快。
缺点就是
1. 难以并行计算
2. 因为每次更新基于单个采样,很容易导致难以收敛。这个发生原因和优点1 是一样的。这种现象有时是优点有时也是缺点,主要取决于学习率的选择。
于是就有第三种情况,C:一部分数据作为一个batch,这种情况每次更新模型修正幅度没有A那么小,也没有B那么大,而且可以并行计算,所以速度也比较快。
一般用的时候,在非监督训练阶段,可以先用B方法创建初始模型,
然后在监督训练阶段,选择小batch size进行初步训练,让模型跳出局部极值,之后用大的batch size让模型收敛,这样一般能达到比较好的效果
参考:Dong Yu, Li Deng, Automatic Speech Recognition, Springer
发布于
2015-11-08 添加评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
2赞同
反对,不会显示你的姓名
匿名用户
wang、乔海军 赞同
其实是有影响的。batch数太小,而类别又比较多的时候,真的可能会导致loss函数震荡而不收敛,尤其是在你的网络比较复杂的时候。这个做过几个实验,但是没有详细的做,主要是针对googlenet,alexnet以及vgg几个模型(实验结果就是batch为32的时候,alex开始收敛,但是googlenet不收敛;提高batch size,googlenet开始收敛)。
就像lecun[note](http://cilvr.nyu.edu/lib/exe/fetch.php?media=deeplearning:dl-optimization.pdf)里说的一样,随机梯度下降不能像full
batch那样明显的保证收敛。一般而言,根据你的GPU显存,设置为最大,而且一般要求是8的倍数(比如32,128),这样,GPU内部的并行运算效率最高。
那么怎么选择batch number呢?就像刚才说的,8的倍数,然后是稍微大一点(一般而言)。另外一个方法,就是选择一部分数据,跑几个batch看看你的loss是不是在变小,选择一个合适的就可以了。
编辑于
2015-07-21 添加评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
0赞同
反对,不会显示你的姓名

糖遇小宝,工程狮
简而言之,步子太大容易扯着蛋...
发布于
2016-01-14 添加评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
0赞同
反对,不会显示你的姓名

tramphero,PHD在读,运动和科研
深度神经网络的优化是个nonconvex problem.所以基于SGD的训练batch size不能取过大。过大的batchsize的结果是网络很容易收敛到一些不好的局部最优点。。同样太小的batch也存在一些问题,比如训练速度很慢,训练不容易收敛等。。具体的batch size的选取和训练集的样本数目相关。。举个例子,比如在3小时的语音识别库(大约108万个样本)训练DNN,通常batch 取128..而在300小时的库上会取1024..
Batch_Size(批尺寸)是机器学习中一个重要参数,涉及诸多矛盾,下面逐一展开。
首先,为什么需要有 Batch_Size 这个参数?
Batch 的选择,首先决定的是下降的方向。如果数据集比较小,完全可以采用全数据集 ( Full Batch Learning )的形式,这样做至少有 2 个好处:其一,由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。其二,由于不同权重的梯度值差别巨大,因此选取一个全局的学习率很困难。
Full Batch Learning 可以使用Rprop 只基于梯度符号并且针对性单独更新各权值。
对于更大的数据集,以上 2 个好处又变成了 2 个坏处:其一,随着数据集的海量增长和内存限制,一次性载入所有的数据进来变得越来越不可行。其二,以 Rprop 的方式迭代,会由于各个 Batch 之间的采样差异性,各次梯度修正值相互抵消,无法修正。这才有了后来 RMSProp 的妥协方案。
既然 Full Batch Learning 并不适用大数据集,那么走向另一个极端怎么样?
所谓另一个极端,就是每次只训练一个样本,即 Batch_Size = 1。这就是在线学习(Online Learning)。线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆。对于多层神经元、非线性网络,在局部依然近似是抛物面。使用在线学习,每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。
可不可以选择一个适中的 Batch_Size 值呢?
当然可以,这就是批梯度下降法(Mini-batches Learning)。因为如果数据集足够充分,那么用一半(甚至少得多)的数据训练算出来的梯度与用全部数据训练出来的梯度是几乎一样的。
在合理范围内,增大 Batch_Size 有何好处?
内存利用率提高了,大矩阵乘法的并行化效率提高。
跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
盲目增大 Batch_Size 有何坏处?
内存利用率提高了,但是内存容量可能撑不住了。
跑完一次 epoch(全数据集)所需的迭代次数减少,要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢。
Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化。
调节 Batch_Size 对训练效果影响到底如何?
这里跑一个 LeNet 在 MNIST 数据集上的效果。MNIST 是一个手写体标准库,我使用的是 Theano 框架。这是一个 Python 的深度学习库。安装方便(几行命令而已),调试简单(自带
Profile),GPU / CPU 通吃,官方教程相当完备,支持模块十分丰富(除了
CNNs,更是支持 RBM / DBN / LSTM / RBM-RNN / SdA / MLPs)。在其上层有 Keras 封装,支持
GRU / JZS1, JZS2, JZS3 等较新结构,支持 Adagrad / Adadelta / RMSprop / Adam 等优化算法。
运行结果如上图所示,其中绝对时间做了标幺化处理。运行结果与上文分析相印证:
Batch_Size 太小,算法在 200 epoches 内不收敛。
随着 Batch_Size 增大,处理相同数据量的速度越快。
随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。
由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
欢迎一起讨论。
编辑于
2015-11-08 24
条评论 感谢
分享
收藏 • 没有帮助 •
举报
• 禁止转载
收起
11赞同
反对,不会显示你的姓名
纳米酱,理论物理跳深度学习坑ing
bonnenuit、Wang
Gu、高航 等人赞同
批训练的引入最大好处是针对非凸损失函数来做的, 毕竟非凸的情况下, 全样本就算工程上算的动, 也会卡在局部优上, 批表示了全样本的部分抽样实现, 相当于人为引入修正梯度上的采样噪声,使“一路不通找别路”更有可能搜索最优值。
楼上很多说到随机梯度收敛问题,物理上是这样的理解,
增加噪音扩大了你的行动范围,不会受限于局部。
然而过大的行动范围使得你的选择过多而”迷茫“。
这是一个损失函数局部优有“多坑人”和局部优“数目太多好难选”之间的竞争,竞争平衡点才是你最终的训练值。故此,最终的训练值是一个分布,大伙们一般取平均来证明自己的模型多牛逼。
物理上,就是能量(坑好深)和熵(选择多)的竞争结果,而且复杂系统中,能量和熵一辈子都在竞争,讨论自由能最小值在非凸问题上的意义,比直接讨论损失函数的最小值更有意义。
然而,这种牛逼,不仅依赖模型,而且依赖数据本身。调参需要预先建立竞争平衡的理论模型,单纯用软件刷指标只能用在某个数据集上,不具有转移性。纯浪费电!
这些观点在大部分复杂物理系统的采样,自旋玻璃的研究,蛋白质折叠构象搜索上,都有广泛的认识。但是工业界被凸优化影响过多了,除了特征选择和防止过拟合外可以通过直觉建立,遇到非凸优化问题,基本不可能拍脑袋调出一个通用的(如果数学上可以,物理上应该最先发现,然而并没有)。于是,即便在物理上遇到这种问题,目前很low,而且节省成本的方法就是烧钱增加计算蛮力点。矛盾到我笑尿了。
关于深度学习中的非凸优化,可以参考LeCun今年来对深度学习和自旋玻璃之间的联系,以及随机微分方程同增强采样之间的研究。
发布于
2015-11-10 2
条评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
1赞同
反对,不会显示你的姓名
年月Soiliml,打电竞!啃代码!搞算法!请叫我男孩子!
张馨宇 赞同
搞机器学习大忌就是不做实验想当然,话说这种问题题主跑几组不同的batch不就知道了...调参调参不调哪来的参~
另外,运用在不同的领域,不同的网络结构,不同的训练方法,batch的取法,用法和影响也不一样。不知道题主问的是哪种batch?
发布于
2015-11-30 5
条评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
0赞同
反对,不会显示你的姓名
宇文叔,我是认真的
我也看到过说理论上batchsize=1是最好的,不过实际上调的时候,可能因为我调参的能力比较有限,确实batchsize太小会出现网络收敛不稳定,最后结果比较差的情况,这个在ImageNet和其他数据库上都遇到过,而batchsize太大确实也会影响随机性的引入。目前一般调ImageNet的时候,大家都喜欢把显存占满,不过小一些的库,个人感觉还是应该大大小小都尝试一下。不知道各路大神有没有什么好办法指点一下。。
发布于
2015-07-28 添加评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
14赞同
反对,不会显示你的姓名
Yinghong
li,正在经历到目前为止的人生最重要的一年
PainKilller、李浩、陈程鹏 等人赞同
caffe小菜鸟也来答一下,感觉就是大batch size在显存能允许的情况下收敛速度是比较快的但有时的确会有陷入局部最小的情况,小batch size引入的随机性会更大些,有时候能有更好的效果,但是就是收敛速度慢一些……
还有就是除了batch size这个参数外,如果在solver setting中有momentum这个参数的话也要注意batch size的选取,具体参考一下caffe的tutorial
关于训练参数怎么选取可以参考以下一些文章:
Bengio的 Practical recommendations for gradient-based learning
http://link.springer.com/chapter/10.1007/978-3-642-35289-8_26
Lecun 和 Bottou的 Efficient Backprop
http://link.springer.com/chapter/10.1007/978-3-642-35289-8_3
还有一个代码上的细节,就是caffe的代码实现上选取一个batch的时候似乎是按着数据库的图片顺序选取输入图片的,所以在生成数据库的时候切记要shuffle一下图片顺序~
供题主参考,求大神指正~
发布于
2015-07-25 1
条评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
13赞同
反对,不会显示你的姓名
匿名用户
李浩、王小明、孔秋强 等人赞同
看你GPU显存,显存大就把batch size设大点,反之亦然。一般情况下对学习效果没影响。
补充点细节:
事实上从优化的角度来说最快的是纯stochastic,即batch size为1。
关于这一点参见Leon Bottou的分析:http://leon.bottou.org/publications/pdf/compstat-2010.pdf。当然,文中的分析适用于large
scale的情况下,但deep neural net适用的条件之一就是有大量数据。另外http://cilvr.nyu.edu/lib/exe/fetch.php?media=deeplearning:dl-optimization.pdf 的第11页也有比较stochastic和batch的优劣。
拿Yann Lecun在上述第二个链接第10页中举的toy example来说,如果事实上只有100个数据点,但有人各复制了10遍拿给你,你不知道。这时候你如果做batch gradient descent,更只用了100个点效果一样;而做stochastic gradient descent则相当于做了10个epoch。相近的计算量后者效果显然更好。至于mini batch,要你取的每个mini batch都很diverse的情况才会效果好。
当然你会说,现实中哪会有100个数据各重复10遍就直接拿来用的?没错,是不会,但现实中的数据,尤其是large scale的数据中,必然有大量的redundancy,不然你也很难学出有较好泛化性的model。因此stochastic在large scale总是优于batch。
那为什么还要用mini batch呢?这是由于GPU并行运算的性质,同时把多组数据传过去一起运算比一条一条运算来的快,因而mini batch只是为了充分利用GPU memory而做出的妥协。既然如此,batch size也调到刚好能塞进显存就差不多了。
编辑于
2015-07-21 1
条评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
0赞同
反对,不会显示你的姓名
Zhang
fusu,语音识别,声纹识别
可以考虑两个极端:A.全部数据作为一个batch和 B.每个采样作为一个batch
A.如果用全部数据作为一个batch,优点有如下:
1. 这样理论上是可以得到全局收敛的
2. 可以用一些加速收敛算法,比如L-BFGS之类的
3. 便于并行计算
但是同样存在缺点:
如果数据集过大,训练会很慢的
B.每个采样作为一个batch,优点有如下
1. B方法在每个采样上的参数修正方向会与整体最优的方向有出入。这条看似是个缺点,实际上,DNN因为是非线性模型,有很多参数,现有目标函数会有很多局部极值,这就会导致模型不精确。因为A方法每次修正依赖于现有模型和所有数据,很难跳出这些局部极值,所以A方法是一种很依赖于初始模型的方法。而B方法基于每个采样去修正,修正幅度大了以后,就容易跳出这些局部极值,避免过拟合发生。B方法一般不依赖于初始模型,所以可以用来训练初始的神经网络。之后再用A方法或者下面介绍的C方法优化
2. 速度在大部分情况比A方法快。
缺点就是
1. 难以并行计算
2. 因为每次更新基于单个采样,很容易导致难以收敛。这个发生原因和优点1 是一样的。这种现象有时是优点有时也是缺点,主要取决于学习率的选择。
于是就有第三种情况,C:一部分数据作为一个batch,这种情况每次更新模型修正幅度没有A那么小,也没有B那么大,而且可以并行计算,所以速度也比较快。
一般用的时候,在非监督训练阶段,可以先用B方法创建初始模型,
然后在监督训练阶段,选择小batch size进行初步训练,让模型跳出局部极值,之后用大的batch size让模型收敛,这样一般能达到比较好的效果
参考:Dong Yu, Li Deng, Automatic Speech Recognition, Springer
发布于
2015-11-08 添加评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
2赞同
反对,不会显示你的姓名
匿名用户
wang、乔海军 赞同
其实是有影响的。batch数太小,而类别又比较多的时候,真的可能会导致loss函数震荡而不收敛,尤其是在你的网络比较复杂的时候。这个做过几个实验,但是没有详细的做,主要是针对googlenet,alexnet以及vgg几个模型(实验结果就是batch为32的时候,alex开始收敛,但是googlenet不收敛;提高batch size,googlenet开始收敛)。
就像lecun[note](http://cilvr.nyu.edu/lib/exe/fetch.php?media=deeplearning:dl-optimization.pdf)里说的一样,随机梯度下降不能像full
batch那样明显的保证收敛。一般而言,根据你的GPU显存,设置为最大,而且一般要求是8的倍数(比如32,128),这样,GPU内部的并行运算效率最高。
那么怎么选择batch number呢?就像刚才说的,8的倍数,然后是稍微大一点(一般而言)。另外一个方法,就是选择一部分数据,跑几个batch看看你的loss是不是在变小,选择一个合适的就可以了。
编辑于
2015-07-21 添加评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
0赞同
反对,不会显示你的姓名
糖遇小宝,工程狮
简而言之,步子太大容易扯着蛋...
发布于
2016-01-14 添加评论 感谢
分享
收藏 • 没有帮助 •
举报
• 作者保留权利
0赞同
反对,不会显示你的姓名
tramphero,PHD在读,运动和科研
深度神经网络的优化是个nonconvex problem.所以基于SGD的训练batch size不能取过大。过大的batchsize的结果是网络很容易收敛到一些不好的局部最优点。。同样太小的batch也存在一些问题,比如训练速度很慢,训练不容易收敛等。。具体的batch size的选取和训练集的样本数目相关。。举个例子,比如在3小时的语音识别库(大约108万个样本)训练DNN,通常batch 取128..而在300小时的库上会取1024..

相关文章推荐
- 谈谈深度学习中的 Batch_Size Batch_Size(批尺寸)是机器学习中一个重要参数,涉及诸多矛盾,下面逐一展开。 首先,为什么需要有 Batch_Size 这个参数? Batch 的选
- 谈谈深度学习中的 Batch_Size
- 谈谈深度学习中的 Batch_Size
- 谈谈深度学习中的 Batch_Size
- 谈谈深度学习中的 Batch_Size
- 谈谈深度学习中的 Batch_Size
- 谈谈深度学习中的 Batch_Size
- 谈谈深度学习中的 Batch_Size和epoches
- 谈谈深度学习中的 Batch_Size
- 谈谈深度学习中的 Batch_Size
- 谈谈深度学习中的 Batch_Size
- 【深度学习】batch_size的作用
- 深度学习总结(四)——正则项系数、Batch_size设置
- 深度学习中的 Batch_Size的作用
- 深度学习-学习笔记--深度学习中的epochs,batch_size,iterations详解
- 深度学习中Batch_size相关问题汇总
- 2.深度学习中的batch_size的理解
- 深度学习中的 Batch_Size
- 深度学习Batch_Size认知
- 深度学习炼丹师的养成之路之——Batch size/Epoch/Learning Rate的设置和学习策略