SQL Server 中死锁产生的原因及解决办法
2016-09-01 11:58
405 查看
转载自:http://www.cnblogs.com/luluping/archive/2009/07/24/1530496.html
SQL Server中解决死锁的新方法介绍
数据库操作的死锁是不可避免的,本文并不打算讨论死锁如何产生,重点在于解决死锁,通过SQL
Server 2005, 现在似乎有了一种新的解决办法。
将下面的SQL语句放在两个不同的连接里面,并且在5秒内同时执行,将会发生死锁。
SQL Server对付死锁的办法是牺牲掉其中的一个,抛出异常,并且回滚事务。在SQL Server 2000,语句一旦发生异常,T-SQL将不会继续运行,上面被牺牲的连接中, print @#end tran@#语句将不会被运行,所以我们很难在SQL Server 2000的T-SQL中对死锁进行进一步的处理。
现在不同了,SQL Server 2005可以在T-SQL中对异常进行捕获,这样就给我们提供了一条处理死锁的途径:
下面利用的try ... catch来解决死锁。
解决方法当然就是重试,但捕获错误是前提。rollback后面的waitfor不可少,发生冲突后需要等待一段时间,@retry数目可以调整以应付不同的要求。
但是现在又面临一个新的问题: 错误被掩盖了,一但问题发生并且超过3次,异常却不会被抛出。SQL Server 2005 有一个RaiseError语句,可以抛出异常,但却不能直接抛出原来的异常,所以需要重新定义发生的错误,现在,解决方案变成了这样:
我希望将来SQL Server 2005能够直接抛出原有异常,比如提供一个无参数的RaiseError。
因此方案有点臃肿,但将死锁问题封装到T-SQL中有助于明确职责,提高高层系统的清晰度。现在,对于DataAccess的代码,或许再也不需要考虑死锁问题了
========================================================================
SQL Server2000中死锁经验总结
[align=left]虽然不能完全避免死锁,但可以使死锁的数量减至最少。将死锁减至最少可以增加事务的吞吐量并减少系统开销,因为只有很少的事务:[/align]
回滚,而回滚会取消事务执行的所有工作。
由于死锁时回滚而由应用程序重新提交。
[align=left]下列方法有助于最大限度地降低死锁:[/align]
按同一顺序访问对象。
避免事务中的用户交互。
保持事务简短并在一个批处理中。
使用低隔离级别。
使用绑定连接。
[align=left]按同一顺序访问对象[/align]
[align=left]如果所有并发事务按同一顺序访问对象,则发生死锁的可能性会降低。例如,如果两个并发事务获得 Supplier 表上的锁,然后获得 Part 表上的锁,则在其中一个事务完成之前,另一个事务被阻塞在 Supplier 表上。第一个事务提交或回滚后,第二个事务继续进行。不发生死锁。将存储过程用于所有的数据修改可以标准化访问对象的顺序。[/align]
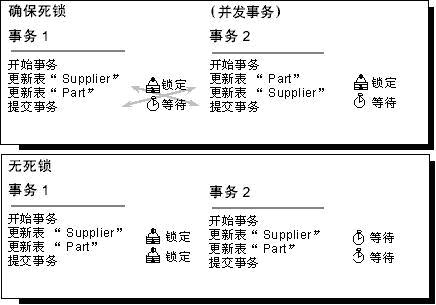
[align=left]避免事务中的用户交互[/align]
[align=left]避免编写包含用户交互的事务,因为运行没有用户交互的批处理的速度要远远快于用户手动响应查询的速度,例如答复应用程序请求参数的提示。例如,如果事务正在等待用户输入,而用户去吃午餐了或者甚至回家过周末了,则用户将此事务挂起使之不能完成。这样将降低系统的吞吐量,因为事务持有的任何锁只有在事务提交或回滚时才会释放。即使不出现死锁的情况,访问同一资源的其它事务也会被阻塞,等待该事务完成。[/align]
[align=left]保持事务简短并在一个批处理中[/align]
[align=left]在同一数据库中并发执行多个需要长时间运行的事务时通常发生死锁。事务运行时间越长,其持有排它锁或更新锁的时间也就越长,从而堵塞了其它活动并可能导致死锁。[/align]
[align=left]保持事务在一个批处理中,可以最小化事务的网络通信往返量,减少完成事务可能的延迟并释放锁。[/align]
[align=left]使用低隔离级别[/align]
[align=left]确定事务是否能在更低的隔离级别上运行。执行提交读允许事务读取另一个事务已读取(未修改)的数据,而不必等待第一个事务完成。使用较低的隔离级别(例如提交读)而不使用较高的隔离级别(例如可串行读)可以缩短持有共享锁的时间,从而降低了锁定争夺。[/align]
[align=left]使用绑定连接[/align]
[align=left]使用绑定连接使同一应用程序所打开的两个或多个连接可以相互合作。次级连接所获得的任何锁可以象由主连接获得的锁那样持有,反之亦然,因此不会相互阻塞[/align]
检测死锁
如果发生死锁了,我们怎么去检测具体发生死锁的是哪条SQL语句或存储过程?
这时我们可以使用以下存储过程来检测,就可以查出引起死锁的进程和SQL语句。SQL Server自带的系统存储过程sp_who和sp_lock也可以用来查找阻塞和死锁, 但没有这里介绍的方法好用。

use master
go
create procedure sp_who_lock
as
begin
declare @spid int,@bl int,
@intTransactionCountOnEntry int,
@intRowcount int,
@intCountProperties int,
@intCounter int
create table #tmp_lock_who (
id int identity(1,1),
spid smallint,
bl smallint)
IF @@ERROR<>0 RETURN @@ERROR
insert into #tmp_lock_who(spid,bl) select 0 ,blocked
from (select * from sysprocesses where blocked>0 ) a
where not exists(select * from (select * from sysprocesses where blocked>0 ) b
where a.blocked=spid)
union select spid,blocked from sysprocesses where blocked>0
IF @@ERROR<>0 RETURN @@ERROR
-- 找到临时表的记录数
select @intCountProperties = Count(*),@intCounter = 1
from #tmp_lock_who
IF @@ERROR<>0 RETURN @@ERROR
if @intCountProperties=0
select '现在没有阻塞和死锁信息' as message
-- 循环开始
while @intCounter <= @intCountProperties
begin
-- 取第一条记录
select @spid = spid,@bl = bl
from #tmp_lock_who where Id = @intCounter
begin
if @spid =0
select '引起数据库死锁的是: '+ CAST(@bl AS VARCHAR(10)) + '进程号,其执行的SQL语法如下'
else
select '进程号SPID:'+ CAST(@spid AS VARCHAR(10))+ '被' + '进程号SPID:'+ CAST(@bl AS VARCHAR(10)) +'阻塞,其当前进程执行的SQL语法如下'
DBCC INPUTBUFFER (@bl )
end
-- 循环指针下移
set @intCounter = @intCounter + 1
end
drop table #tmp_lock_who
return 0
end
杀死锁和进程
如何去手动的杀死进程和锁?最简单的办法,重新启动服务。但是这里要介绍一个存储过程,通过显式的调用,可以杀死进程和锁。
use master
go
if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[p_killspid]') and OBJECTPROPERTY(id, N'IsProcedure') = 1)
drop procedure [dbo].[p_killspid]
GO
create proc p_killspid
@dbname varchar(200) --要关闭进程的数据库名
as
declare @sql nvarchar(500)
declare @spid nvarchar(20)
declare #tb cursor for
select spid=cast(spid as varchar(20)) from master..sysprocesses where dbid=db_id(@dbname)
open #tb
fetch next from #tb into @spid
while @@fetch_status=0
begin
exec('kill '+@spid)
fetch next from #tb into @spid
end
close #tb
deallocate #tb
go
--用法
exec p_killspid 'newdbpy'
查看锁信息
如何查看系统中所有锁的详细信息?在企业管理管理器中,我们可以看到一些进程和锁的信息,这里介绍另外一种方法。
--查看锁信息
create table #t(req_spid int,obj_name sysname)
declare @s nvarchar(4000)
,@rid int,@dbname sysname,@id int,@objname sysname
declare tb cursor for
select distinct req_spid,dbname=db_name(rsc_dbid),rsc_objid
from master..syslockinfo where rsc_type in(4,5)
open tb
fetch next from tb into @rid,@dbname,@id
while @@fetch_status=0
begin
set @s='select @objname=name from ['+@dbname+']..sysobjects where id=@id'
exec sp_executesql @s,N'@objname sysname out,@id int',@objname out,@id
insert into #t values(@rid,@objname)
fetch next from tb into @rid,@dbname,@id
end
close tb
deallocate tb
select 进程id=a.req_spid
,数据库=db_name(rsc_dbid)
,类型=case rsc_type when 1 then 'NULL 资源(未使用)'
when 2 then '数据库'
when 3 then '文件'
when 4 then '索引'
when 5 then '表'
when 6 then '页'
when 7 then '键'
when 8 then '扩展盘区'
when 9 then 'RID(行 ID)'
when 10 then '应用程序'
end
,对象id=rsc_objid
,对象名=b.obj_name
,rsc_indid
from master..syslockinfo a left join #t b on a.req_spid=b.req_spid
go
drop table #t
总结
虽然不能完全避免死锁,但我们可以将死锁减至最少,并通过一定的方法来检测死锁。
-------------------------------------------------------------------------------------------------
SQL Server死锁的分析
SQL Server数据库发生死锁时不会像ORACLE那样自动生成一个跟踪文件。有时可以在[管理]->[当前活动] 里看到阻塞信息(有时SQL Server企业管理器会因为锁太多而没有响应).
设定跟踪1204:
USE MASTER
DBCC TRACEON (1204,-1)
显示当前启用的所有跟踪标记的状态:
DBCC TRACESTATUS(-1)
取消跟踪1204:
DBCC TRACEOFF (1204,-1)
在设定跟踪1204后,会在数据库的日志文件里显示SQL Server数据库死锁时一些信息。但那些信息很难看懂,需要对照SQL Server联机丛书仔细来看。根据PAG锁要找到相关数据库表的方法:
DBCC TRACEON (3604)
DBCC PAGE (db_id,file_id,page_no)
DBCC TRACEOFF (3604)
请参考sqlservercentral.com上更详细的讲解.但又从CSDN学到了一个找到死锁原因的方法。我稍加修改, 去掉了游标操作并增加了一些提示信息,写了一个系统存储过程sp_who_lock.sql。代码如下:
if exists (select * from dbo.sysobjects
where id = object_id(N'[dbo].[sp_who_lock]')
and OBJECTPROPERTY(id, N'IsProcedure') = 1)
drop procedure [dbo].[sp_who_lock]
GO
/********************************************************
// 学习到并改写
// 说明 : 查看数据库里阻塞和死锁情况
********************************************************/
use master
go
create procedure sp_who_lock
as
begin
declare @spid int,@bl int,
@intTransactionCountOnEntry int,
@intRowcount int,
@intCountProperties int,
@intCounter int
create table #tmp_lock_who (
id int identity(1,1),
spid smallint,
bl smallint)
IF @@ERROR<>0 RETURN @@ERROR
insert into #tmp_lock_who(spid,bl) select 0 ,blocked
from (select * from sysprocesses where blocked>0 ) a
where not exists(select * from (select * from sysprocesses
where blocked>0 ) b
where a.blocked=spid)
union select spid,blocked from sysprocesses where blocked>0
IF @@ERROR<>0 RETURN @@ERROR
-- 找到临时表的记录数
select @intCountProperties = Count(*),@intCounter = 1
from #tmp_lock_who
IF @@ERROR<>0 RETURN @@ERROR
if @intCountProperties=0
select '现在没有阻塞和死锁信息' as message
-- 循环开始
while @intCounter <= @intCountProperties
begin
-- 取第一条记录
select @spid = spid,@bl = bl
from #tmp_lock_who where Id = @intCounter
begin
if @spid =0
select '引起数据库死锁的是: '+ CAST(@bl AS VARCHAR(10))
+ '进程号,其执行的SQL语法如下'
else
select '进程号SPID:'+ CAST(@spid AS VARCHAR(10))+ '被'
+ '进程号SPID:'+ CAST(@bl AS VARCHAR(10)) +'阻塞,其当前进程执行的SQL语法如下'
DBCC INPUTBUFFER (@bl )
end
-- 循环指针下移
set @intCounter = @intCounter + 1
end
drop table #tmp_lock_who
return 0
end
需要的时候直接调用:
sp_who_lock
就可以查出引起死锁的进程和SQL语句.
SQL Server自带的系统存储过程sp_who和sp_lock也可以用来查找阻塞和死锁, 但没有这里介绍的方法好用。如果想知道其它tracenum参数的含义,请看http://www.sqlservercentral.com/文章
我们还可以设置锁的超时时间(单位是毫秒), 来缩短死锁可能影响的时间范围:
例如:
use master
seelct @@lock_timeout
set lock_timeout 900000
-- 15分钟
seelct @@lock_timeout
其实所有的死锁最深层的原因就是一个:资源竞争
表现一:
一个用户A 访问表A(锁住了表A),然后又访问表B
另一个用户B 访问表B(锁住了表B),然后企图访问表A
这时用户A由于用户B已经锁住表B,它必须等待用户B释放表B,才能继续,好了他老人家就只好老老实实在这等了
同样用户B要等用户A释放表A才能继续这就死锁了
解决方法:
这种死锁是由于你的程序的BUG产生的,除了调整你的程序的逻辑别无他法
仔细分析你程序的逻辑,
1:尽量避免同时锁定两个资源
2: 必须同时锁定两个资源时,要保证在任何时刻都应该按照相同的顺序来锁定资源.
表现二:
用户A读一条纪录,然后修改该条纪录
这是用户B修改该条纪录
这里用户A的事务里锁的性质由共享锁企图上升到独占锁(for update),而用户B里的独占锁由于A有共享锁存在所以必须等A释
放掉共享锁,而A由于B的独占锁而无法上升的独占锁也就不可能释放共享锁,于是出现了死锁。
这种死锁比较隐蔽,但其实在稍大点的项目中经常发生。
解决方法:
让用户A的事务(即先读后写类型的操作),在select 时就是用Update lock
语法如下:
select * from table1 with(updlock) where ....
如何将数据库中被锁表解锁
作者:佚名 文章来源:未知 点击数:106 更新时间:2005-12-25
我们在操作数据库的时候,有时候会由于操作不当引起数据库表被锁定,这么我们经常不知所措,不知怎么给这些表解锁,在pl/sql Developer工具的的菜单“tools”里面的“sessions”可以查询现在存在的会话,但是我们很难找到那个会话被锁定了,想找到所以被锁的会话就更难了,下面这叫查询语句可以查询出所以被锁的会话。如下:
SELECT sn.username, m.SID,sn.SERIAL#, m.TYPE,
DECODE (m.lmode,
0, 'None',
1, 'Null',
2, 'Row Share',
3, 'Row Excl.',
4, 'Share',
5, 'S/Row Excl.',
6, 'Exclusive',
lmode, LTRIM (TO_CHAR (lmode, '990'))
) lmode,
DECODE (m.request,
0, 'None',
1, 'Null',
2, 'Row Share',
3, 'Row Excl.',
4, 'Share',
5, 'S/Row Excl.',
6, 'Exclusive',
request, LTRIM (TO_CHAR (m.request, '990'))
) request,
m.id1, m.id2
FROM v$session sn, v$lock m
WHERE (sn.SID = m.SID AND m.request != 0) --存在锁请求,即被阻塞
OR ( sn.SID = m.SID --不存在锁请求,但是锁定的对象被其他会话请求锁定
AND m.request = 0
AND lmode != 4
AND (id1, id2) IN (
SELECT s.id1, s.id2
FROM v$lock s
WHERE request != 0 AND s.id1 = m.id1
AND s.id2 = m.id2)
)
ORDER BY id1, id2, m.request;
通过以上查询知道了sid和 SERIAL#就可以开杀了
alter system kill session 'sid,SERIAL#';
SQL Server中解决死锁的新方法介绍
数据库操作的死锁是不可避免的,本文并不打算讨论死锁如何产生,重点在于解决死锁,通过SQL
Server 2005, 现在似乎有了一种新的解决办法。
将下面的SQL语句放在两个不同的连接里面,并且在5秒内同时执行,将会发生死锁。
use Northwindbegin tran insert into Orders(CustomerId) values(@#ALFKI@#) waitfor delay @#00:00:05@# select * from Orders where CustomerId = @#ALFKI@#commitprint @#end tran@# |
SQL Server对付死锁的办法是牺牲掉其中的一个,抛出异常,并且回滚事务。在SQL Server 2000,语句一旦发生异常,T-SQL将不会继续运行,上面被牺牲的连接中, print @#end tran@#语句将不会被运行,所以我们很难在SQL Server 2000的T-SQL中对死锁进行进一步的处理。
现在不同了,SQL Server 2005可以在T-SQL中对异常进行捕获,这样就给我们提供了一条处理死锁的途径:
下面利用的try ... catch来解决死锁。
SET XACT_ABORT ONdeclare @r intset @r = 1while @r <= 3begin begin tran begin try insert into Orders(CustomerId) values(@#ALFKI@#) waitfor delay @#00:00:05@# select * from Orders where CustomerId = @#ALFKI@# commit break end try begin catch rollback waitfor delay @#00:00:03@# set @r = @r + 1 continue end catchend |
解决方法当然就是重试,但捕获错误是前提。rollback后面的waitfor不可少,发生冲突后需要等待一段时间,@retry数目可以调整以应付不同的要求。
但是现在又面临一个新的问题: 错误被掩盖了,一但问题发生并且超过3次,异常却不会被抛出。SQL Server 2005 有一个RaiseError语句,可以抛出异常,但却不能直接抛出原来的异常,所以需要重新定义发生的错误,现在,解决方案变成了这样:
declare @r intset @r = 1while @r <= 3begin begin tran begin try insert into Orders(CustomerId) values(@#ALFKI@#) waitfor delay @#00:00:05@# select * from Orders where CustomerId = @#ALFKI@# commit break end try begin catch rollback waitfor delay @#00:00:03@# set @r = @r + 1 continue end catchendif ERROR_NUMBER() <> 0begin declare @ErrorMessage nvarchar(4000); declare @ErrorSeverity int; declare @ErrorState int; select @ErrorMessage = ERROR_MESSAGE(), @ErrorSeverity = ERROR_SEVERITY(), @ErrorState = ERROR_STATE(); raiserror (@ErrorMessage, @ErrorSeverity, @ErrorState );end |
我希望将来SQL Server 2005能够直接抛出原有异常,比如提供一个无参数的RaiseError。
因此方案有点臃肿,但将死锁问题封装到T-SQL中有助于明确职责,提高高层系统的清晰度。现在,对于DataAccess的代码,或许再也不需要考虑死锁问题了
========================================================================
SQL Server2000中死锁经验总结
[align=left]虽然不能完全避免死锁,但可以使死锁的数量减至最少。将死锁减至最少可以增加事务的吞吐量并减少系统开销,因为只有很少的事务:[/align]
回滚,而回滚会取消事务执行的所有工作。
由于死锁时回滚而由应用程序重新提交。
[align=left]下列方法有助于最大限度地降低死锁:[/align]
按同一顺序访问对象。
避免事务中的用户交互。
保持事务简短并在一个批处理中。
使用低隔离级别。
使用绑定连接。
[align=left]按同一顺序访问对象[/align]
[align=left]如果所有并发事务按同一顺序访问对象,则发生死锁的可能性会降低。例如,如果两个并发事务获得 Supplier 表上的锁,然后获得 Part 表上的锁,则在其中一个事务完成之前,另一个事务被阻塞在 Supplier 表上。第一个事务提交或回滚后,第二个事务继续进行。不发生死锁。将存储过程用于所有的数据修改可以标准化访问对象的顺序。[/align]
[align=left]避免事务中的用户交互[/align]
[align=left]避免编写包含用户交互的事务,因为运行没有用户交互的批处理的速度要远远快于用户手动响应查询的速度,例如答复应用程序请求参数的提示。例如,如果事务正在等待用户输入,而用户去吃午餐了或者甚至回家过周末了,则用户将此事务挂起使之不能完成。这样将降低系统的吞吐量,因为事务持有的任何锁只有在事务提交或回滚时才会释放。即使不出现死锁的情况,访问同一资源的其它事务也会被阻塞,等待该事务完成。[/align]
[align=left]保持事务简短并在一个批处理中[/align]
[align=left]在同一数据库中并发执行多个需要长时间运行的事务时通常发生死锁。事务运行时间越长,其持有排它锁或更新锁的时间也就越长,从而堵塞了其它活动并可能导致死锁。[/align]
[align=left]保持事务在一个批处理中,可以最小化事务的网络通信往返量,减少完成事务可能的延迟并释放锁。[/align]
[align=left]使用低隔离级别[/align]
[align=left]确定事务是否能在更低的隔离级别上运行。执行提交读允许事务读取另一个事务已读取(未修改)的数据,而不必等待第一个事务完成。使用较低的隔离级别(例如提交读)而不使用较高的隔离级别(例如可串行读)可以缩短持有共享锁的时间,从而降低了锁定争夺。[/align]
[align=left]使用绑定连接[/align]
[align=left]使用绑定连接使同一应用程序所打开的两个或多个连接可以相互合作。次级连接所获得的任何锁可以象由主连接获得的锁那样持有,反之亦然,因此不会相互阻塞[/align]
检测死锁
如果发生死锁了,我们怎么去检测具体发生死锁的是哪条SQL语句或存储过程?
这时我们可以使用以下存储过程来检测,就可以查出引起死锁的进程和SQL语句。SQL Server自带的系统存储过程sp_who和sp_lock也可以用来查找阻塞和死锁, 但没有这里介绍的方法好用。
use master
go
create procedure sp_who_lock
as
begin
declare @spid int,@bl int,
@intTransactionCountOnEntry int,
@intRowcount int,
@intCountProperties int,
@intCounter int
create table #tmp_lock_who (
id int identity(1,1),
spid smallint,
bl smallint)
IF @@ERROR<>0 RETURN @@ERROR
insert into #tmp_lock_who(spid,bl) select 0 ,blocked
from (select * from sysprocesses where blocked>0 ) a
where not exists(select * from (select * from sysprocesses where blocked>0 ) b
where a.blocked=spid)
union select spid,blocked from sysprocesses where blocked>0
IF @@ERROR<>0 RETURN @@ERROR
-- 找到临时表的记录数
select @intCountProperties = Count(*),@intCounter = 1
from #tmp_lock_who
IF @@ERROR<>0 RETURN @@ERROR
if @intCountProperties=0
select '现在没有阻塞和死锁信息' as message
-- 循环开始
while @intCounter <= @intCountProperties
begin
-- 取第一条记录
select @spid = spid,@bl = bl
from #tmp_lock_who where Id = @intCounter
begin
if @spid =0
select '引起数据库死锁的是: '+ CAST(@bl AS VARCHAR(10)) + '进程号,其执行的SQL语法如下'
else
select '进程号SPID:'+ CAST(@spid AS VARCHAR(10))+ '被' + '进程号SPID:'+ CAST(@bl AS VARCHAR(10)) +'阻塞,其当前进程执行的SQL语法如下'
DBCC INPUTBUFFER (@bl )
end
-- 循环指针下移
set @intCounter = @intCounter + 1
end
drop table #tmp_lock_who
return 0
end
杀死锁和进程
如何去手动的杀死进程和锁?最简单的办法,重新启动服务。但是这里要介绍一个存储过程,通过显式的调用,可以杀死进程和锁。
use master
go
if exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[p_killspid]') and OBJECTPROPERTY(id, N'IsProcedure') = 1)
drop procedure [dbo].[p_killspid]
GO
create proc p_killspid
@dbname varchar(200) --要关闭进程的数据库名
as
declare @sql nvarchar(500)
declare @spid nvarchar(20)
declare #tb cursor for
select spid=cast(spid as varchar(20)) from master..sysprocesses where dbid=db_id(@dbname)
open #tb
fetch next from #tb into @spid
while @@fetch_status=0
begin
exec('kill '+@spid)
fetch next from #tb into @spid
end
close #tb
deallocate #tb
go
--用法
exec p_killspid 'newdbpy'
查看锁信息
如何查看系统中所有锁的详细信息?在企业管理管理器中,我们可以看到一些进程和锁的信息,这里介绍另外一种方法。
--查看锁信息
create table #t(req_spid int,obj_name sysname)
declare @s nvarchar(4000)
,@rid int,@dbname sysname,@id int,@objname sysname
declare tb cursor for
select distinct req_spid,dbname=db_name(rsc_dbid),rsc_objid
from master..syslockinfo where rsc_type in(4,5)
open tb
fetch next from tb into @rid,@dbname,@id
while @@fetch_status=0
begin
set @s='select @objname=name from ['+@dbname+']..sysobjects where id=@id'
exec sp_executesql @s,N'@objname sysname out,@id int',@objname out,@id
insert into #t values(@rid,@objname)
fetch next from tb into @rid,@dbname,@id
end
close tb
deallocate tb
select 进程id=a.req_spid
,数据库=db_name(rsc_dbid)
,类型=case rsc_type when 1 then 'NULL 资源(未使用)'
when 2 then '数据库'
when 3 then '文件'
when 4 then '索引'
when 5 then '表'
when 6 then '页'
when 7 then '键'
when 8 then '扩展盘区'
when 9 then 'RID(行 ID)'
when 10 then '应用程序'
end
,对象id=rsc_objid
,对象名=b.obj_name
,rsc_indid
from master..syslockinfo a left join #t b on a.req_spid=b.req_spid
go
drop table #t
总结
虽然不能完全避免死锁,但我们可以将死锁减至最少,并通过一定的方法来检测死锁。
-------------------------------------------------------------------------------------------------
SQL Server死锁的分析
SQL Server数据库发生死锁时不会像ORACLE那样自动生成一个跟踪文件。有时可以在[管理]->[当前活动] 里看到阻塞信息(有时SQL Server企业管理器会因为锁太多而没有响应).
设定跟踪1204:
USE MASTER
DBCC TRACEON (1204,-1)
显示当前启用的所有跟踪标记的状态:
DBCC TRACESTATUS(-1)
取消跟踪1204:
DBCC TRACEOFF (1204,-1)
在设定跟踪1204后,会在数据库的日志文件里显示SQL Server数据库死锁时一些信息。但那些信息很难看懂,需要对照SQL Server联机丛书仔细来看。根据PAG锁要找到相关数据库表的方法:
DBCC TRACEON (3604)
DBCC PAGE (db_id,file_id,page_no)
DBCC TRACEOFF (3604)
请参考sqlservercentral.com上更详细的讲解.但又从CSDN学到了一个找到死锁原因的方法。我稍加修改, 去掉了游标操作并增加了一些提示信息,写了一个系统存储过程sp_who_lock.sql。代码如下:
if exists (select * from dbo.sysobjects
where id = object_id(N'[dbo].[sp_who_lock]')
and OBJECTPROPERTY(id, N'IsProcedure') = 1)
drop procedure [dbo].[sp_who_lock]
GO
/********************************************************
// 学习到并改写
// 说明 : 查看数据库里阻塞和死锁情况
********************************************************/
use master
go
create procedure sp_who_lock
as
begin
declare @spid int,@bl int,
@intTransactionCountOnEntry int,
@intRowcount int,
@intCountProperties int,
@intCounter int
create table #tmp_lock_who (
id int identity(1,1),
spid smallint,
bl smallint)
IF @@ERROR<>0 RETURN @@ERROR
insert into #tmp_lock_who(spid,bl) select 0 ,blocked
from (select * from sysprocesses where blocked>0 ) a
where not exists(select * from (select * from sysprocesses
where blocked>0 ) b
where a.blocked=spid)
union select spid,blocked from sysprocesses where blocked>0
IF @@ERROR<>0 RETURN @@ERROR
-- 找到临时表的记录数
select @intCountProperties = Count(*),@intCounter = 1
from #tmp_lock_who
IF @@ERROR<>0 RETURN @@ERROR
if @intCountProperties=0
select '现在没有阻塞和死锁信息' as message
-- 循环开始
while @intCounter <= @intCountProperties
begin
-- 取第一条记录
select @spid = spid,@bl = bl
from #tmp_lock_who where Id = @intCounter
begin
if @spid =0
select '引起数据库死锁的是: '+ CAST(@bl AS VARCHAR(10))
+ '进程号,其执行的SQL语法如下'
else
select '进程号SPID:'+ CAST(@spid AS VARCHAR(10))+ '被'
+ '进程号SPID:'+ CAST(@bl AS VARCHAR(10)) +'阻塞,其当前进程执行的SQL语法如下'
DBCC INPUTBUFFER (@bl )
end
-- 循环指针下移
set @intCounter = @intCounter + 1
end
drop table #tmp_lock_who
return 0
end
需要的时候直接调用:
sp_who_lock
就可以查出引起死锁的进程和SQL语句.
SQL Server自带的系统存储过程sp_who和sp_lock也可以用来查找阻塞和死锁, 但没有这里介绍的方法好用。如果想知道其它tracenum参数的含义,请看http://www.sqlservercentral.com/文章
我们还可以设置锁的超时时间(单位是毫秒), 来缩短死锁可能影响的时间范围:
例如:
use master
seelct @@lock_timeout
set lock_timeout 900000
-- 15分钟
seelct @@lock_timeout
其实所有的死锁最深层的原因就是一个:资源竞争
表现一:
一个用户A 访问表A(锁住了表A),然后又访问表B
另一个用户B 访问表B(锁住了表B),然后企图访问表A
这时用户A由于用户B已经锁住表B,它必须等待用户B释放表B,才能继续,好了他老人家就只好老老实实在这等了
同样用户B要等用户A释放表A才能继续这就死锁了
解决方法:
这种死锁是由于你的程序的BUG产生的,除了调整你的程序的逻辑别无他法
仔细分析你程序的逻辑,
1:尽量避免同时锁定两个资源
2: 必须同时锁定两个资源时,要保证在任何时刻都应该按照相同的顺序来锁定资源.
表现二:
用户A读一条纪录,然后修改该条纪录
这是用户B修改该条纪录
这里用户A的事务里锁的性质由共享锁企图上升到独占锁(for update),而用户B里的独占锁由于A有共享锁存在所以必须等A释
放掉共享锁,而A由于B的独占锁而无法上升的独占锁也就不可能释放共享锁,于是出现了死锁。
这种死锁比较隐蔽,但其实在稍大点的项目中经常发生。
解决方法:
让用户A的事务(即先读后写类型的操作),在select 时就是用Update lock
语法如下:
select * from table1 with(updlock) where ....
如何将数据库中被锁表解锁
作者:佚名 文章来源:未知 点击数:106 更新时间:2005-12-25
我们在操作数据库的时候,有时候会由于操作不当引起数据库表被锁定,这么我们经常不知所措,不知怎么给这些表解锁,在pl/sql Developer工具的的菜单“tools”里面的“sessions”可以查询现在存在的会话,但是我们很难找到那个会话被锁定了,想找到所以被锁的会话就更难了,下面这叫查询语句可以查询出所以被锁的会话。如下:
SELECT sn.username, m.SID,sn.SERIAL#, m.TYPE,
DECODE (m.lmode,
0, 'None',
1, 'Null',
2, 'Row Share',
3, 'Row Excl.',
4, 'Share',
5, 'S/Row Excl.',
6, 'Exclusive',
lmode, LTRIM (TO_CHAR (lmode, '990'))
) lmode,
DECODE (m.request,
0, 'None',
1, 'Null',
2, 'Row Share',
3, 'Row Excl.',
4, 'Share',
5, 'S/Row Excl.',
6, 'Exclusive',
request, LTRIM (TO_CHAR (m.request, '990'))
) request,
m.id1, m.id2
FROM v$session sn, v$lock m
WHERE (sn.SID = m.SID AND m.request != 0) --存在锁请求,即被阻塞
OR ( sn.SID = m.SID --不存在锁请求,但是锁定的对象被其他会话请求锁定
AND m.request = 0
AND lmode != 4
AND (id1, id2) IN (
SELECT s.id1, s.id2
FROM v$lock s
WHERE request != 0 AND s.id1 = m.id1
AND s.id2 = m.id2)
)
ORDER BY id1, id2, m.request;
通过以上查询知道了sid和 SERIAL#就可以开杀了
alter system kill session 'sid,SERIAL#';

相关文章推荐
- SQL Server 中死锁产生的原因及解决办法
- 总结 SQL Server 中死锁产生的原因及解决办法
- SQL Server 中死锁产生的原因及解决办法
- SQL Server死锁产生原因及解决办法
- SQL Server中死锁产生的原因及解决办法
- SQL Server 中死锁产生的原因及解决办法
- SQL Server死锁产生原因及解决办法
- SQL Server死锁产生原因及解决办法
- SQL Server死锁产生原因及解决办法
- SQL Server 中死锁产生的原因及解决办法
- SQL Server死锁产生原因及解决办法
- SQL Server死锁产生原因及解决办法 .
- 死锁产生的原因和解决办法
- 死锁产生的原因,必要条件及解决办法
- SQL Server中死锁的原因及解决办法
- 中死锁产生的原因及解决办法
- 死锁产生的原因和解决办法
- SQL Server中死锁的原因及解决办法
- mysql数据库死锁的产生原因及解决办法
- 总结中死锁产生的原因及解决办法