大数据量点集构建汉密尔顿路径算法分析
2016-08-20 10:08
344 查看
博主在去年做利用Google的word2vec做深度学习的时候,需要将大量的POI数据点连接成汉密尔顿路径,并形成语料库进行进一步分析。何谓汉密尔顿路径,通俗一点地讲,就是将一些点不重复地全部串起来,使得连接这些点的折线段的长度最短。数学形式表达如下:

这种问题属于NP问题,蚁群算法、遗传算法、模拟退火算法都能对这种问题提出一种近似最优解,然而对上述算法不熟悉的童鞋必定一头雾水,因此,本文将讲解一种最简单易懂的算法---我称之为“暴力解法”。顾名思义,就是一次次枚举,通过比较路径长度来选取适当的节点顺序。算法介绍如下:
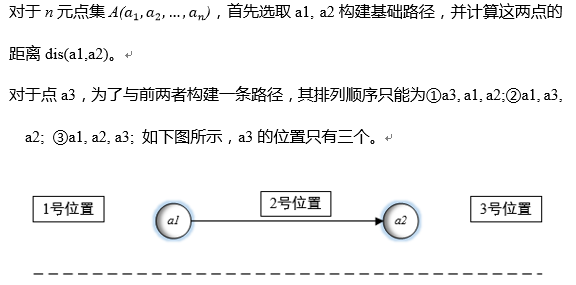
对于以上三种情况,其构建的路径和长度示意图分别如下:
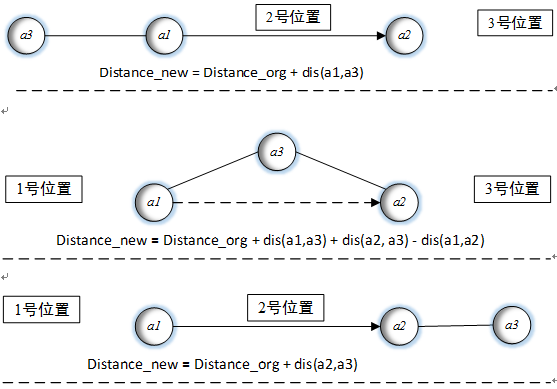

因此在处理这样的问题时,需要计算任意两点之间的距离,为了便于计算,在计算之前将其距离矩阵计算出来是一种明智的选择,因为后期均为加减法和逻辑判断,将极大地缩短时间。
然而。
是的,当数据量非常大时,构建距离矩阵一次申请内存将爆,例如,我在计算88w个点时,需要申请88w*88w/2*sizeof(float),这是个非常巨大的数字,远远超出了Windows下4G内存的限制。因此,常用的解决方法有两个:第一,拿去linux下运行;第二,修改逻辑,不要一次申请巨大的内存计算距离矩阵,而是通过牺牲时间来减小空间负载。本文着重讲解第二种解决方法,具体思路如下:
对于插入一个点ak的计算,需要查询k个位置,而其中用到的距离只有点ak到之前路径l上个点的距离和l上相邻两点之间的距离。因此,可以在每次搜索开始前,计算出这两种距离。
事实上,l路径上相邻两点之间的距离也无需每次都计算,这是因为,插入ak时的路径l上相邻两点之间的距离链表与插入ak-1时的路径l上相邻两点的距离链表绝大部分相同,除了插入点处有所改变。因此,在上次修改基础上,还能继续进行优化,即,在构建路径节点序列的同时构建节点距离序列,在插入节点时更新节点距离序列,这样,每次插入点时,秩序计算该点与原先路径上各点的距离,空间复杂度变为:2
+ 3+ 4 + … + n-1 = (n+1)(n-2)/2. 当然,这种牺牲时间成本减小空间负载方法的必然结果就是长时间的运行。漫长的等待ing.
当然,本文还计划用OpenMP加速计算,但是因为对链表的插入删除操作采用并行计算会打乱代码的逻辑,因此 仅在计算两点间距离时使用,且这样的多线程计算在数据量少时优势并不明显,可能更低,但是随着路径长度的增大,需要计算的两点间距离以万、甚至是亿计算时,openMP的优势就发挥出来了。i核的CPU计算效率能达到单线程的i倍。
以下贴出代码和运行。
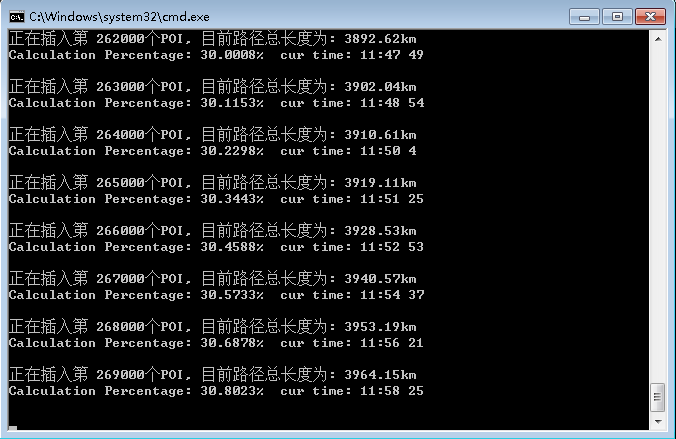

这样生成的语料就能通过分析其上下文来做进一步分析啦。
这种问题属于NP问题,蚁群算法、遗传算法、模拟退火算法都能对这种问题提出一种近似最优解,然而对上述算法不熟悉的童鞋必定一头雾水,因此,本文将讲解一种最简单易懂的算法---我称之为“暴力解法”。顾名思义,就是一次次枚举,通过比较路径长度来选取适当的节点顺序。算法介绍如下:
对于以上三种情况,其构建的路径和长度示意图分别如下:
因此在处理这样的问题时,需要计算任意两点之间的距离,为了便于计算,在计算之前将其距离矩阵计算出来是一种明智的选择,因为后期均为加减法和逻辑判断,将极大地缩短时间。
然而。
是的,当数据量非常大时,构建距离矩阵一次申请内存将爆,例如,我在计算88w个点时,需要申请88w*88w/2*sizeof(float),这是个非常巨大的数字,远远超出了Windows下4G内存的限制。因此,常用的解决方法有两个:第一,拿去linux下运行;第二,修改逻辑,不要一次申请巨大的内存计算距离矩阵,而是通过牺牲时间来减小空间负载。本文着重讲解第二种解决方法,具体思路如下:
对于插入一个点ak的计算,需要查询k个位置,而其中用到的距离只有点ak到之前路径l上个点的距离和l上相邻两点之间的距离。因此,可以在每次搜索开始前,计算出这两种距离。
事实上,l路径上相邻两点之间的距离也无需每次都计算,这是因为,插入ak时的路径l上相邻两点之间的距离链表与插入ak-1时的路径l上相邻两点的距离链表绝大部分相同,除了插入点处有所改变。因此,在上次修改基础上,还能继续进行优化,即,在构建路径节点序列的同时构建节点距离序列,在插入节点时更新节点距离序列,这样,每次插入点时,秩序计算该点与原先路径上各点的距离,空间复杂度变为:2
+ 3+ 4 + … + n-1 = (n+1)(n-2)/2. 当然,这种牺牲时间成本减小空间负载方法的必然结果就是长时间的运行。漫长的等待ing.
当然,本文还计划用OpenMP加速计算,但是因为对链表的插入删除操作采用并行计算会打乱代码的逻辑,因此 仅在计算两点间距离时使用,且这样的多线程计算在数据量少时优势并不明显,可能更低,但是随着路径长度的增大,需要计算的两点间距离以万、甚至是亿计算时,openMP的优势就发挥出来了。i核的CPU计算效率能达到单线程的i倍。
以下贴出代码和运行。
#ifndef WHOLEPOIPATH_H
#define WHOLEPOIPATH_H
#include <QtCore>
#include <iostream>
#include <windows.h>
using namespace std;
#define NUM_PARCLE 1
struct POI
{
long nFIDPOI;
float dlon;
float dlat;
QString classType;
};
#define EARTH_RADIUS 6378.137
#define PI 3.141592654
#define GET_ARRAY_LEN(array,len){len = (sizeof(array)/sizeof(array[0]));}
class WholePOIPath
{
public:
WholePOIPath(QString strFile1, QString strFile2)
{
outputfile = strFile2;
getPOIs2(strFile1);
}
~WholePOIPath(){}
void getPOIs2(QString strPath)
{
if (!QFile::exists(strPath.toStdString().c_str()))
{
cout<<"data file is not exist!"<<endl;
system("pause");
}
QFile inFile(strPath.toStdString().c_str());
if (!inFile.open(QIODevice::ReadOnly))
{
cout<<"data file open error!"<<endl;
system("pause");
}
QTextStream _in1(&inFile);
QString smsg = _in1.readLine();
mvPOI.clear();
cout << "Loading Data...\n";
while (!_in1.atEnd())
{
smsg = _in1.readLine();
QStringList slist = smsg.split(",");
POI _poi;
//存放转移数据
_poi.nFIDPOI = slist[1].trimmed().toLong();
_poi.dlon = slist[2].trimmed().toFloat();
_poi.dlat = slist[3].trimmed().toFloat();
_poi.classType = slist[4].trimmed();
//_poi.nFIDParcle = slist[5].trimmed().toInt();
mvPOI.append(_poi);
}
inFile.close();
cout<<"Read Data File Succeed! "<<endl;
}
//转弧度
float rad(float d)
{
return d * PI / 180.0;
}
//返回公里距离
float GetDistance(float lat1, float lng1, float lat2, float lng2)
{
float radLat1 = rad(lat1);
float radLat2 = rad(lat2);
float radLon1 = rad(lng1);
float radLon2 = rad(lng2);
float a = radLat1 - radLat2;
float b = radLon1 - radLon2;
float s = 2 * asinf(sqrtf(sin(a/2)*sin(a/2) + cos(radLat1)*cos(radLat2)*sin(b/2)*sin(b/2)));
s = s * EARTH_RADIUS;
return s;
}
//计算一组点组合的最短路径
void ShortestPath(QList<POI>& POI_Input,QList<POI>& POI_order, long n)
{
POI_order.clear();
if (n <= 2)
{
POI_order = POI_Input;
return;
}
long i, j, k;
QList<long> pdS;
QList<float> pDisDs; //构建路径上相邻两点的距离;
for (i = 0; i < 2; i ++)
{
pdS.append(0);
}
for (i = 0; i < n; i ++)
{
POI_order.append(POI_Input[i]);
}
pdS[0]= 0,pdS[1]=1;
float dLen = GetDistance(POI_Input[0].dlat,POI_Input[0].dlon,POI_Input[1].dlat,POI_Input[1].dlon); //最后构建的路径长度
pDisDs.append(dLen);
pDisDs[0] = dLen;
cout << "初始化汉密尔路径成功..."<<endl;
float dtempLencompare = dLen;
float dtempLen; //用于跟dLen长度比较的路径
float dtempLen1, dtempLen2, dtempLen3; //短路径
cout << "Tring to find the shortest way...\n\n";
long indInsertInto;
for( i = 2; i < n; i ++)
{
float *pDisToPoint = new float[i];
#pragma omp parallel for
for (k = 0; k < i; k ++)
{
pDisToPoint[k] = GetDistance(POI_Input[i].dlat,POI_Input[i].dlon,POI_Input[pdS[k]].dlat,POI_Input[pdS[k]].dlon); //第i点与第k点之间的距离;
}
dLen = dtempLencompare;
for( j = 0; j <= i; j ++ )
{
if(j == 0)
{
dtempLen = dLen + pDisToPoint[0];
dtempLencompare = dtempLen; //第一个距离作为每次比较的起始;
pdS.insert(0, i); //将该点FID作为路径起点,此时路径中已经加入了一点;
}
else if(j > 0 && j < i)
{
dtempLen = dLen + pDisToPoint[j-1] + pDisToPoint[j] - pDisDs[j-1];
if (dtempLen <= dtempLencompare)//如果插入中间的位置使得距离最短;
{
indInsertInto = pdS.indexOf(i);
pdS.removeAt(indInsertInto); //删除之前插入的点,路径长度减少一点;
dtempLencompare = dtempLen; //更新最短路径长度;
pdS.insert(j, i); //将该点FID插入路径中适当的位置,此时路径中已经加入了一点;
}
}
else if(j == i)
{
dtempLen = dLen + pDisToPoint[j-1];
if (dtempLen <= dtempLencompare)//如果插入最后的位置使得距离最短;
{
indInsertInto = pdS.indexOf(i);
pdS.removeAt(indInsertInto); //删除之前插入的点,路径长度减少一点;
dtempLencompare = dtempLen; //更新最短路径长度;
pdS.insert(j, i); //将该点FID插入路径中最后的位置,此时路径中已经加入了一点;
}
}
}
long ind = pdS.indexOf(i); //最后i点插入的位置;
if (ind == 0)
{
pDisDs.insert(0, pDisToPoint[0]); //
}
else if (ind > 0 && ind < i)
{
pDisDs.insert(ind-1, pDisToPoint[ind-1]);
pDisDs[ind] = pDisToPoint[ind];
}
else if (ind == i)
{
pDisDs.append(pDisToPoint[i-1]);
}
delete pDisToPoint;
pDisToPoint = NULL;
if(i%1000 == 0)
{
cout <<"正在插入第 "<<i<<"个POI, 目前路径总长度为: "<< dLen<<"km\n";
cout << "Calculation Percentage: "<< 1.0*i/n*100 << "% ";
SYSTEMTIME sys;
GetLocalTime(&sys);
cout<<"cur time: "<<sys.wHour<<":"<<sys.wMinute<<" "<<sys.wSecond<<endl<<endl;
}
}
cout << "Calculation Finished!\n";
//输出最优路径
// for (i = 0; i < pdS.size(); i ++)
// {
// cout<<pdS[i]<<"→";
// }
// cout << endl;
#pragma omp parallel for
for ( i = 0; i < pdS.size(); i ++)
{
POI_order[i] = POI_Input[pdS[i]];
}
cout << "POI sorted!\n";
}
void buildPaths()
{
//创建vector文件
QFile outFile(outputfile);
if (!outFile.open(QIODevice::WriteOnly))
{
cout <<"result file open error!"<<endl;
system("pause");
}
QTextStream _out(&outFile);
//对于每个子链表,根据遍历最短路径排序,并写入文档
cout<<"Word To Vec..."<<endl;
if (mvPOI.size() > 0)
{
cout<<"length = "<<mvPOI.size()<<endl;
QList<POI> vPOI_Output;
ShortestPath(mvPOI, vPOI_Output, mvPOI.size());
for (long j = 0; j < mvPOI.size(); j ++)
{
_out << QString("%1,").arg(vPOI_Output[j].classType);
_out.flush();
}
_out<<QString("\r\n");
_out.flush();
}
outFile.close();
}
private:
QList<POI> mvPOI;
QString outputfile;
long lenOfPOI;
};
#endif这样生成的语料就能通过分析其上下文来做进一步分析啦。

相关文章推荐
- ArcGIS10.2 网络分析之路径分析(二)---构建网络数据集
- 单细胞数据高级分析之构建成熟路径 | Identifying a maturation trajectory
- 数据结构中关键路径算法的实现与应用
- SQLSERVER数据仓库的构建与分析
- WEB应用 信息管理系统 数据分析展示系统 OA办公工作流 快速构建与开发平台
- 最短路径分析算法in QGIS
- 最短路径分析算法in PgRouting
- 数据结构中关键路径算法的实现与应用
- 【算法设计与分析】最短路径的算法
- 复数数据类型算法分析
- 最短路径算法—Dijkstra(迪杰斯特拉)算法分析与实现(C/C++)
- 后缀数组构建--倍增算法分析
- SQLSERVER数据仓库的构建与分析
- 数据结构——邻接表表示的图的关键路径算法
- 最短路径分析算法分析(1)
- 数据结构中关键路径算法的实现与应用
- 网络数据集的构建以及基于网络数据集的路径分析
- 数据结构——带权有向图(最短路径算法Dijkstra算法)
- 一道算法题:(数据分析)
- 最短路径算法—Dijkstra(迪杰斯特拉)算法分析与实现(C/C++)