网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格
2016-08-19 11:05
591 查看
通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。
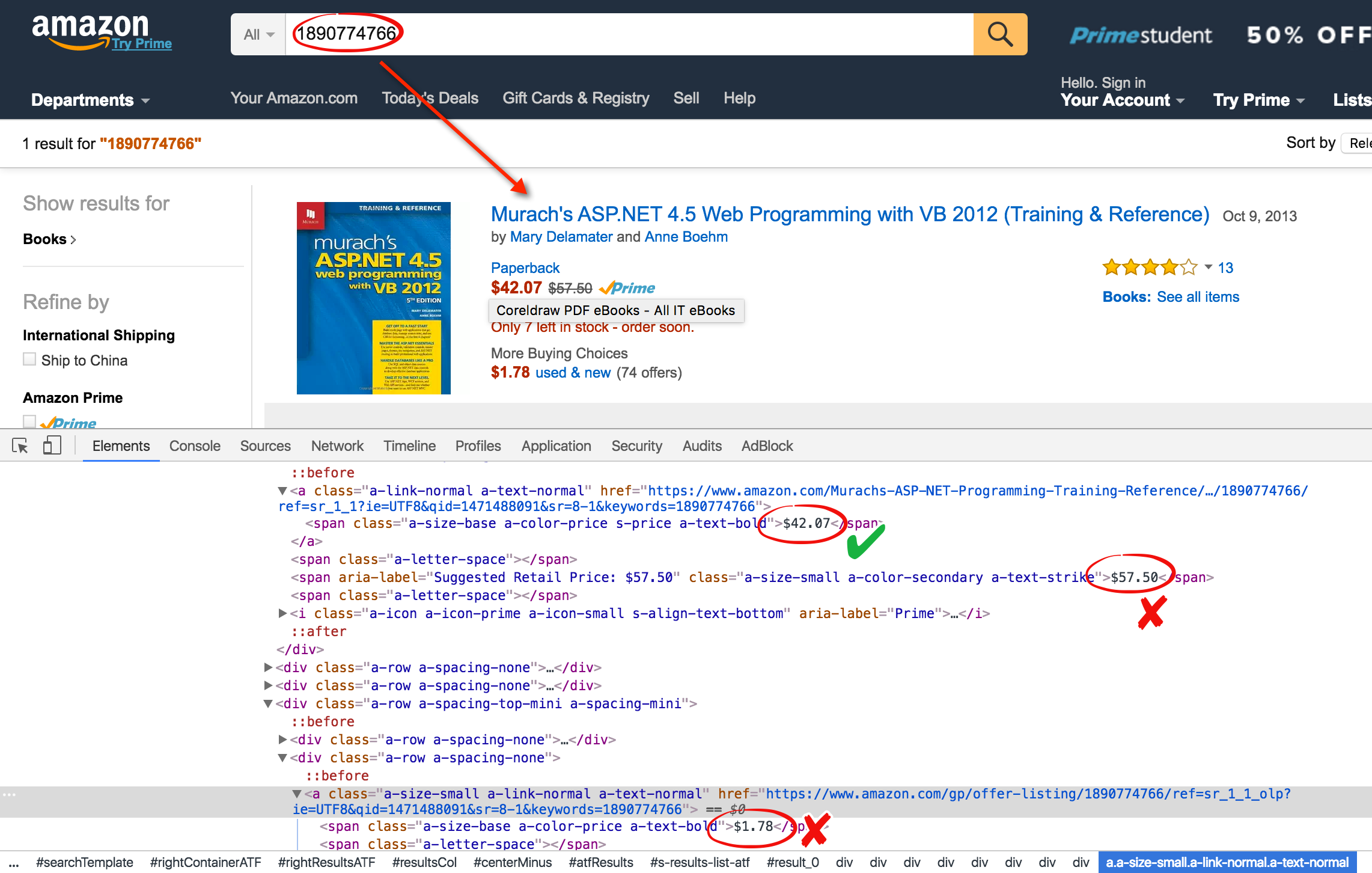
通过正则表达式匹配价格代码:
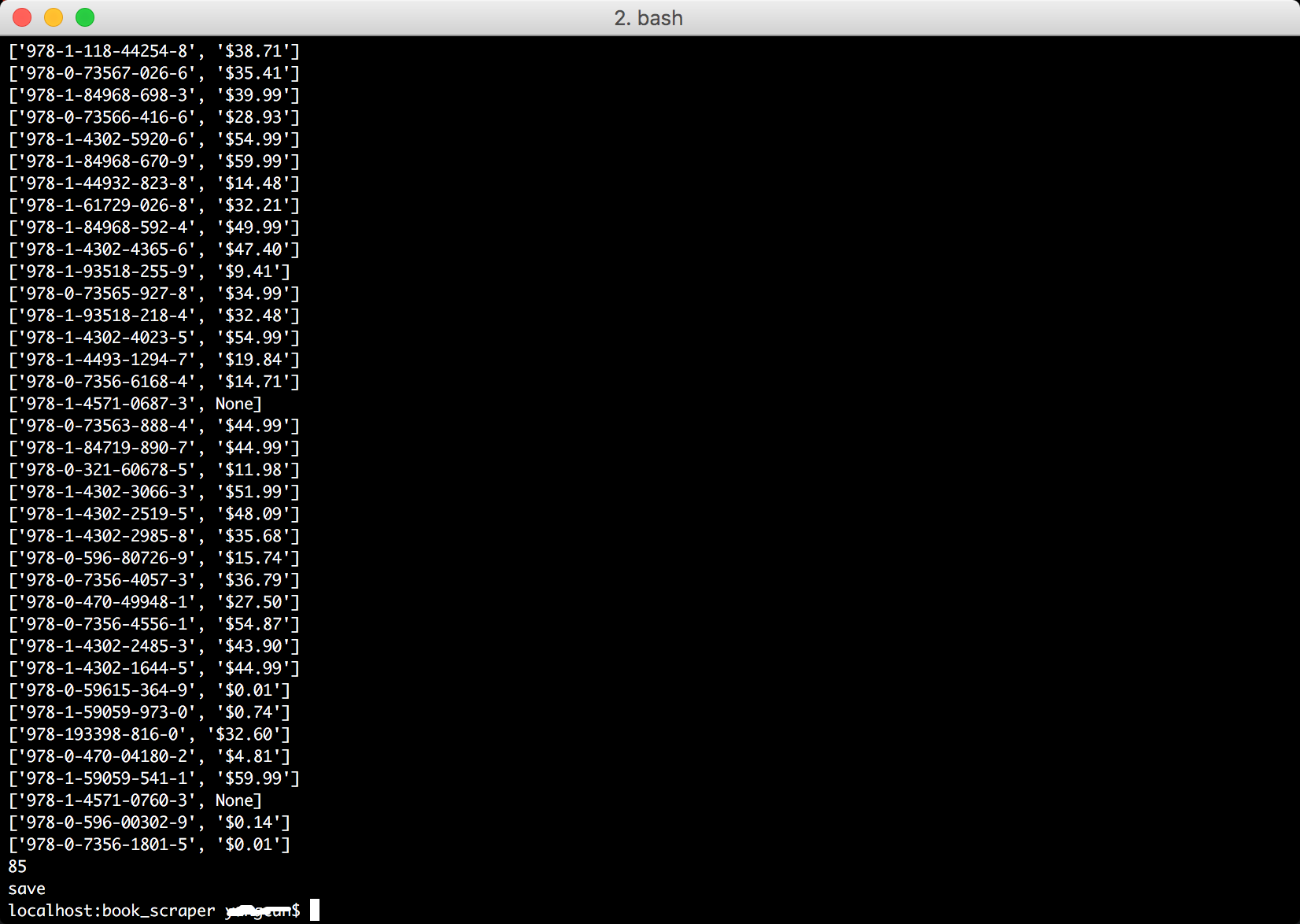
上一篇随笔中已经得到了所有书籍的ISBN码,遍历所有的ISBN码传入get_price_amazon()方法即可获取所有书籍的价格,运行结果:
二、将两部分结果数据合并
前两天刚学过数据处理(利用Python进行数据分析 基础系列随笔汇总),为了练练手,这里通过pandas将两部分数据合并起来:
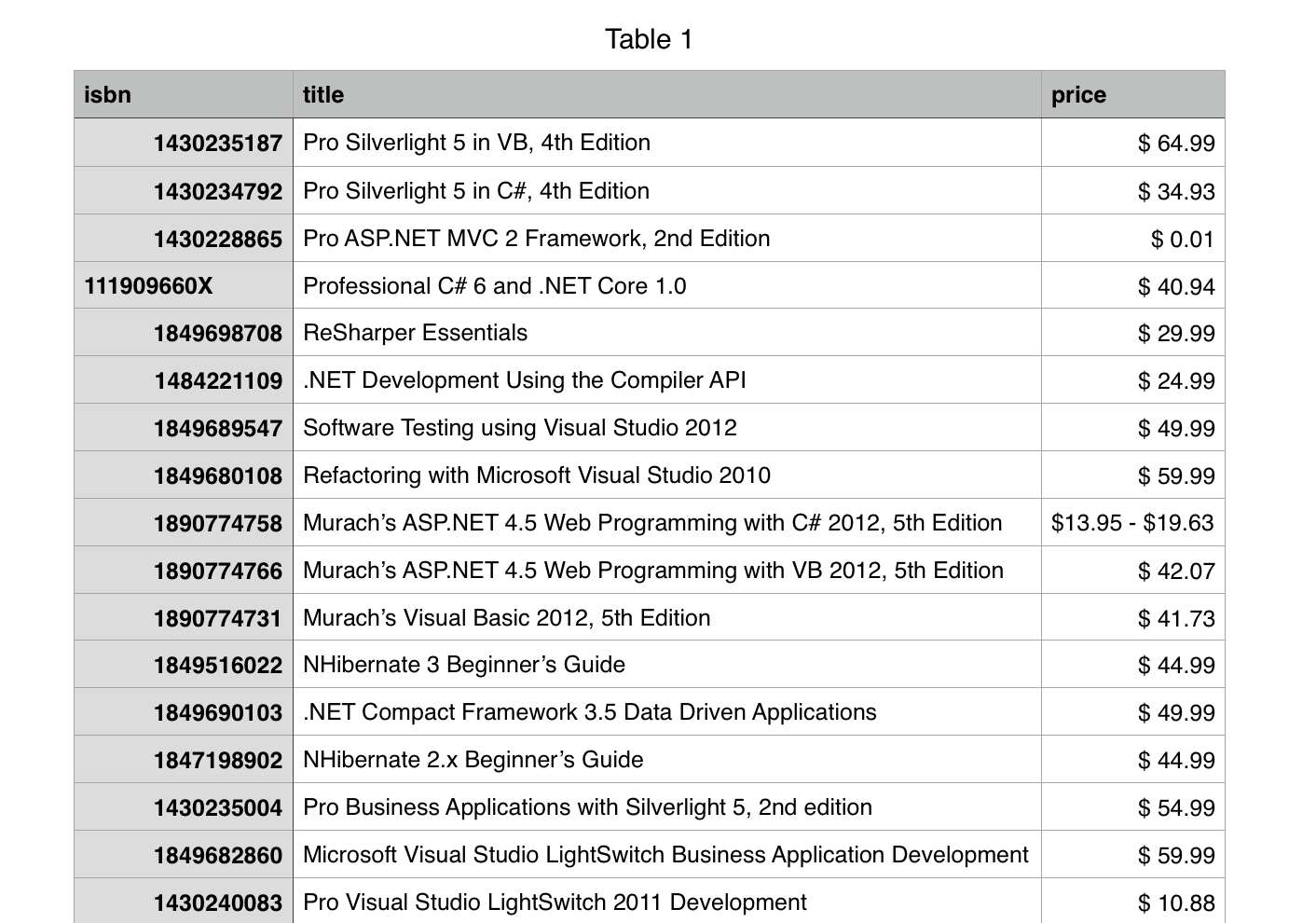
result.csv文件结果:
完整代码请移步github:https://github.com/backslash112/book_scraper_python
Beautiful Soup基础知识:网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(1): 基础知识Beautiful Soup
我们处于大数据时代,对数据处理感兴趣的朋友欢迎查看另一个系列随笔:利用Python进行数据分析 基础系列随笔汇总
接下来打算学习Scrapy库,Scrapy是一个采集工具,它可以帮你大幅降低网页查找和识别工作,轻松采集一个或多个域名的信息。有兴趣的朋友欢迎关注本博客,也欢迎大家留言进行讨论。
大数据,大数据分析、BeautifulSoup,Beautiful Soup入门,数据挖掘,数据分析,数据处理,pandas,网络爬虫,web scraper,python excel,python写入excel数据,python处理csv文件 python操作Excel,excel读写 通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。
通过正则表达式匹配价格代码:
def get_price_amazon(isbn):
base_url = "https://www.amazon.com/s/ref=nb_sb_noss?url=search-alias%3Daps&field-keywords="
url = base_url + str(isbn)
page = urlopen(url)
soup = BeautifulSoup(page, 'lxml')
page.close()
price_regexp = re.compile("\$[0-9]+(\.[0-9]{2})?")
price = soup.find(text=price_regexp)
return [isbn, price]上一篇随笔中已经得到了所有书籍的ISBN码,遍历所有的ISBN码传入get_price_amazon()方法即可获取所有书籍的价格,运行结果:
二、将两部分结果数据合并
前两天刚学过数据处理(利用Python进行数据分析 基础系列随笔汇总),为了练练手,这里通过pandas将两部分数据合并起来:
book_info_data = pd.read_csv('books.csv')
price_data = pd.read_csv('prices.csv')
result = pd.merge(book_info_data, price_data, on='isbn')
result.to_csv('result.csv', index=False, header=True, columns=['isbn', 'title', 'price'])result.csv文件结果:
完整代码请移步github:https://github.com/backslash112/book_scraper_python
Beautiful Soup基础知识:网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(1): 基础知识Beautiful Soup
我们处于大数据时代,对数据处理感兴趣的朋友欢迎查看另一个系列随笔:利用Python进行数据分析 基础系列随笔汇总
接下来打算学习Scrapy库,Scrapy是一个采集工具,它可以帮你大幅降低网页查找和识别工作,轻松采集一个或多个域名的信息。有兴趣的朋友欢迎关注本博客,也欢迎大家留言进行讨论。
大数据,大数据分析、BeautifulSoup,Beautiful Soup入门,数据挖掘,数据分析,数据处理,pandas,网络爬虫,web scraper,python excel,python写入excel数据,python处理csv文件 python操作Excel,excel读写 通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码。(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码)
接下来将通过ISBN码去amazon.com获取每本书对应的价格。
一、了解需要和分析网站
通过分析amazon.com得知,以ISBN码作为搜索关键字可查找到对应的书。
结果页码就有这本书的价格,既然价格是以$符号开头,那就可以通过正则表达式得到价格。

相关文章推荐
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(1): 基础知识Beautiful Soup
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息及ISBN码
- Python于allitebooks.com爬虫书籍名称导入数据库
- 网络爬虫:使用Scrapy框架编写一个抓取书籍信息的爬虫服务
- 网络爬虫--python抓取豆瓣同城北京地区活动信息
- <四>、python爬虫抓取购物网站商品信息--图片价格名称
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
- python网络爬虫实战3——抓取新闻内文相关信息
- Python网络爬虫之抓取订餐信息
- 用Jsoup爬虫抓取豆瓣书籍信息
- Python开发网络爬虫抓取某同城房价信息
- java 网络爬虫jsoup 抓取全中国 省市县镇村 完整全集信息 代码
- 【网络爬虫】【java】微博爬虫(二):如何抓取HTML页面及HttpClient使用
- 教您使用java爬虫gecco抓取JD全部商品信息
- C# 网络编程之通过豆瓣API获取书籍信息
- Python实例:网络爬虫抓取豆瓣3万本书(1)
- 我的第一个爬虫程序:利用Python抓取网页上的信息
- Java爬虫,信息抓取的实现 [转]
- Amazon.com 和 store.apple.com 哪个的购物体验更好?
- java 网页爬虫(以扒取amazon网页信息为例)