Caffe代码阅读
2016-08-19 10:06
253 查看
转载自:
Caffe代码阅读——层次结构 - 无痛的机器学习 - 知乎专栏 https://zhuanlan.zhihu.com/p/21796890
Caffe源码阅读——Net组装 - 无痛的机器学习 - 知乎专栏 https://zhuanlan.zhihu.com/p/21875025
Caffe代码阅读——Solver - 无痛的机器学习 - 知乎专栏 https://zhuanlan.zhihu.com/p/21800004
1.Caffe代码阅读——层次结构
作者:冯超
链接:https://zhuanlan.zhihu.com/p/21796890
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Caffe是一款优秀的深度神经网络的开源软件,下面我们来聊聊它的源代码以及它的实现。Caffe的代码整体上可读性很好,架构比较清晰,阅读代码并不算是一件很困难的事情。不过在阅读代码之前还是要回答两个问题:
阅读代码是为了什么?
阅读到什么程度?(这个问题实际上和前面的问题相关)
阅读代码大体上来说有下面几个目的:
搞清楚代码所实现的算法或者功能。对算法本身不是很了解,希望通过阅读代码了解算法。
搞清楚代码在实现算法过程中的细节。这种情况下,一般对算法已经有大概的了解,读代码是为了了解代码中对算法细节的考量。当然,如果想使用代码,了解代码细节是很有帮助的。
扩展代码。在开源代码的基础上,利用已有的框架,增加或者修改功能,来实现自己想要的功能。这个就需要对代码的架构细节有更加深入的了解。
我们的目标是扩展代码。Caffe中主要的扩展点就是Layer和Solver,当然其他的部分也可以扩展,只不过要改动的代码会多一些。
当确定了上面第一个问题,下面就是第二个问题了。读代码要读到什么程度?一般来说,我觉得阅读代码这件事情可以用一个Logistic型的函数来表示:
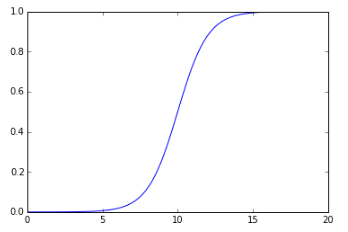
这个图上,横轴是阅读代码花费的时间,纵轴是阅读代码带来的效果。对于代码量比较大的项目,一开始阅读肯定是蒙的,需要花一定的时间梳理清楚各个文件,各个模块之间的关系。随着结构关系逐渐清晰,读者开始领会代码中所表达的含义,阅读代码的效果直线上升。然而当我们把代码主线和重要支线弄懂后,再读一些小支线的收益就不会太大。所以根据阅读代码的性价比和Caffe代码自身的特点,我们只会将主线和一些重要支线阅读完,估计也就是整体代码量的一半。
SyncedMem:这个类的主要功能是封装CPU和GPU的数据交互操作。一般来说,数据的流动形式都是:硬盘->CPU内存->GPU内存->CPU内存->(硬盘),所以在写代码的过程中经常会写CPU/GPU之间数据传输的代码,同时还要维护CPU和GPU两个处理端的内存指针。这些事情处理起来不会很难,但是会很繁琐。因此SyncedMem的出现就是把CPU/GPU的数据传输操作封装起来,只需要调用简单的接口就可以获得两个处理端同步后的数据。
Blob:这个类做了两个封装:一个是操作数据的封装。在这里使用Blob,我们可以操纵高维的数据,可以快速访问其中的数据,变换数据的维度等等;另一个是对原始数据和更新量的封装。每一个Blob中都有data和diff两个数据指针,data用于存储原始数据,diff用于存储反。向传播的梯度更新值。Blob使用了SyncedMem,这样也得到了不同处理端访问的便利。这样Blob就基本实现了整个Caffe数据部分结构的封装,在Net类中可以看到所有的前后向数据和参数都用Blob来表示就足够了。
数据的抽象到这个就可以了,接下来是层级的抽象。前面我们也分析过,神经网络的前后向计算可以做到层与层之间完全独立,那么每个层只要依照一定的接口规则实现,就可以确保整个网络的正确性。
Layer:Caffe实现了一个基础的层级类Layer,对于一些特殊种类还会有自己的抽象类(比如base_conv_layer),这些类主要采用了模板的设计模式(Template),也就是说一些必须的代码在基类写好,一些具体的内容在子类中实现。比方说在Layer的Setup中,函数中包括Setup的几个步骤,其中的一些步骤由基类完成,一些步骤由子类完成。还有十分重要的Forward和Backward,基类实现了其中需要的一些逻辑,但是真正的运算部分则交给了子类。这样当我们需要实现一个新的层时,我们不需要管理琐碎的事物,只要关系好层的初始化和前后向即可。
Net:Net将数据和层组合起来做进一步的封装,对外暴露了初始化和前后向的接口,使得整体看上去和一个层的功能类似,但内部的组合可以是多种多样。同时值得一提的是,每一层的输入输出数据统一保存在Net中,同时每个层内的参数指针也保存在Net中,不同的层可以通过WeightShare共享相同的参数,所以我们可以通过配置实现多个神经网络层之间共享参数的功能,这也增强了我们对网络结构的想象力。
Solver:有了Net我们实际上就可以进行网络的前向后向计算了,但是关于网络的学习训练的功能还有些缺乏,于是在此之上,Solver类进一步封装了训练和预测相关的一些功能。与此同时,它还开放了两类接口:一个是更新参数的接口,继承Solver可以实现不同的参数更新方法,如大家喜闻乐见的Momentum,Nesterov,Adagrad等。这样使得不同的优化算法能够应用其中。另外一个是训练过程中每一轮特定状态下的可注入的一些回调函数,在代码中这个回调点的直接使用者就是多卡训练算法。
IO:有了上面的东西就够了?还不够,我们还需要输入数据和参数,正所谓巧妇难为无米之炊,没有数据都是白搭。DataReader和DataTransformer帮助准备输入数据,Filler对参数进行初始化。一些Snapshot方法帮助模型的持久化,这样模型和数据的IO问题也解决了。
多卡:对于单GPU训练来说,基本的层次关系到这里也就结束了,如果要进行多GPU训练,那么上层还会有InternalThread和P2PSync两个类,这两个类属于最上层的类了,而他们所调用的也只有Solver和一些参数类。
其实到这里,Caffe的主线也就基本走完了。我们可以画一张图把Caffe的整体层次关系展示出来:
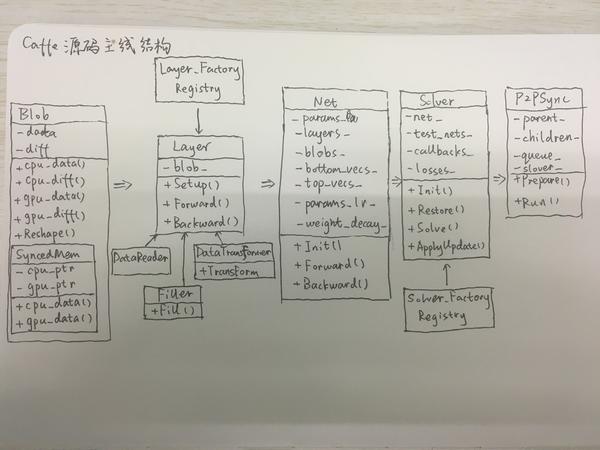
如果对这张图和图中的一些细节比较清楚的话,那么你对Caffe的了解应该已经不错了。后面关于Caffe源码分析的文章就可以不看了。如果没有,那么我们还是可以继续关注一下。当然如果想真正理解这张图中所表达的含义,还是要真正地读一下代码,去理解一些细节。但是有些细节这里就不做详细的分析了,下一回我们会站在Layer的角度去看一个Layer在训练过程的全部经历。
2.
最近忙着看TI没有及时写文章,今天赶紧补一篇……
Net是Caffe代码中一个比较核心的类,往下看它封装了所有的Layer,构建起了整个神经网络;往上看它对外提供了前向后向计算,以及核心数据结构的访问结构,使得再上层的Solver可以利用Net比较轻松地实现Train和Test的策略。当然,正是因为它的重要性,组装Net是一个比较复杂的部分。这一回我们就来看看Net的内容。
当然,说在前面,看Net组装的代码有两个目的:
了解作为一个成熟的CNN模型框架需要考虑的一些问题;
如果想对网络结构做扩展,如写一个新的Layer,其中的一些数据是如何在Layer和Net之间流动的
首先,为了使问题不那么复杂,我们先从训练模型时输出的log看看Net组装的几个关键步骤,然后再把这个过程慢慢展开,了解组装的所有细节。
下面我们要看的就是Net组装的Log。这段Log一般都是大家在训练网络时一闪而过的大段Log,当然如果它没有一闪而过而是停下来了,有可能是你的网络定义有问题爆出了错误。这段Log内容比较多,总体来说就是Train阶段和Test阶段的两个网络组装起来。我们重点关注其中的几个片段,来大概了解Net组装的一些核心内容,也是那些比较值得打印出来的内容。
首先是一个正常的卷积层conv1,Log如下所示(以下代码的行号可能会有不同,但位置是相近的):
这其中第一行是创建这个Layer实例的代码,具体的创建过程在layer_factory里面。为了方便创建Layer,Caffe采用了工厂方法的设计模式,只要提供Layer的名字(在配置文件中参数叫type),就可以根据名字和对应参数实例化一个Layer。这部分的细节只要认真看一下就会明白。
第3,4行显示了创建当前层的bottom和top数据的过程。这里涉及到net.cpp中的AppendBottom和AppendTop两个方法,因为每一个bottom blob和top blob都有名字,这里就将他们之间的关系输出在了这里。
第5行看上去没什么干货,但是它代表了Layer的Setup函数已经调用完成(或者Layer被share)。Layer的Setup函数是Layer初始化的关键函数,这里面涉及到以下几个具体的操作:
总结地说,这四句完成了:
对bottom blob, top blob数量的检查,父类实现。
对Layer内部相关变量的初始化,由具体的子类实现
传入时bottom blob的维度已经确定,Layer需要根据自己要做的计算确定top blob的纬度。比方说这一层是卷积层,维度是20*5*5,输入图像是1*28*28,也就是bottom blob的维度,那么输入就是20*24*24,这也是上面log里面算出的结果,只不过还加了一个batch size。这个函数由具体的子类实现。
对Layer是否输出loss以及输出loss要做的操作进行初始化。父类实现。必须说一句,Caffe中关于Loss Layer中Loss_weight,loss_,top.cpu_diff的数据设定还是有点绕且有点trick的。
好了回到上面的log。接下来的那一句告诉了我们top层应该输出的维度。这里输出了维度就是为了让不放心的朋友算一下,看看和你想的是否一样。当然,输出这句log的循环不是只做了这件事,它的主要工作就是设置top blob的loss_weight。
最后一句计算了该层top blob所占用的内存。可以看出截至到这一层,内存消耗大约是3M多,还不算大。
好,这就是一个最典型的Layer的初始化,下面这个ReLU层就稍微有些不同了:
这里面最不同的就是第4行结尾的(in-place),这说明relu的bottom blob和top blob是同一个数据,这和我们在网络中的定义是一样的。in-place的好处就是减少内存的操作,但是这里在统计内存消耗时并没有考虑in-place带来的节省。
接下来就是共享网络的conv1_p了:
这一段最有特点的是最后两句“Sharing”,因为siamese model中拥有参数完全相同的两个网络,所以在构建时候,第二个网络检测到参数名字已经存在,说明该层的参数和其他层共享,于是在这里打印出来告诉用户这一点。当然,这一句之前没有打印出来的内容告诉了我们,实际上Net类中还负责了参数相关的初始化。这部分的内容实际上还挺多,除了参数共享,还有对参数learning rate,weight decay的设定。
最后是最特别的一层:loss层
这一层看上去没有什么特别,该有的和前面一样,但是唯一不同的就是它的倒数第二行,这说明这一层是有loss weight的。至于有loss weight有什么用,以后我们会详细说这个事情。这里简单说一下,有loss weight表示这个blob会被用于计算loss。
前面的log主要解决了网络的组装和前向的一些计算,从log中,我们可以看出Net完成了以下的事情:
实例化Layer
创建bottom blob,top blob
Setup Layer(初始化Layer,确定top blob维度)
确定layer的loss_weight
确定layer的参数是否共享,不共享则创建新的
从上面的过程也可以看出,整个网络中所有的流动性变量(bottom blob,top blob)都保存在Net中,同时对于各层的参数,根据各层的共享关系做了标记。这样好处是集中管理了网络中的数据,方便对数据进行操作。
再往下面,我们可以截取一小段log来:
接下来是统计一个层次是否需要进行反向传播的计算。一般来说我们的层是都需要计算的,但是也会有一些层不需要计算,比方说数据层,就像上面的log那样,还有就是一些希望固定的层,这个一般在finetune网络的时候用的上。因为反向计算一般比前向计算慢,如果有不需要计算的Layer,直接跳过计算是可以节省时间的。
最后是整个网络产生的输出,这个输出会在训练迭代中显示出来的。
了解了这些,我们就对Net装载有了大概的了解,再去看它的代码就会轻松些。
最后,关于Net类中所有的成员变量与它们之间的关系,我们可以用下面的一张图来理解就好:
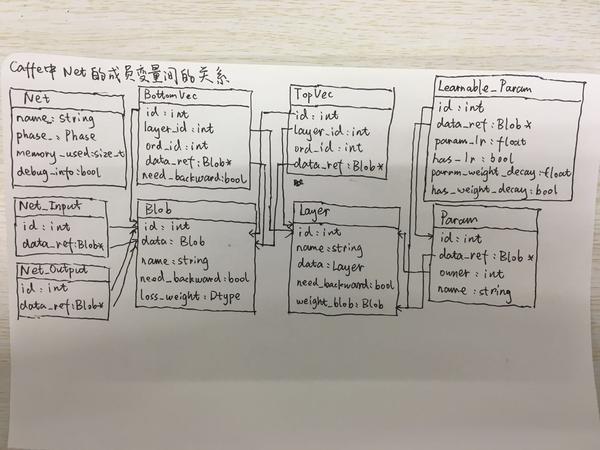
把Net的初始化理解后,其实Net以下的架构方面的问题就不多了。下面我再看看Net以上的东西,Solver以及Caffe里“简单”的多卡训练。
3.
前面我们聊了Net组装的内容,接下来我们来看看Solver的内容。Solver主体有两部分:初始化和训练。初始化内容相对比较简单,这里就不说了;下面我们来说说训练中的几个关键函数。
下面就是ApplyUpdate函数,这个函数真正完成了参数更新的任务。Caffe的参数更新只利用了模型的梯度信息,没有利用二阶信息。下面就详细介绍下更新参数的几个过程:
GetLearningRate
ClipGradients
Normalize
Regularize
ComputeUpdateValue
fixed:lr永远不变
step:

exp:

inv:

multistep:直接写iter在某个范围内时lr应该是多少
poly:

sigmoid:

这些方案各有优劣,选择自己顺手的就好。
当计算完这一步,我们就可以调用Blob中的Update把每个参数的data和diff进行相加,计算出最终的结果。这样,整个优化过程就完成了。至于剩下的一些内容都不是核心过程,就略去不看了。
如果我们采用单卡训练的策略,那么阅读代码到这里也差不多了。不过多卡训练对于大规模的训练任务来说是必不可少的,所以我们接下来趁热打铁地看看Caffe的多卡训练。
on_start():将参数拷贝到每一个GPU中。
ForwardBackward():每个GPU各自计算自己的前向后向结果。
on_gradient_ready():将反向梯度汇总到一起。
ApplyUpdate():在汇总的线程上进行参数更新
其中第2步由每一个CPU线程和自己的GPU并行完成,第4步由汇总的CPU和自己的GPU完成,剩下的1,3两步主要是完成数据传输的任务,也是多卡计算中主要完成的部分。
Caffe采用树型结构进行参数传递,其中一个CPU线程和GPU作为树型结构的根,其他的则作为根下面的节点。为了更快地传输GPU数据,树型结构的构建要考虑GPU之间是否相近,比方说两个GPU之间是否可以进行P2P的直传。在前面的翻译博客中我们已经聊过GPU之间数据传输的问题了,这里的树形结构也主要以此做考虑。
我们假设4块GPU的拓扑结构如下:
那么我们构造出的树型结构如下所示,数据传输也是按照这样的结构传输:
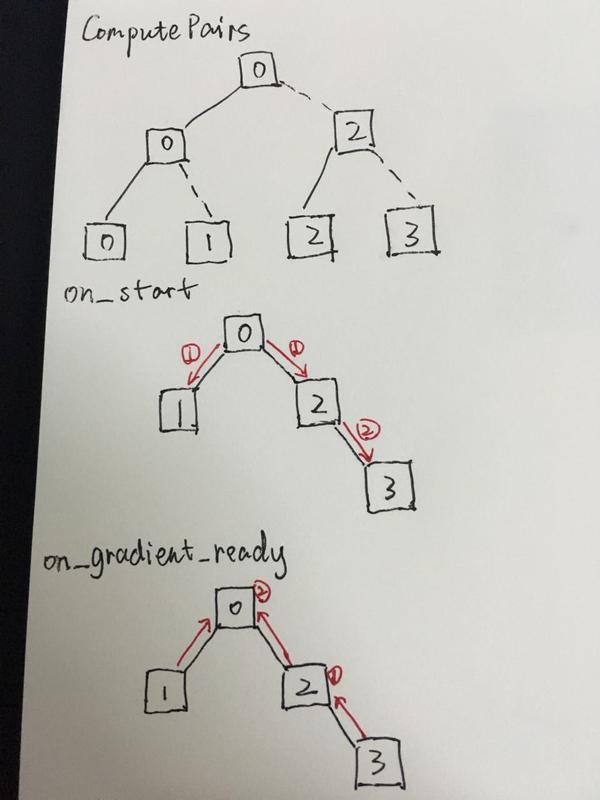
这样1,3的数据传递就解决了,具体的过程请详细阅读代码,这里就不叙述了。
对Caffe代码的基本介绍就到这里了,我们对代码的整体结构有了比较清晰的认识,下面我们将分析模型中各个部分的特性。
Caffe代码阅读——层次结构 - 无痛的机器学习 - 知乎专栏 https://zhuanlan.zhihu.com/p/21796890
Caffe源码阅读——Net组装 - 无痛的机器学习 - 知乎专栏 https://zhuanlan.zhihu.com/p/21875025
Caffe代码阅读——Solver - 无痛的机器学习 - 知乎专栏 https://zhuanlan.zhihu.com/p/21800004
1.Caffe代码阅读——层次结构
作者:冯超
链接:https://zhuanlan.zhihu.com/p/21796890
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Caffe是一款优秀的深度神经网络的开源软件,下面我们来聊聊它的源代码以及它的实现。Caffe的代码整体上可读性很好,架构比较清晰,阅读代码并不算是一件很困难的事情。不过在阅读代码之前还是要回答两个问题:
阅读代码是为了什么?
阅读到什么程度?(这个问题实际上和前面的问题相关)
阅读代码大体上来说有下面几个目的:
搞清楚代码所实现的算法或者功能。对算法本身不是很了解,希望通过阅读代码了解算法。
搞清楚代码在实现算法过程中的细节。这种情况下,一般对算法已经有大概的了解,读代码是为了了解代码中对算法细节的考量。当然,如果想使用代码,了解代码细节是很有帮助的。
扩展代码。在开源代码的基础上,利用已有的框架,增加或者修改功能,来实现自己想要的功能。这个就需要对代码的架构细节有更加深入的了解。
我们的目标是扩展代码。Caffe中主要的扩展点就是Layer和Solver,当然其他的部分也可以扩展,只不过要改动的代码会多一些。
当确定了上面第一个问题,下面就是第二个问题了。读代码要读到什么程度?一般来说,我觉得阅读代码这件事情可以用一个Logistic型的函数来表示:
这个图上,横轴是阅读代码花费的时间,纵轴是阅读代码带来的效果。对于代码量比较大的项目,一开始阅读肯定是蒙的,需要花一定的时间梳理清楚各个文件,各个模块之间的关系。随着结构关系逐渐清晰,读者开始领会代码中所表达的含义,阅读代码的效果直线上升。然而当我们把代码主线和重要支线弄懂后,再读一些小支线的收益就不会太大。所以根据阅读代码的性价比和Caffe代码自身的特点,我们只会将主线和一些重要支线阅读完,估计也就是整体代码量的一半。
Caffe代码的主线结构抽象
不同于其他的一些框架,Caffe没有采用符号计算的模式进行编写,整体上的架构以系统级的抽象为主。所谓的抽象,就是逐层地封装一些细节问题,让上层的代码变得更加清晰。那么就让我们来顺着Caffe的抽象层级看看Caffe的主线结构:SyncedMem:这个类的主要功能是封装CPU和GPU的数据交互操作。一般来说,数据的流动形式都是:硬盘->CPU内存->GPU内存->CPU内存->(硬盘),所以在写代码的过程中经常会写CPU/GPU之间数据传输的代码,同时还要维护CPU和GPU两个处理端的内存指针。这些事情处理起来不会很难,但是会很繁琐。因此SyncedMem的出现就是把CPU/GPU的数据传输操作封装起来,只需要调用简单的接口就可以获得两个处理端同步后的数据。
Blob:这个类做了两个封装:一个是操作数据的封装。在这里使用Blob,我们可以操纵高维的数据,可以快速访问其中的数据,变换数据的维度等等;另一个是对原始数据和更新量的封装。每一个Blob中都有data和diff两个数据指针,data用于存储原始数据,diff用于存储反。向传播的梯度更新值。Blob使用了SyncedMem,这样也得到了不同处理端访问的便利。这样Blob就基本实现了整个Caffe数据部分结构的封装,在Net类中可以看到所有的前后向数据和参数都用Blob来表示就足够了。
数据的抽象到这个就可以了,接下来是层级的抽象。前面我们也分析过,神经网络的前后向计算可以做到层与层之间完全独立,那么每个层只要依照一定的接口规则实现,就可以确保整个网络的正确性。
Layer:Caffe实现了一个基础的层级类Layer,对于一些特殊种类还会有自己的抽象类(比如base_conv_layer),这些类主要采用了模板的设计模式(Template),也就是说一些必须的代码在基类写好,一些具体的内容在子类中实现。比方说在Layer的Setup中,函数中包括Setup的几个步骤,其中的一些步骤由基类完成,一些步骤由子类完成。还有十分重要的Forward和Backward,基类实现了其中需要的一些逻辑,但是真正的运算部分则交给了子类。这样当我们需要实现一个新的层时,我们不需要管理琐碎的事物,只要关系好层的初始化和前后向即可。
Net:Net将数据和层组合起来做进一步的封装,对外暴露了初始化和前后向的接口,使得整体看上去和一个层的功能类似,但内部的组合可以是多种多样。同时值得一提的是,每一层的输入输出数据统一保存在Net中,同时每个层内的参数指针也保存在Net中,不同的层可以通过WeightShare共享相同的参数,所以我们可以通过配置实现多个神经网络层之间共享参数的功能,这也增强了我们对网络结构的想象力。
Solver:有了Net我们实际上就可以进行网络的前向后向计算了,但是关于网络的学习训练的功能还有些缺乏,于是在此之上,Solver类进一步封装了训练和预测相关的一些功能。与此同时,它还开放了两类接口:一个是更新参数的接口,继承Solver可以实现不同的参数更新方法,如大家喜闻乐见的Momentum,Nesterov,Adagrad等。这样使得不同的优化算法能够应用其中。另外一个是训练过程中每一轮特定状态下的可注入的一些回调函数,在代码中这个回调点的直接使用者就是多卡训练算法。
IO:有了上面的东西就够了?还不够,我们还需要输入数据和参数,正所谓巧妇难为无米之炊,没有数据都是白搭。DataReader和DataTransformer帮助准备输入数据,Filler对参数进行初始化。一些Snapshot方法帮助模型的持久化,这样模型和数据的IO问题也解决了。
多卡:对于单GPU训练来说,基本的层次关系到这里也就结束了,如果要进行多GPU训练,那么上层还会有InternalThread和P2PSync两个类,这两个类属于最上层的类了,而他们所调用的也只有Solver和一些参数类。
其实到这里,Caffe的主线也就基本走完了。我们可以画一张图把Caffe的整体层次关系展示出来:
如果对这张图和图中的一些细节比较清楚的话,那么你对Caffe的了解应该已经不错了。后面关于Caffe源码分析的文章就可以不看了。如果没有,那么我们还是可以继续关注一下。当然如果想真正理解这张图中所表达的含义,还是要真正地读一下代码,去理解一些细节。但是有些细节这里就不做详细的分析了,下一回我们会站在Layer的角度去看一个Layer在训练过程的全部经历。
2.
Caffe源码阅读——Net组装
最近忙着看TI没有及时写文章,今天赶紧补一篇……Net是Caffe代码中一个比较核心的类,往下看它封装了所有的Layer,构建起了整个神经网络;往上看它对外提供了前向后向计算,以及核心数据结构的访问结构,使得再上层的Solver可以利用Net比较轻松地实现Train和Test的策略。当然,正是因为它的重要性,组装Net是一个比较复杂的部分。这一回我们就来看看Net的内容。
当然,说在前面,看Net组装的代码有两个目的:
了解作为一个成熟的CNN模型框架需要考虑的一些问题;
如果想对网络结构做扩展,如写一个新的Layer,其中的一些数据是如何在Layer和Net之间流动的
首先,为了使问题不那么复杂,我们先从训练模型时输出的log看看Net组装的几个关键步骤,然后再把这个过程慢慢展开,了解组装的所有细节。
Log眼中的Net组装
为了更好地展示Net组装的一些细节,我们在这里选取了一个实际例子,就是Caffe的examples里面的siamese model。关于这个model的细节这里就不多说了,感兴趣的可以去看官方或者非官方的文档,这里只提一点:这个网络除了包含其他正常网络中的一些特性之外,还具有网络参数复用的特点,在后面的分析中我们会用到。下面我们要看的就是Net组装的Log。这段Log一般都是大家在训练网络时一闪而过的大段Log,当然如果它没有一闪而过而是停下来了,有可能是你的网络定义有问题爆出了错误。这段Log内容比较多,总体来说就是Train阶段和Test阶段的两个网络组装起来。我们重点关注其中的几个片段,来大概了解Net组装的一些核心内容,也是那些比较值得打印出来的内容。
首先是一个正常的卷积层conv1,Log如下所示(以下代码的行号可能会有不同,但位置是相近的):
layer_factory.hpp:77] Creating layer conv1 net.cpp:92] Creating Layer conv1 net.cpp:428] conv1 <- data net.cpp:402] conv1 -> conv1 net.cpp:144] Setting up conv1 net.cpp:151] Top shape: 64 20 24 24 (737280) net.cpp:159] Memory required for data: 3752192
这其中第一行是创建这个Layer实例的代码,具体的创建过程在layer_factory里面。为了方便创建Layer,Caffe采用了工厂方法的设计模式,只要提供Layer的名字(在配置文件中参数叫type),就可以根据名字和对应参数实例化一个Layer。这部分的细节只要认真看一下就会明白。
第3,4行显示了创建当前层的bottom和top数据的过程。这里涉及到net.cpp中的AppendBottom和AppendTop两个方法,因为每一个bottom blob和top blob都有名字,这里就将他们之间的关系输出在了这里。
第5行看上去没什么干货,但是它代表了Layer的Setup函数已经调用完成(或者Layer被share)。Layer的Setup函数是Layer初始化的关键函数,这里面涉及到以下几个具体的操作:
CheckBlobCounts(bottom, top); LayerSetUp(bottom, top); Reshape(bottom, top); SetLossWeights(top);
总结地说,这四句完成了:
对bottom blob, top blob数量的检查,父类实现。
对Layer内部相关变量的初始化,由具体的子类实现
传入时bottom blob的维度已经确定,Layer需要根据自己要做的计算确定top blob的纬度。比方说这一层是卷积层,维度是20*5*5,输入图像是1*28*28,也就是bottom blob的维度,那么输入就是20*24*24,这也是上面log里面算出的结果,只不过还加了一个batch size。这个函数由具体的子类实现。
对Layer是否输出loss以及输出loss要做的操作进行初始化。父类实现。必须说一句,Caffe中关于Loss Layer中Loss_weight,loss_,top.cpu_diff的数据设定还是有点绕且有点trick的。
好了回到上面的log。接下来的那一句告诉了我们top层应该输出的维度。这里输出了维度就是为了让不放心的朋友算一下,看看和你想的是否一样。当然,输出这句log的循环不是只做了这件事,它的主要工作就是设置top blob的loss_weight。
最后一句计算了该层top blob所占用的内存。可以看出截至到这一层,内存消耗大约是3M多,还不算大。
好,这就是一个最典型的Layer的初始化,下面这个ReLU层就稍微有些不同了:
layer_factory.hpp:77] Creating layer relu1 net.cpp:92] Creating Layer relu1 net.cpp:428] relu1 <- ip1 net.cpp:389] relu1 -> ip1 (in-place) net.cpp:144] Setting up relu1 net.cpp:151] Top shape: 64 500 (32000) net.cpp:159] Memory required for data: 5769472
这里面最不同的就是第4行结尾的(in-place),这说明relu的bottom blob和top blob是同一个数据,这和我们在网络中的定义是一样的。in-place的好处就是减少内存的操作,但是这里在统计内存消耗时并没有考虑in-place带来的节省。
接下来就是共享网络的conv1_p了:
layer_factory.hpp:77] Creating layer conv1_p net.cpp:92] Creating Layer conv1_p net.cpp:428] conv1_p <- data_p net.cpp:402] conv1_p -> conv1_p net.cpp:144] Setting up conv1_p net.cpp:151] Top shape: 64 20 24 24 (737280) net.cpp:159] Memory required for data: 8721664 net.cpp:488] Sharing parameters 'conv1_w' owned by layer 'conv1', param index 0 net.cpp:488] Sharing parameters 'conv1_b' owned by layer 'conv1', param index 1
这一段最有特点的是最后两句“Sharing”,因为siamese model中拥有参数完全相同的两个网络,所以在构建时候,第二个网络检测到参数名字已经存在,说明该层的参数和其他层共享,于是在这里打印出来告诉用户这一点。当然,这一句之前没有打印出来的内容告诉了我们,实际上Net类中还负责了参数相关的初始化。这部分的内容实际上还挺多,除了参数共享,还有对参数learning rate,weight decay的设定。
最后是最特别的一层:loss层
net.cpp:92] Creating Layer loss net.cpp:428] loss <- feat net.cpp:428] loss <- feat_p net.cpp:428] loss <- sim net.cpp:402] loss -> loss net.cpp:144] Setting up loss net.cpp:151] Top shape: (1) net.cpp:154] with loss weight 1 net.cpp:159] Memory required for data: 10742020
这一层看上去没有什么特别,该有的和前面一样,但是唯一不同的就是它的倒数第二行,这说明这一层是有loss weight的。至于有loss weight有什么用,以后我们会详细说这个事情。这里简单说一下,有loss weight表示这个blob会被用于计算loss。
前面的log主要解决了网络的组装和前向的一些计算,从log中,我们可以看出Net完成了以下的事情:
实例化Layer
创建bottom blob,top blob
Setup Layer(初始化Layer,确定top blob维度)
确定layer的loss_weight
确定layer的参数是否共享,不共享则创建新的
从上面的过程也可以看出,整个网络中所有的流动性变量(bottom blob,top blob)都保存在Net中,同时对于各层的参数,根据各层的共享关系做了标记。这样好处是集中管理了网络中的数据,方便对数据进行操作。
再往下面,我们可以截取一小段log来:
net.cpp:220] pool1 needs backward computation. net.cpp:220] conv1 needs backward computation. net.cpp:222] slice_pair does not need backward computation. net.cpp:222] pair_data does not need backward computation. net.cpp:264] This network produces output loss net.cpp:277] Network initialization done.
接下来是统计一个层次是否需要进行反向传播的计算。一般来说我们的层是都需要计算的,但是也会有一些层不需要计算,比方说数据层,就像上面的log那样,还有就是一些希望固定的层,这个一般在finetune网络的时候用的上。因为反向计算一般比前向计算慢,如果有不需要计算的Layer,直接跳过计算是可以节省时间的。
最后是整个网络产生的输出,这个输出会在训练迭代中显示出来的。
了解了这些,我们就对Net装载有了大概的了解,再去看它的代码就会轻松些。
最后,关于Net类中所有的成员变量与它们之间的关系,我们可以用下面的一张图来理解就好:
把Net的初始化理解后,其实Net以下的架构方面的问题就不多了。下面我再看看Net以上的东西,Solver以及Caffe里“简单”的多卡训练。
3.
Caffe代码阅读——Solver
前面我们聊了Net组装的内容,接下来我们来看看Solver的内容。Solver主体有两部分:初始化和训练。初始化内容相对比较简单,这里就不说了;下面我们来说说训练中的几个关键函数。核心函数:Step
真正的训练在Step函数内,这里有多卡训练的关键回调函数:on_start()和on_gradient_ready(),具体的调用方法我们后面再说,在这两个回调函数中间有两个重要的过程:ForwardBackward和UpdateSmoothedLoss。在on_gradient_ready之后有一个关键函数ApplyUpdate(),这里面的代码在Sgd_solver中。下面我们详细看一下。ForwardBackward
这里主要调用了Net中的代码,主要完成了前向后向的计算,前向用于计算模型的最终输出和Loss,后向用于计算每一层网络和参数的梯度。对于前向后向的具体内容这里需要详细叙述了,唯一值得一提的是前向的Loss计算,这部分代码实际上实在Layer里面,具体涉及到loss_weight这个参数相关的初始化和loss()的判断,同时还有Loss_Layer在Setup函数中的初始化。UpdateSmoothedLoss
这个函数主要做Loss的平滑。由于Caffe的训练方式是SGD,我们无法把所有的数据同时放入模型进行训练,那么部分数据产生的Loss就可能会和全样本的平均Loss不同,在必要时候将Loss和历史过程中更新的Loss求平均就可以减少Loss的震荡问题。代码中的平滑方法比较简单,大家一看便知。下面就是ApplyUpdate函数,这个函数真正完成了参数更新的任务。Caffe的参数更新只利用了模型的梯度信息,没有利用二阶信息。下面就详细介绍下更新参数的几个过程:
GetLearningRate
ClipGradients
Normalize
Regularize
ComputeUpdateValue
GetLearningRate
learning rate的故事我们前面已经聊过了,在CNN训练中这确实是个大问题。Caffe为了让learning rate的设计更灵活,提供了一系列的learning rate方案:fixed:lr永远不变
step:
exp:
inv:
multistep:直接写iter在某个范围内时lr应该是多少
poly:
sigmoid:
这些方案各有优劣,选择自己顺手的就好。
ClipGradients
这一步主要是对梯度值做一个限制,如果梯度值过大,那么这里就会对梯度做一个修剪,对所有的参数乘以一个缩放因子,使得所有参数的平方和不超过参数中设定的梯度总值。这个功能感觉上像是对全局函数设置了一个Trust Region,可以防止更新的量过大二导致梯度发散。我认为这一步的想法是很好的,但是实际操作中可能会有问题。实际中可能只有部分参数的梯度比较大,而其他参数的梯度本身比较小,那么对所有的参数乘以相同的因子会让一些本来比较小的参数变得更小,这样会带来一些不公平。Normalize
这一步同样考虑了一些单一Batch不足以完成训练的问题,通过限制每个Batch的更新量来控制更新总量,代码比较简单。Regularize
到这一步终于要计算正则项的梯度了。Caffe提供两种正则方法——L2和L1,其中L2采用了标准的梯度下降方法,L1采用了sub-gradient的计算方法。L2的优化计算比较简单,没有什么好说的,但是L1的计算还是有点值得玩味的地方的。这里采用的sub-gradient方法其实本身没有什么问题,不过Lasso的优化还可以有其他的方法,这个问题以后可以再细聊。ComputeUpdateValue
到这里,我们终于来到了梯度计算的最后一站,这时候我们终于完成了对梯度的计算,下面该考虑lr和梯度结合起来如何计算最终的梯度优化值了。sgd方法主要采用momentum加梯度的优化方法。关于momentum的优势我们前面已经聊过了。除此之外,Caffe还提供了一系列的梯度计算方法,这些优化方法各有特点,以后我们可以慢慢来看。当计算完这一步,我们就可以调用Blob中的Update把每个参数的data和diff进行相加,计算出最终的结果。这样,整个优化过程就完成了。至于剩下的一些内容都不是核心过程,就略去不看了。
如果我们采用单卡训练的策略,那么阅读代码到这里也差不多了。不过多卡训练对于大规模的训练任务来说是必不可少的,所以我们接下来趁热打铁地看看Caffe的多卡训练。
多卡训练算法
Caffe的多卡训练算法总体思路是数据并行,我们用不同的GPU处理不同的数据,然后将所有的梯度更新汇总。由于Solver在训练中给了两个回调函数,多卡训练也主要利用了这两个回调函数进行:on_start():将参数拷贝到每一个GPU中。
ForwardBackward():每个GPU各自计算自己的前向后向结果。
on_gradient_ready():将反向梯度汇总到一起。
ApplyUpdate():在汇总的线程上进行参数更新
其中第2步由每一个CPU线程和自己的GPU并行完成,第4步由汇总的CPU和自己的GPU完成,剩下的1,3两步主要是完成数据传输的任务,也是多卡计算中主要完成的部分。
Caffe采用树型结构进行参数传递,其中一个CPU线程和GPU作为树型结构的根,其他的则作为根下面的节点。为了更快地传输GPU数据,树型结构的构建要考虑GPU之间是否相近,比方说两个GPU之间是否可以进行P2P的直传。在前面的翻译博客中我们已经聊过GPU之间数据传输的问题了,这里的树形结构也主要以此做考虑。
我们假设4块GPU的拓扑结构如下:
nvidia-smi topo -m GPU0 GPU1 GPU2 GPU3 GPU0 X PHB SOC SOC GPU1 PHB X SOC SOC GPU2 SOC SOC X PHB GPU3 SOC SOC PHB X
那么我们构造出的树型结构如下所示,数据传输也是按照这样的结构传输:
这样1,3的数据传递就解决了,具体的过程请详细阅读代码,这里就不叙述了。
对Caffe代码的基本介绍就到这里了,我们对代码的整体结构有了比较清晰的认识,下面我们将分析模型中各个部分的特性。

相关文章推荐
- caffe 代码阅读参考资料
- caffe代码阅读2:common的实现细节-2016.3.14
- Caffe阅读代码并修改
- caffe代码阅读3:Filler的实现
- caffe代码阅读2:DataTransformer以及io的实现细节
- Caffe 代码阅读笔记
- Caffe代码阅读8:absval_layer层的实现
- Caffe代码阅读11:absval_layer层的实现
- caffe代码阅读:SyncedMemory和Blob
- caffe代码阅读6:SyncedMemory的j介绍与实现
- caffe代码阅读3:data_reader、internalthread以及blocking_queue的实现细节-2016.3.15
- 如何阅读caffe代码
- caffe代码阅读7:LayerRegistry的实现细节-2016.3.18
- caffe代码阅读:layer类和net类
- 在Windows阅读Caffe代码
- caffe代码阅读1:blob的实现细节-2016.3.14
- caffe代码阅读6:Filler的实现细节-2016.3.18
- caffe代码阅读9:SyncedMemory的实现细节-2016.3.28
- Caffe学习系列(14):Caffe代码阅读
- caffe代码阅读7:Caffe中卷积的实现