大数据_Kafka_Kafka的常用指令 与 集群维护
2016-08-17 22:06
239 查看
下面的内容根据**学院的讲义总结而成
分为以下三个部分
0.Kafka集群基本信息实时查看和修改
1.Kafka集群leader平衡机制
2.Kafka集群分区日志迁移
0.Kafka集群基本信息实时查看和修改
集群信息实时查看(topic工具):
列出集群当前所有可用的topic:
bin/kafka-topics.sh --list --zookeeper zookeeper_address
查看集群特定topic 信息:
bin/kafka-topics.sh --describe --zookeeper zookeeper_address --topic topic_name
集群信息实时修改(topic工具):
创建topic:
bin/kafka-topics.sh --create --zookeeper zookeeper_address --replication-factor 1 --partitions 1 --topic topic_name
增加(不能减少) partition(最后的4是增加后的值):
bin/kafka-topics.sh --zookeeper zookeeper_address --alter --topic topic_name --partitions 4
修改的参数取决于Topic-level configuration . 里面的配置都能修改.
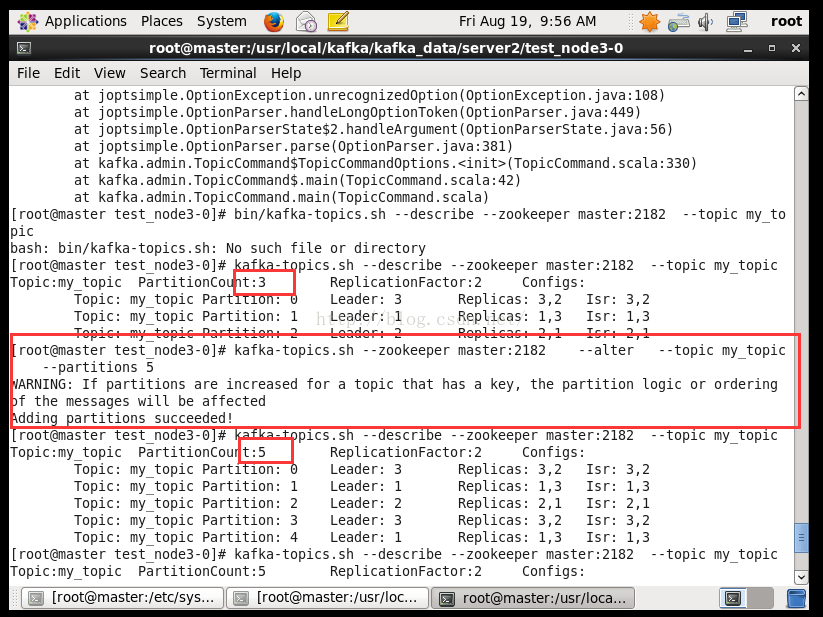
1.Kafka集群leader平衡机制
每个partitiion的所有replicas叫做“assigned replicas”,“assigned replicas”中的第一个replicas叫“preferred replica”,刚创建的topic一般“preferred replica”是leader。下图中Partition 0的broker 2就是preferred replica”,默认会成为该分区的leader。
集群leader平衡:
bin/kafka-preferred-replica-election.sh --zookeeper zookeeper_address
或者修改配置文件, 设置 auto.leader.rebalance.enable=true
让leader自动平衡
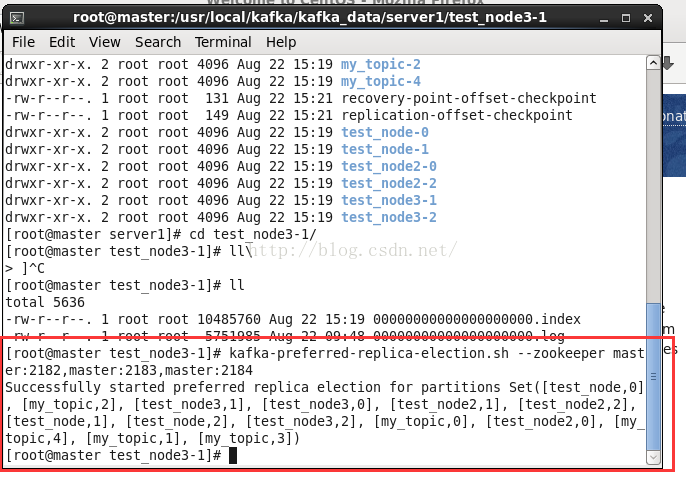
2.Kafka集群分区日志迁移 (热部署)
迁移topic数据到其他broker,请遵循下面四步:
1.写json文件,文件格式如下:
cat topics-to-move.json
{"topics": [{"topic": "foo1"},
{"topic": "foo2"}],
"version":1
}
2.使用–generate生成迁移计划(下面的操作是将topic: foo1和foo2移动到broker 5,6):
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file topics-to-move.json --broker-list "5,6" --generate
这一步只是生成计划,并没有执行数据迁移;
3.使用–execute执行计划:
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file expand-cluster-reassignment.json --execute
执行前最好保存当前的分配情况,以防出错回滚
4.使用–verify验证是否已经迁移完成
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file expand-cluster-reassignment.json --verify
额外内容:
迁移某个topic的某些特定的partition数据到其他broker,步骤与上面一样,但是json文件如下面所示:
cat custom-reassignment.json
{"version":1,"partitions":[{"topic":"foo1","partition":0,"replicas":[5,6]},{"topic":"foo2","partition":1,"replicas":[2,3]}]}
可以指定到topic的分区编号
kafka-reassign-partitions.sh工具会复制磁盘上的日志文件,只有当完全复制完成,才会删除迁移前磁盘上的日志文件。执行分区日志迁移需要注意:
kafka-reassign-partitions.sh 工具的粒度只能到broker,不能到broker的目录(如果broker上面配置了多个目录,是按照磁盘上面已驻留的分区数来均匀分配的),
所以,如果topic之间的数据,或者topic的partition之间的数据本身就不均匀,很有可能造成磁盘数据的不均匀:
对于分区数据较多的分区迁移数据会花大量的时间,所以建议在topic数据量较少或磁盘有效数据较少的情况下执行数据迁移操作;
进行分区迁移时最好先保留一个分区在原来的磁盘,这样不会影响正常的消费和生产,如果目的是将分区5(brober1,5)迁移到borker2,3。
可以先将5迁移到2,1,最后再迁移到2,3。而不是一次将1,5迁移到2,3。因为一次迁移所有的副本,无法正常消费和生产,部分迁移则可以正常消费和生产。
分为以下三个部分
0.Kafka集群基本信息实时查看和修改
1.Kafka集群leader平衡机制
2.Kafka集群分区日志迁移
0.Kafka集群基本信息实时查看和修改
集群信息实时查看(topic工具):
列出集群当前所有可用的topic:
bin/kafka-topics.sh --list --zookeeper zookeeper_address
查看集群特定topic 信息:
bin/kafka-topics.sh --describe --zookeeper zookeeper_address --topic topic_name
集群信息实时修改(topic工具):
创建topic:
bin/kafka-topics.sh --create --zookeeper zookeeper_address --replication-factor 1 --partitions 1 --topic topic_name
增加(不能减少) partition(最后的4是增加后的值):
bin/kafka-topics.sh --zookeeper zookeeper_address --alter --topic topic_name --partitions 4
修改的参数取决于Topic-level configuration . 里面的配置都能修改.
1.Kafka集群leader平衡机制
每个partitiion的所有replicas叫做“assigned replicas”,“assigned replicas”中的第一个replicas叫“preferred replica”,刚创建的topic一般“preferred replica”是leader。下图中Partition 0的broker 2就是preferred replica”,默认会成为该分区的leader。
集群leader平衡:
bin/kafka-preferred-replica-election.sh --zookeeper zookeeper_address
或者修改配置文件, 设置 auto.leader.rebalance.enable=true
让leader自动平衡
2.Kafka集群分区日志迁移 (热部署)
迁移topic数据到其他broker,请遵循下面四步:
1.写json文件,文件格式如下:
cat topics-to-move.json
{"topics": [{"topic": "foo1"},
{"topic": "foo2"}],
"version":1
}
2.使用–generate生成迁移计划(下面的操作是将topic: foo1和foo2移动到broker 5,6):
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --topics-to-move-json-file topics-to-move.json --broker-list "5,6" --generate
这一步只是生成计划,并没有执行数据迁移;
3.使用–execute执行计划:
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file expand-cluster-reassignment.json --execute
执行前最好保存当前的分配情况,以防出错回滚
4.使用–verify验证是否已经迁移完成
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181 --reassignment-json-file expand-cluster-reassignment.json --verify
额外内容:
迁移某个topic的某些特定的partition数据到其他broker,步骤与上面一样,但是json文件如下面所示:
cat custom-reassignment.json
{"version":1,"partitions":[{"topic":"foo1","partition":0,"replicas":[5,6]},{"topic":"foo2","partition":1,"replicas":[2,3]}]}
可以指定到topic的分区编号
kafka-reassign-partitions.sh工具会复制磁盘上的日志文件,只有当完全复制完成,才会删除迁移前磁盘上的日志文件。执行分区日志迁移需要注意:
kafka-reassign-partitions.sh 工具的粒度只能到broker,不能到broker的目录(如果broker上面配置了多个目录,是按照磁盘上面已驻留的分区数来均匀分配的),
所以,如果topic之间的数据,或者topic的partition之间的数据本身就不均匀,很有可能造成磁盘数据的不均匀:
对于分区数据较多的分区迁移数据会花大量的时间,所以建议在topic数据量较少或磁盘有效数据较少的情况下执行数据迁移操作;
进行分区迁移时最好先保留一个分区在原来的磁盘,这样不会影响正常的消费和生产,如果目的是将分区5(brober1,5)迁移到borker2,3。
可以先将5迁移到2,1,最后再迁移到2,3。而不是一次将1,5迁移到2,3。因为一次迁移所有的副本,无法正常消费和生产,部分迁移则可以正常消费和生产。

相关文章推荐
- 维护数据表常用SQL语句
- Sqlite 常用函数封装:修改密码,创建数据库、获取表段、字段,取值、插入、删除数据、执行Sqlite指令
- spark streaming 同时处理两个不同kafka集群的数据
- kafka集群维护
- kafka集群维护
- 爱立信Redback SmartEdge 800常用维护指令
- Spark Streaming +Kafka 使用底层API直接读取Kafka的Partition数据,手动更新Offset到Zookeeper集群
- Kafka笔记--常用指令(删除topic)
- hbase集群 常用维护命令
- Kafka学习(5)——常用集群操作
- 维护数据表常用SQL语句
- mysql导入导出表结构及表数据及执行sql常用指令
- mongo集群常用维护命令
- mysql维护管理常用指令
- Storm-Kafka模块常用接口分析及消费kafka数据例子
- oracle表空间,角色,权限,表,索引,序列号,视图,同义词,约束条件,存储函数和过程,常用数据字典,基本数据字典信息,查看VGA信息,维护表空间,创建表空间等信息
- Unix[IBM/AIX|集群情况]下Oralce10g常用维护命令
- 维护表数据的常用方法
- 大数据_Kafka_搭建Kafka伪集群(本地集群)
- 大数据集群遇到的问题(Hadoop、Spark、Hive、kafka、Hbase、Phoenix)