【电信计费系统项目实战】基础篇---解析XML文件
2016-08-13 00:15
423 查看
写在前面
这一篇介绍如何解析xml文件,因项目中的角色管理有个权限列表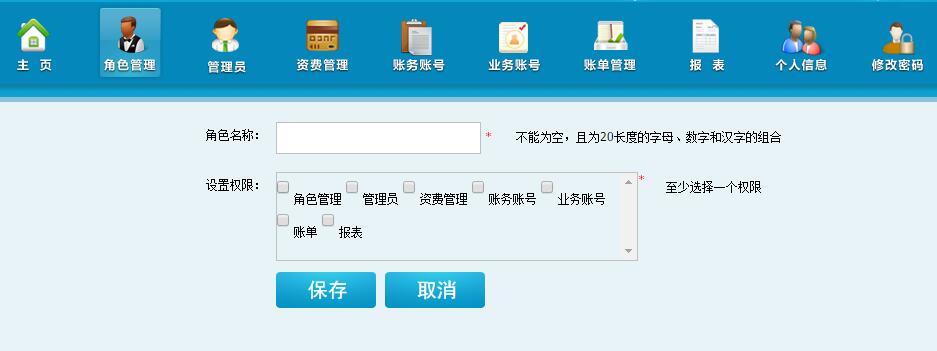
为了方便管理,我们用privileges.xml存储权限操作信息。
解析xml文件
用privileges.xml存储权限操作信息的代码如下:<?xml version="1.0" encoding="UTF-8"?> <privileges> <privilege id="1"> <name>角色管理</name> <urls> <url>/findRole.action</url> <url>/toAddRole.action</url> <url>/addRole.action</url> <url>/toUpdateRole.action</url> <url>/updateRole.action</url> <url>/deleteRole.action</url> </urls> </privilege> <privilege id="2"> <name>管理员</name> <urls> <url>/findAdmin.action</url> <url>/toAddAdmin.action</url> <url>/addAdmin.action</url> <url>/toUpdateAdmin.action</url> <url>/updateAdmin.action</url> <url>/deleteAdmin.action</url> <url>/resetPassword.action</url> </urls> </privilege> <privilege id="3"> <name>资费管理</name> <urls> <url>/findCost.action</url> <url>/addCost.action</url> <url>/toUpdateCost.action</url> <url>/updateCost.action</url> </urls> </privilege> <privilege id="4"> <name>账务账号</name> <urls> <url>/findAccount.action</url> <url>/addAccount.action</url> <url>/toUpdateAccount.action</url> <url>/updateAccount.action</url> <url>/startAccount.action</url> <url>/pauseAccount.action</url> <url>/deleteAccount.action</url> <url>/viewAccount.action</url> </urls> </privilege> <privilege id="5"> <name>业务账号</name> <urls> <url>/findService.action</url> <url>/toAddService.action</url> <url>/addService.action</url> <url>/toUpdateService.action</url> <url>/updateService.action</url> <url>/pauseService.action</url> <url>/deleteService.action</url> </urls> </privilege> <privilege id="6"> <name>账单</name> <urls> <url>/billList.action</url> <url>/billItemList.action</url> <url>/billServiceDetail.action</url> </urls> </privilege> <privilege id="7"> <name>报表</name> <urls> <url>/report.action</url> </urls> </privilege> </privileges>
解析xml文件的方式有多种,我这里是用SAXReader的方式来解析,使用SAXReader需要导入dom4j.jar包, dom4j是一个Java的XML API,类似于jdom,用来读写XML文件的。dom4j是一个非常非常优秀的Java XML API。那我们来看看我们项目是怎么解析privileges.xml里存储的权限操作信息的。
package com.tarena.util;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import com.tarena.entity.Privilege;
/**
* 解析privileges.xml工具类
*/
public class PrivilegeReader {
// 用于存储privileges.xml的权限操作信息
private static List<Privilege> privileges = new ArrayList<Privilege>();
static {
InputStream xml = PrivilegeReader.class.getClassLoader()
.getResourceAsStream("privileges.xml");
privileges = toModuleList(xml);
}
/**
* 返回XML中所有权限数据
*
* @return
*/
public static List<Privilege> getPrivileges() {
return privileges;
}
/**
* 根据权限ID查询模块名称
*
* @param id
* @return
*/
public static String getPrivilegeNameById(String id) {
List<Privilege> privileges = getPrivileges();
for (Privilege privilege : privileges) {
if (privilege.getId().equals(id)) {
return privilege.getName();
}
}
return null;
}
/**
* 解析privileges.xml文件
*
* @param xml
* @return
*/
@SuppressWarnings("unchecked")
protected static List<Privilege> toModuleList(InputStream xml) {
List<Privilege> modules = new ArrayList<Privilege>();
try {
SAXReader reader = new SAXReader();
Document doc = reader.read(xml);
Element root = doc.getRootElement();
List<Element> moduleElements = root.elements("privilege");
for (Element moduleElement : moduleElements) {
Privilege module = new Privilege();
module.setId(moduleElement.attributeValue("id"));
module.setName(moduleElement.elementText("name"));
Element urlElement = moduleElement.element("urls");
List<Element> urlElements = urlElement.elements();
List<String> urls = new ArrayList<String>();
for (Element element : urlElements) {
urls.add(element.getText());
}
module.setUrls(urls);
modules.add(module);
}
return modules;
} catch (DocumentException e) {
e.printStackTrace();
throw new RuntimeException("解析权限文件失败!", e);
}
}
public static void main(String[] args) {
List<Privilege> list = PrivilegeReader.getPrivileges();
for (Privilege p : list) {
System.out.println(p.getId() + " " + p.getName());
}
}
}先直接看下解析后的结果,运行main方法可以看到:
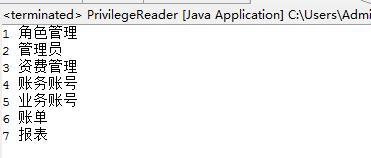
ok,xml里的权限信息都被解析出来了。
解释:
InputStream xml = PrivilegeReader.class.getClassLoader().getResourceAsStream(“privileges.xml”);
PrivilegeReader.class是获得对象当前的类类型,然后在类类型上调用getClassLoader()方法是得到当前类型的类加载器,我们知道在Java中所有的类都是通过加载器加载到虚拟机中的,最后调用了类加载器的getResourceAsStream()方法来加载资源。
SAXReader reader = new SAXReader();
Document doc = reader.read(xml);
Element root = doc.getRootElement();
List moduleElements = root.elements(“privilege”);
Document doc = reader.read(xml),生成文档对应实体 。Element root = doc.getRootElement(),读取文档根元素。List moduleElements = root.elements(“privilege”),获取根元素为privilege的组件元素集合。
写在最后
晚安!
相关文章推荐
- 【电信计费系统项目实战】基础篇---解析XML文件
- 【电信计费系统项目实战】基础篇---登录检查拦截器
- 【电信计费系统项目实战】基础篇---登录界面实现
- 【电信计费系统项目实战】基础篇---登录界面实现
- 【电信计费系统项目实战】基础篇---jdbc连接数据库代码
- 【电信计费系统项目实战】介绍篇
- 【java项目实战】dom4j解析xml文件,连接Oracle数据库
- XML解析--小项目实战(联系人管理系统)
- 【java项目实战】dom4j解析xml文件,连接Oracle数据库
- 【java项目实战】dom4j解析xml文件,连接Oracle数据库
- 【java项目实战】dom4j解析xml文件,连接Oracle数据库
- x4412开发板&ibox卡片电脑项目实战3-文件系统编译脚本解析
- x4412开发板&ibox卡片电脑项目实战3-文件系统编译脚本解析
- 【java项目实战】dom4j解析xml文件,连接Oracle数据库
- 实战CRM系统项目:2.概要设计,数据库设计
- 实战项目:考勤系统的需求分析
- 电信计费帐务综合管理系统
- Radware负载均衡项目配置实战解析之四-VRRP双机配置与同步
- Radware负载均衡项目配置实战解析之三业务部署和NAT配置
- Drupal项目实战-公司订餐系统