全排列生成算法
2016-08-11 23:06
288 查看
1.什么是全排列:
我们假如有一串式子,排列组合的结果会有很多种,全排列就是按照字典序有序的将所有的排列组合的性质的陈列出来问题可以这么描述:
对于给定的集合A{a1,a2,...,an},其中的n个元素互不相同,如何输出这n个元素的所有排列(全排列)
2.求解算法:
1.DFS(我们大多数人所谓的递归的方法):
我们来这么看这个问题,加入有n个数据要进行全排列,我们可以假想我们面前有n个盒子每一次我们有大小顺序的依次将我们手头还空余的数放进盒子中,当我们手头已经空的时候,我们就已经生成了一种全排列
这个时候我们采用深搜(回溯法)的思想,我们收起我们刚才放入盒子的元素,然后放进去下一个恰好(一定要是恰好,中间不可以在空余出满足条件的元素)比他大的元素,然后继续这个过程,当我们所有的情况都结束之后,那么我们的全排列也就生成完毕了
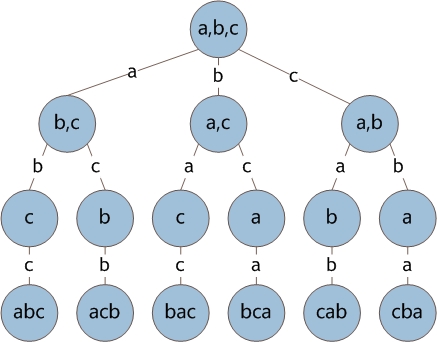
DFS代码如下:
#include"iostream"
#include"cstdio"
#include"cstdlib"
#include"cstring"
using namespace std;
//假设问题是求出1-5的全排列
int a[6];
bool book[6]; //用来复制记录哪些我们已经用过了
void dfs(int n) //n代表目前该操作哪个盒子
{
if(n==6)
{
for(int i=1;i<=5;i++) cout<<a[i]<<' ';
cout<<endl;
return ;
}
else
{
for(int i=1;i<=5;i++)
{
if(book[i]==0)
{
a
=i;
book[i]=1;
dfs(n+1);
book[i]=0;
}
}
}
}
int main()
{
memset(a,0,sizeof(a));
memset(book,0,sizeof(book));
dfs(1);
return 0;
}2.字典序算法:
字典序算法很高效但是证明非常的麻烦首先我们来看算法的步骤,我会一一讲解:
对于排列a[1...n],找到所有满足a[k]<a[k+1](0<k<n-1)的k的最大值,如果这样的k不存在,则说明当前排列已经是a的所有排列中字典序最大者,所有排列输出完毕。
在a[k+1...n]中,寻找满足这样条件的元素l,使得在所有a[l]>a[k]的元素中,a[l]取得最小值。也就是说a[l]>a[k],但是小于所有其他大于a[k]的元素。
交换a[l]与a[k].
对于a[k+1...n],反转该区间内元素的顺序。也就是说a[k+1]与a
交换,a[k+2]与a[n-1]交换,……,这样就得到了a[1...n]在字典序中的下一个排列。
大神的解释(有几句话很有用):
算法步骤1,得到的子串 s = {pj+1,.....,pn}, 是按照从大到小进行排列的。即有 pj+1 > pj+2 > ... > pn, 因为 j=max{i|pi<pi+1}。
算法步骤2,得到了最小的比pj大的pk,从n往j数,第一个比j大的数字。将pk和pj替换,保证了替换后的数字比当前的数字要大。
于是得到的序列为p1p2...pj-1pkpj+1...pk-1pjpk-1...pn.注意这里已经将pk替换成了pk。
这时候我们注意到比p1..pj-1pk.....,恰好比p1....pj.....pn大的数字集合。我们在这个集合中挑选出最小的一个即时所要求的下一个排列。
算法步骤3,即是将pk后面的数字逆转一下(从从大到小,变成了从小到大。)
由此经过上面3个步骤得到的下个排列时恰好比当前排列大的排列。
同时我们注意到,当所有排列都找完时,此时数字串从大到小排列。步骤1得到的j = 0,算法结束。
上面的原理还是看不懂的,请看这里,这里对算法的本质有进一步的阐述:
这里我假如我自己的一些认识:
1.这里的操作步骤我们可以明显的发现一点,找到的j号元素之后的序列完全都是从大到小的(这一点非常重要,这也是为什么我们一会还要进行反转的原因)
2.这里我们发现交换的时候都是找最次小来进行交换本人开始存在疑问,那么能不能简化算法的步骤,直接选择j序列最后的元素来交换?(求教大神,还是说我这里理解有一些错误)我会用代码验证,验证完毕,这是错误的,详情请见下面的代码片
3.这里的交换的目的很明显是为了尽可能保证最小的改变,来尽可能选择到该排列的下一个排列,反转的目的和前面相同,也是为了保证最次小的性质
代码1(完全按照算法的要求来进行):
#include"iostream"
#include"cstdio"
#include"cstring"
#include"cstdlib"
#define inf 99999999
using namespace std;
int a[6];
int j=0; //算法中描述的j
int k=0; //算法中描述的相对最次小于j号位置元素的k号位置
void print()
{
for(int i=1;i<=5;i++) cout<<a[i]<<' ';
cout<<endl;
}
bool findj()
{
for(int i=5;i>=2;i--) //从后开始遍历,查找满足条件的最大的j号位置
{
if(a[i-1]<a[i]) //锁定j号位置
{
j=i-1;
return 1;
}
}
return 0; //找不到对应的j的位置,说明全排列已经全部输出
}
void findk()
{
int min=inf;
for(int i=j+1;i<=5;i++)
{
if(a[i]<min&&a[i]>a[j]) //这一句很关键,知道我们findk的目的就好
{
min=a[i];
k=i;
}
}
}
void swap(int x,int y)
{
int t=a[x];
a[x]=a[y];
a[y]=t;
}
void change()
{
int a=j+1;
int b=5;
while(a<b)
{
swap(a,b);
a++;
b--;
}
}
int main()
{
for(int i=1;i<=5;i++) a[i]=i;
print(); //初始先输出一次
while(1)
{
if(findj())
{
findk();
swap(j,k);
change();
print();
}
else break;
}
return 0;
}代码2(k直接选取j最后一个元素,验证一下):实际上错了我们在调试的时候会发现,当状态为2 3 1的时候,k应该是2,不是3
这里我没有仔细的理解算法中k的限定,k位置的元素是恰好比j号元素要大,但是虽然j后元素都是递减有序的,但是最后一个元素未必比j号元素大,但是我们可以这么小优化一下,因为j后序列是有序的,我们可以从后往前遍历来找k号节点(和找j是一样的)
#include"iostream"
#include"cstdio"
#include"cstring"
#include"cstdlib"
#define inf 99999999
using namespace std;
int a[6];
int j=0; //算法中描述的j
int k=0; //算法中描述的相对最次小于j号位置元素的k号位置
void print()
{
for(int i=1;i<=3;i++) cout<<a[i]<<' ';
cout<<endl;
}
bool findj()
{
for(int i=3;i>=2;i--) //从后开始遍历,查找满足条件的最大的j号位置
{
if(a[i-1]<a[i]) //锁定j号位置
{
j=i-1;
return 1;
}
}
return 0; //找不到对应的j的位置,说明全排列已经全部输出
}
void swap(int x,int y)
{
int t=a[x];
a[x]=a[y];
a[y]=t;
}
void change()
{
int a=j+1;
int b=3;
while(a<b)
{
swap(a,b);
a++;
b--;
}
}
int main()
{
for(int i=1;i<=5;i++) a[i]=i;
print(); //初始先输出一次
while(1)
{
if(findj())
{
k=3;
swap(j,k);
change();
print();
}
else break;
}
return 0;
}
