海量数据处理——位图法bitmap
2016-08-10 15:58
375 查看
一、定义
位图法就是bitmap的缩写。所谓bitmap,就是用每一位来存放某种状态,适用于大规模数据,但数据状态又不是很多的情况。通常是用来判断某个数据存不存在的。在STL中有一个bitset容器,其实就是位图法,引用bitset介绍:A bitset
is a special container class that is designed to store bits (elements with only two possible values: 0 or 1,true or false,
...).The class is very similar to a regular array, but optimizing for space allocation:
each element occupies only one bit (which is eight times less than the smallest elemental type in C++: char).Each
element (each bit) can be accessed individually: for example, for a given bitset named mybitset,
the expression mybitset[3] accesses its fourth bit, just
like a regular array accesses its elements.
二、数据结构
unsignedint bit
;
在这个数组里面,可以存储
N * sizeof(int) * 8个数据,但是最大的数只能是N * sizeof(int) * 8 - 1。假如,我们要存储的数据范围为0-15,则我们只需要使得N=1,这样就可以把数据存进去。如下图:

数据为【5,1,7,15,0,4,6,10】,则存入这个结构中的情况为

三、相关操作
1,写入数据
定义一个数组:unsigned char bit[8 * 1024];这样做,能存
8K*8=64K 个 unsigned short 数据。bit 存放的字节位置和位位置(字节 0~8191 ,位 0~7 )
比如写
1234 ,字节序: 1234/8 = 154; 位序: 1234 &0b111 = 2 ,那么 1234 放在 bit 的下标 154 字节处,把该字节的 2 号位( 0~7)置为 1
字节位置:
int nBytePos =1234/8 = 154;
位位置:
int nBitPos = 1234 & 7 = 2;
<span style="color:#330033;">// 把数组的 154 字节的 2 位置为 1 unsigned short val = 1<<nBitPos; bit[nBytePos] = bit[nBytePos] |val; // 写入 1234 得到arrBit[154]=0b00000100 </span>
再比如写入
1236 ,
字节位置:
int nBytePos =1236/8 = 154;
位位置:
int nBitPos = 1236 & 7 = 4
<span style="color:#330033;">// / 把数组的 154 字节的 4 位置为 1 val = 1<<nBitPos; arrBit[nBytePos] = arrBit[nBytePos] |val; // 再写入 1236 得到arrBit[154]=0b00010100 </span>
函数实现:
<span style="color:#330033;">#define SHIFT 5
#define MAXLINE 32
#define MASK 0x1F
void setbit(int *bitmap, int i){
bitmap[i >> SHIFT] |= (1 << (i & MASK));
} </span>
2,读指定位
<span style="color:#330033;">bool getbit(int *bitmap1, int i){
return bitmap1[i >> SHIFT] & (1 << (i & MASK));
} </span>
四、位图法的缺点
可读性差位图存储的元素个数虽然比一般做法多,但是存储的元素大小受限于存储空间的大小。位图存储性质:存储的元素个数等于元素的最大值。比如, 1K 字节内存,能存储 8K 个值大小上限为 8K 的元素。(元素值上限为 8K ,这个局限性很大!)比如,要存储值为
65535 的数,就必须要 65535/8=8K 字节的内存。要就导致了位图法根本不适合存 unsigned int 类型的数(大约需要 2^32/8=5 亿字节的内存)。
位图对有符号类型数据的存储,需要 2 位来表示一个有符号元素。这会让位图能存储的元素个数,元素值大小上限减半。 比如 8K 字节内存空间存储 short 类型数据只能存 8K*4=32K 个,元素值大小范围为 -32K~32K 。
五、位图法的应用
1、给40亿个不重复的unsignedint的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中
首先,将这40亿个数字存储到bitmap中,然后对于给出的数,判断是否在bitmap中即可。
2、使用位图法判断整形数组是否存在重复
遍历数组,一个一个放入bitmap,并且检查其是否在bitmap中出现过,如果没出现放入,否则即为重复的元素。
3、使用位图法进行整形数组排序
首先遍历数组,得到数组的最大最小值,然后根据这个最大最小值来缩小bitmap的范围。这里需要注意对于int的负数,都要转化为unsigned int来处理,而且取位的时候,数字要减去最小值。
4、在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数
参 考的一个方法是:采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)。其实,这里可以使用两个普 通的Bitmap,即第一个Bitmap存储的是整数是否出现,如果再次出现,则在第二个Bitmap中设置即可。这样的话,就可以使用简单的1-
Bitmap了。
求解问题如下:
在本地磁盘里面有file1和file2两个文件,每一个文件包含500万条随机整数(可以重复),最大不超过2147483648也就是一个int表示范围。要求写程序将两个文件中都含有的整数输出到一个新文件中。
要求:
1.程序的运行时间不超过5秒钟。
2.没有内存泄漏。
3.代码规范,能要考虑到出错情况。
4.代码具有高度可重用性及可扩展性,以后将要在该作业基础上更改需求。
初一看,觉得很简单,不就是求两个文件的并集嘛,于是很快写出了下面的代码。
<span style="color:#330033;">#include<iostream>
#include<vector>
#include<cstdlib>
#include<algorithm>
#include<fstream>
using namespace std;
void merge(const vector<int> &, const vector<int>&, vector<int> &);
int main(){
vector<int> v1, v2;
vector<int> result;
char buf[512];
FILE *fp;
fp = fopen("file1", "r");
if(fp < 0){
cout<<"Open file failed!\n";
exit(1);
}
while(fgets(buf, 512, fp) != NULL){
v1.push_back(atoi(buf));
}
sort(v1.begin(), v1.end());
fclose(fp);
fp = fopen("file2", "r");
if(fp < 0){
cout<<"Open file2 failed!\n";
exit(1);
}
while(fgets(buf, 512, fp) != NULL){
v2.push_back(atoi(buf));
}
sort(v2.begin(), v2.end());
cout<<v1[v1.size() - 1]<<endl;
cout<<v2[v2.size() - 1]<<endl;
fclose(fp);
merge(v1, v2, result);
cout<<result.size();
ofstream output;
output.open("result");
if(output.fail()){
cerr<<"crete file failed!\n";
exit(1);
}
vector<int>::const_iterator p = result.begin();
for(; p != result.end(); p++){
output<<*p<<endl;
}
output.close();
return 0;
}
void merge(const vector<int>& v1, const vector<int>& v2, vector<int> &result){
vector<int>::const_iterator p1, p2;
p1 = v1.begin();
p2 = v2.begin();
while((p1 != v1.end()) && p2 != v2.end()){
if(*p1 < *p2){
p1++;
}else if(*p1 > *p2){
p2++;
}else{
result.push_back(*p1);
p1++;
p2++;
}
}
} </span>编译运行。
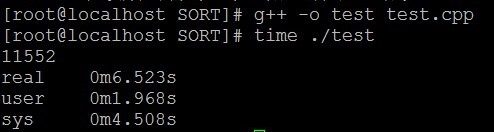
一看,不行,不满足上面的5秒之内,于是又想了很久,上面不是显示sys调用花了很长时间嘛,于是有写了一个程序,用快速排序+二分查找法实现,代码如下:
<span style="color:#330033;">#include <iostream>
#include <fstream>
#include <vector>
#include <cstdlib>
#include <cstdio>
#define MAXLINE 32
using namespace std;
void qsort(vector<int>&, int, int);
int partition(vector<int>&, int, int);
bool binarySearch(const vector<int>&, int);
int main(){
vector<int> v1, result;
int temp;
char buf[MAXLINE];
FILE *fd;
fd = fopen("file1", "r");
if(fd == NULL){
cerr<<"Open file1 failed!\n";
exit(1);
}
while(fgets(buf, MAXLINE, fd) != NULL){
v1.push_back(atoi(buf));
}
fclose(fd);
//cout<<v1.size()<<endl;
qsort(v1, 0, v1.size() - 1);
/*vector<int>::const_iterator p = v1.begin();
for(; p != v1.end(); p++){
cout<<*p<<endl;
sleep(1);
}*/
fd = fopen("file2", "r");
if(fd == NULL){
cerr<<"open file2 failed!\n";
exit(1);
}
while(fgets(buf, MAXLINE, fd) != NULL){
temp = atoi(buf);
if(binarySearch(v1, temp)){
result.push_back(temp);
}
}
cout<<result.size();
return 0;
}
void qsort(vector<int> &v, int low, int hight){
if(low < hight){
int mid = partition(v, low, hight);
qsort(v, low, mid - 1);
qsort(v, mid + 1, hight);
}
}
int partition(vector<int> &v, int min, int max){
int temp = v[min];
while(min < max){
while(min < max && v[max] >= temp)
max--;
v[min] = v[max];
while(min < max && v[min] <= temp)
min++;
v[max] = v[min];
}
v[min] = temp;
return min;
}
bool binarySearch(const vector<int> &v, int key){
int low, hight, mid;
low = 0;
hight = v.size() - 1;
while(low <= hight){
mid = (low + hight) /2;
if(v[mid] == key){
return true;
}else if(v[mid] < key){
low = mid + 1;
}else{
hight = mid - 1;
}
}
return false;
} </span>正乐着呢,编译运行:
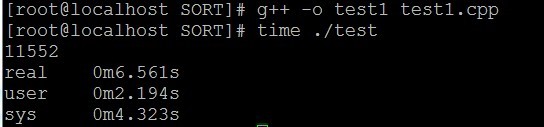
结果发现,user时间是2.194秒,整个时间还要比以前长,显然这种方法还是不行,原因就是两个文件太大了,500万条,不是一般小,且上面花的时间主要用在排序上面去了,于是就想,能不能不用排序完成?这时有个朋友和我说了一下位图法,灵感一来,自己又去改写了代码:
<span style="color:#330033;">#include <iostream>
#include <cstdlib>
#include <cstdio>
#include <cstring>
#include <fstream>
#include <string>
#include <vector>
#include <algorithm>
#include <iterator>
#define SHIFT 5
#define MAXLINE 32
#define MASK 0x1F
using namespace std;
void setbit(int *bitmap, int i){
bitmap[i >> SHIFT] |= (1 << (i & MASK));
}
bool getbit(int *bitmap1, int i){
return bitmap1[i >> SHIFT] & (1 << (i & MASK));
}
size_t getFileSize(ifstream &in, size_t &size){
in.seekg(0, ios::end);
size = in.tellg();
in.seekg(0, ios::beg);
return size;
}
char * fillBuf(const char *filename){
size_t size = 0;
ifstream in(filename);
if(in.fail()){
cerr<< "open " << filename << " failed!" << endl;
exit(1);
}
getFileSize(in, size);
char *buf = (char *)malloc(sizeof(char) * size + 1);
if(buf == NULL){
cerr << "malloc buf error!" << endl;
exit(1);
}
in.read(buf, size);
in.close();
buf[size] = '\0';
return buf;
}
void setBitMask(const char *filename, int *bit){
char *buf, *temp;
temp = buf = fillBuf(filename);
char *p = new char[11];
int len = 0;
while(*temp){
if(*temp == '\n'){
p[len] = '\0';
len = 0;
//cout<<p<<endl;
setbit(bit, atoi(p));
}else{
p[len++] = *temp;
}
temp++;
}
delete buf;
}
void compareBit(const char *filename, int *bit, vector<int> &result){
char *buf, *temp;
temp = buf = fillBuf(filename);
char *p = new char[11];
int len = 0;
while(*temp){
if(*temp == '\n'){
p[len] = '\0';
len = 0;
if(getbit(bit, atoi(p))){
result.push_back(atoi(p));
}
}else{
p[len++] = *temp;
}
temp++;
}
delete buf;
}
int main(){
vector<int> result;
unsigned int MAX = (unsigned int)(1 << 31);
unsigned int size = MAX >> 5;
int *bit1;
bit1 = (int *)malloc(sizeof(int) * (size + 1));
if(bit1 == NULL){
cerr<<"Malloc bit1 error!"<<endl;
exit(1);
}
memset(bit1, 0, size + 1);
setBitMask("file1", bit1);
compareBit("file2", bit1, result);
delete bit1;
cout<<result.size();
sort(result.begin(), result.end());
vector< int >::iterator it = unique(result.begin(), result.end());
ofstream of("result");
ostream_iterator<int> output(of, "\n");
copy(result.begin(), it, output);
return 0;
} </span>这是利用位图法实现的程序,编译运行
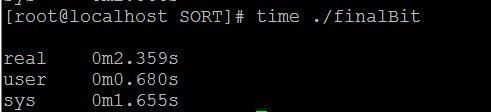
运行时间明显比前两个少,但是这个程序是以空间换取时间,程序运行的时候分配了几百兆的空间。可见在程序设计中,方法很重要。什么情况选用什么方法。但是还是觉得前面两个方法还行,因为需要的空间比较少。

相关文章推荐
- 海量数据处理---位图法Bitmap
- 海量数据处理——位图法bitmap
- 海量数据处理系列——C语言下实现bitmap算法
- 使用bitmap处理海量数据
- 海量数据处理--位图(BitMap)
- BitMap(位图) -处理海量数据
- bitmap处理海量数据
- 海量数据处理-----bitmap
- 使用bitmap处理海量数据
- [算法系列之十八]海量数据处理之BitMap
- [算法系列之十八]海量数据处理之BitMap
- JAVA海量数据处理之二(BitMap)
- 海量数据处理之Bitmap
- [算法系列之十八]海量数据处理之BitMap
- Bitmap 海量数据处理
- 解析bitmap处理海量数据及其实现方法分析
- 海量数据处理之bitmap实现
- 海量数据处理(1)Bitmap, Bloom Filter, Hash(转)
- 位图法;海量数据处理之位图技巧;位图技巧;海量数据;编程珠玑第二章问题A;40亿整数;腾讯面试题
- 海量数据处理系列----C++中Bitmap算法的实现