实战hadoop2.6.3+zookeeper3.4.6+hbase1.0.2高可用集群方案
2016-08-08 13:31
501 查看
实战hadoop2.6.3+zookeeper3.4.6+hbase1.0.2高可用集群方案
一、安装前准备
1.环境5台
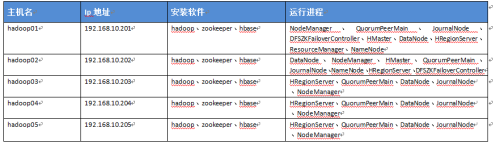
2、修改hosts文件
[root@hadoop01 ~]# cat /etc/hosts
192.168.10.201hadoop01
192.168.10.202hadoop02
192.168.10.203hadoop03
192.168.10.204hadoop04
192.168.10.205hadoop05
3、ssh 免密码登录
在每台操作
[root@hadoop01 ~]# mkidr ~/.ssh
[root@hadoop01 ~]# chmod 700 ~/.ssh
[root@hadoop01 ~]#cd ~/.ssh/
[root@hadoop01 .ssh ]ssh-keygen -t rsa
五台操作完成 后做成公钥文件
[root@hadoop01 .ssh ] ssh hadoop02 cat /root/.ssh/id_rsa.pub >> authorized_keys
[root@hadoop01 .ssh ] ssh hadoop03 cat /root/.ssh/id_rsa.pub >> authorized_keys
[root@hadoop01 .ssh ] ssh hadoop04 cat /root/.ssh/id_rsa.pub >> authorized_keys
[root@hadoop01 .ssh ] ssh hadoop05 cat /root/.ssh/id_rsa.pub >> authorized_keys
[root@hadoop01 .ssh ] ssh hadoop01 cat /root/.ssh/id_rsa.pub >> authorized_keys
[root@hadoop01 .ssh]# chmod 600 authorized_keys
[root@hadoop01 .ssh]# scp authorized_keys hadoop02:/root/.ssh/
[root@hadoop01 .ssh]# scp authorized_keys hadoop03:/root/.ssh/
[root@hadoop01 .ssh]# scp authorized_keys hadoop04:/root/.ssh/
[root@hadoop01 .ssh]# scp authorized_keys hadoop05:/root/.ssh/
测试ssh信任
[root@hadoop01 .ssh]# ssh hadoop02 date
Mon Aug 8 11:07:23 CST 2016
[root@hadoop01 .ssh]# ssh hadoop03 date
Mon Aug 8 11:07:26 CST 2016
[root@hadoop01 .ssh]# ssh hadoop04 date
Mon Aug 8 11:07:29 CST 2016
[root@hadoop01 .ssh]# ssh hadoop05 date
5.服务时间同步(五台操作)
yum -y install ntpdate
[root@hadoop01 .ssh]# crontab -l
0 * * * * /usr/sbin/ntpdate 0.rhel.pool.ntp.org && /sbin/clock -w
可以采用别的方案同步时间
6.修改文件打开数(五台操作)
[root@hadoop01 ~]# vi /etc/security/limits.conf
root soft nofile 65535
root hard nofile 65535
root soft nproc 32000
root hard nproc 32000
[root@hadoop01 ~]# vi /etc/pam.d/login
session required pam_limits.so
修改完后重启系统
二、安装hadoop+zookeeper HA
1.安装jdk (五台操作)
解压jdk
[root@hadoop01 ~] cd /opt
[root@hadoop01 opt]# tar zxvf jdk-7u21-linux-x64.tar.gz
[root@hadoop01 opt]# mv jdk1.7.0_21 jdk
配置到环境变量/etc/profile
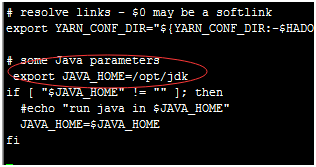
[root@hadoop01 opt]# vi /etc/profile
#java
JAVA_HOME=/opt/jdk
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME
export PATH
export CLASSPATH
配置文件生效
[root@hadoop01 opt]# source /etc/profile
[root@hadoop01 opt]# java -version
java version "1.7.0_21"
Java(TM) SE Runtime Environment (build 1.7.0_21-b11)
Java HotSpot(TM) 64-Bit Server VM (build 23.21-b01, mixed mode)
以上说明生效
2.解压hadoop并修改环境变量
[root@hadoop01 ~]# tar zxvf hadoop-2.6.3.tar.gz
[root@hadoop01 ~]#mkdir /data
[root@hadoop01 ~]# mv hadoop-2.6.3 /data/hadoop
[root@hadoop01 data]# vi /etc/profile
##hadoop
export HADOOP_HOME=/data/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/bin
[root@hadoop01 data]# source /etc/profile
3.修改hadoop配置文件
[root@hadoop01 data]# cd /data/hadoop/etc/hadoop/
[root@hadoop01 hadoop]# vi slaves
hadoop01
hadoop02
hadoop03
hadoop04
hadoop05
以上利用hadoop01,hadoop02两台磁盘空间,也增加进去了,不介意增加。
[root@hadoop01 hadoop]# vi hadoop-env.sh

[root@hadoop01 hadoop]# vi yarn-env.sh
修改core-site.xml文件
[root@hadoop01 hadoop]# vi core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
<description>The name of the default file system.</description>
<final>true</final>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2190,hadoop02:2190,hadoop03:2190,hadoop04:2190,hadoop05:2190</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>2048</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
</configuration>
修改hdfs-site.xml文件
[root@hadoop01 hadoop]# vi hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>hadoop01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>hadoop02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn1</name>
<value>hadoop01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>hadoop02:50070</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.cluster.nn1</name>
<value>hadoop01:53333</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.cluster.nn2</name>
<value>hadoop02:53333</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485;hadoop04:8485;hadoop05:8485/cluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/mydata/journal</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/mydata/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/mydata/data</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8480</value>
</property>
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8485</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
修改mapred-site.xml
[root@hadoop01 hadoop]# vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.cluster.temp.dir</name>
<value>/data/hadoop/mydata/mr_temp</value>
</property>
<property>
<name>mareduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
</configuration>
修改yarn-site.xml文件
[root@hadoop01 hadoop]# vi yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>60000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rm-cluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop02</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2190,hadoop02:2190,hadoop03:2190,hadoop04:2190,hadoop05:2190,</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>${yarn.resourcemanager.hostname.rm1}:23140</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>${yarn.resourcemanager.hostname.rm1}:23130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>${yarn.resourcemanager.hostname.rm1}:23189</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>${yarn.resourcemanager.hostname.rm1}:23188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>${yarn.resourcemanager.hostname.rm1}:23125</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>${yarn.resourcemanager.hostname.rm1}:23141</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>${yarn.resourcemanager.hostname.rm2}:23140</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>${yarn.resourcemanager.hostname.rm2}:23130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>${yarn.resourcemanager.hostname.rm2}:23189</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>${yarn.resourcemanager.hostname.rm2}:23188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>${yarn.resourcemanager.hostname.rm2}:23125</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>${yarn.resourcemanager.hostname.rm2}:23141</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>${yarn.home.dir}/etc/hadoop/fairscheduler.xml</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/mydata/yarn_local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/hadoop/mydata/yarn_log</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data/hadoop/mydata/yarn_remotelog</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/data/hadoop/mydata/yarn_userstag</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/hadoop/mydata/yarn_intermediatedone</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/hadoop/mydata/yarn_done</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4.2</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<description>Classpath for typical applications.</description>
<name>yarn.application.classpath</name>
<value>
$HADOOP_HOME/etc/hadoop,
$HADOOP_HOME/share/hadoop/common/*,
$HADOOP_HOME/share/hadoop/common/lib/*,
$HADOOP_HOME/share/hadoop/hdfs/*,
$HADOOP_HOME/share/hadoop/hdfs/lib/*,
$HADOOP_HOME/share/hadoop/mapreduce/*,
$HADOOP_HOME/share/hadoop/mapreduce/lib/*,
$HADOOP_HOME/share/hadoop/yarn/*,
$HADOOP_HOME/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
修改fairscheduler.xml文件
[root@hadoop01 hadoop]# vi fairscheduler.xml
<?xml version="1.0"?>
<allocations>
<queue name="news">
<minResources>1024 mb, 1 vcores </minResources>
<maxResources>1536 mb, 1 vcores </maxResources>
<maxRunningApps>5</maxRunningApps>
<minSharePreemptionTimeout>300</minSharePreemptionTimeout>
<weight>1.0</weight>
<aclSubmitApps>root,yarn,search,hdfs</aclSubmitApps>
</queue>
<queue name="crawler">
<minResources>1024 mb, 1 vcores</minResources>
<maxResources>1536 mb, 1 vcores</maxResources>
</queue>
<queue name="map">
<minResources>1024 mb, 1 vcores</minResources>
<maxResources>1536 mb, 1 vcores</maxResources>
</queue>
</allocations>
创建相关xml配置中目录
mkdir -p /data/hadoop/mydata/yarn
4.解压zookeeper并修改环境变量
[root@hadoop01 ~]# tar zxvf zookeeper-3.4.6.tar.gz
[root@hadoop01 ~]#mv zookeeper-3.4.6 /data/zookeeper
[root@hadoop01 ~]# vi /etc/profile
##zookeeper
export ZOOKEEPER_HOME=/data/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
[root@hadoop01 ~]# source /etc/profile
5.修改zookeeper配置文件
[root@hadoop01 ~]# cd /data/zookeeper/conf/
[root@hadoop01 conf]# cp zoo_sample.cfg zoo.cfg
[root@hadoop01 conf]# vi zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/hadoop/mydata/zookeeper
dataLogDir=/data/hadoop/mydata/zookeeperlog
# the port at which the clients will connect
clientPort=2190
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
server.4=hadoop04:2888:3888
server.5=hadoop05:2888:3888
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance #
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
创建目录
mkdir /data/hadoop/mydata/zookeeper
mkdir /data/hadoop/mydata/zookeeperlog
6.把配置hadoop、zookeeper文件目录到其他四台中
[root@hadoop01 ~]# scp -r /data/hadoop hadoop02:/data/
[root@hadoop01 ~]# scp -r /data/hadoop hadoop03:/data/
[root@hadoop01 ~]# scp -r /data/hadoop hadoop04:/data/
[root@hadoop01 ~]# scp -r /data/hadoop hadoop05:/data/
[root@hadoop01 ~]# scp -r /data/zookeeper hadoop02:/data/
[root@hadoop01 ~]# scp -r /data/zookeeper hadoop03:/data/
[root@hadoop01 ~]# scp -r /data/zookeeper hadoop04:/data/
[root@hadoop01 ~]# scp -r /data/zookeeper hadoop05:/data/
在hadoop02修改yarn-site.xml
[root@hadoop02 hadoop]# cd /data/hadoop/etc/hadoop/
把rm1修改成rm2
[root@hadoop02 hadoop]# vi yarn-site.xml
<name>yarn.resourcemanager.ha.id</name>
<value>rm2</value>
[root@hadoop01 ~]# vi /data/hadoop/mydata/zookeeper/myid
1
[root@hadoop02 ~]# vi /data/hadoop/mydata/zookeeper/myid
2
[root@hadoop03 ~]# vi /data/hadoop/mydata/zookeeper/myid
3
[root@hadoop04 ~]# vi /data/hadoop/mydata/zookeeper/myid
4
[root@hadoop05 ~]# vi /data/hadoop/mydata/zookeeper/myid
5
7、启动zookeeper
五台操作zkServer.sh start
[root@hadoop01 ~]# zkServer.sh start
[root@hadoop01 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[root@hadoop03 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/bin/../conf/zoo.cfg
Mode: leader
You have new mail in /var/spool/mail/root
正常情况只有一台leader状态
8、格式化zookeeper集群
在hadoop机器执行命令
[root@hadoop01 ~]# hdfs zkfc -formatZK
9.启动journalnode进程
在每台启动(五台)
[root@hadoop01 ~]# cd /data/hadoop/sbin/
[root@hadoop01 sbin]# ./hadoop-daemon.sh start journalnode
10.格式化namenode
在hadoop01上执行命令
[root@hadoop01 ~]# hdfs namenode -format
11.启动namenode
在hadoop01执行命令
[root@hadoop01 ~]# cd /data/hadoop/sbin/
[root@hadoop01 sbin]# ./hadoop-daemon.sh start namenode
12.将刚才格式化的namenode信息同步么备用namenode上
[root@hadoop01 ~]# hdfs namenode -bootstrapStandby
13.在hadoop02上启动namenode
[root@hadoop02 ~]# cd /data/hadoop/sbin/
[root@hadoop02 sbin]# ./hadoop-daemon.sh start namenode
14.启动所有datanode
在每台执行这是根据slaves来的
[root@hadoop01 ~]# cd /data/hadoop/sbin/
[root@hadoop01 sbin]# ./hadoop-daemon.sh start datanode
15.启动yarn
在hadoop01上执行命令
root@hadoop01 ~]# cd /data/hadoop/sbin/
[root@hadoop01 sbin]# ./start-yarn.sh
16.启动ZKFC
在hadoop01和hadoop02上启动
[root@hadoop01 ~]# cd /data/hadoop/sbin/
[root@hadoop01 sbin]# ./hadoop-daemon.sh start zkfc
17.启动成功结果


三、安装hbase HA
1.解压hbase修改配置文件
[root@hadoop01 ~]# tar zxvf hbase-1.0.2-bin.tar.gz
[root@hadoop01 ~]# mv hbase-1.0.2 /data/hbase
配置环境变量
[root@hadoop01 ~]# vi /etc/profile
##hbase
export HBASE_HOME=/data/hbase
export PATH=$PATH:$HBASE_HOME/bin
[root@hadoop01 ~]# source /etc/profile
[root@hadoop01 ~]# cd /data/hbase/conf/
[root@hadoop01 conf]# vi hbase-env.sh
# The java implementation to use. Java 1.7+ required.
export JAVA_HOME="/opt/jdk"
# Extra Java CLASSPATH elements. Optional.
#记得以下一定要配置,HMaster会启动不了
export HBASE_CLASSPATH=/data/hadoop/etc/hadoop
# Where log files are stored. $HBASE_HOME/logs by default.
export HBASE_LOG_DIR=/data/hbase/logs
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
export HBASE_MANAGES_ZK=false
修改hbase-site.xml
[root@hadoop01 conf]# vi hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/**
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0 *
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
-->
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://cluster/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/data/hbase/tmp</value>
</property>
<property>
<name>hbase.master.port</name>
<value>60000</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/data/hadoop/mydata/zookeeper</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01,hadoop02,hadoop03,hadoop04,hadoop05</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2190</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
<property>
<name>hbase.regionserver.restart.on.zk.expire</name>
<value>true</value>
</property>
</configuration>
[root@hadoop01 conf]# vi regionservers
hadoop01
hadoop02
hadoop03
hadoop04
hadoop05
~
创建文件目录
mkdir /data/hbase/tmp
增加backup-master
[root@hadoop01 conf]# vi backup-masters
hadoop02
以上都配置完成
2、把文件传到其他服务器上
[root@hadoop01 conf]# scp -r /data/hbase hadoop02:/data/
[root@hadoop01 conf]# scp -r /data/hbase hadoop03:/data/
[root@hadoop01 conf]# scp -r /data/hbase hadoop04:/data/
[root@hadoop01 conf]# scp -r /data/hbase hadoop05:/data/
3.启动hbase
在hadoop01执行命令
[root@hadoop01 conf]# start-hbase.sh
4.启动结果
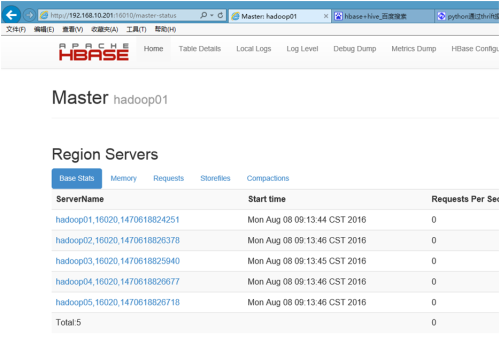

可以通过jps查看
[root@hadoop01 conf]# jps
2540 NodeManager
1686 QuorumPeerMain
2134 JournalNode
2342 DFSZKFailoverController
3041 HMaster
1933 DataNode
3189 HRegionServer
2438 ResourceManager
7848 Jps
1827 NameNode
以后启动过程
每台执行(五台)
[root@hadoop01 ~]# zkServer.sh start
在hadoop01启动
[root@hadoop01 ~]# cd /data/hadoop/sbin/
[root@hadoop01 sbin]# ./start-dfs.sh
[root@hadoop01 sbin]# ./start-yarn.sh
最后启动hbase
[root@hadoop01 sbin]# start-hbase.sh
关闭过程
先关闭hbase
stop-hbase.sh
在hadoop01关闭
[root@hadoop01 ~]# cd /data/hadoop/sbin/
[root@hadoop01 sbin]# ./stop-yarn.sh
[root@hadoop01 sbin]# ./stop-dfs.sh
附件:http://down.51cto.com/data/2368030
一、安装前准备
1.环境5台
2、修改hosts文件
[root@hadoop01 ~]# cat /etc/hosts
192.168.10.201hadoop01
192.168.10.202hadoop02
192.168.10.203hadoop03
192.168.10.204hadoop04
192.168.10.205hadoop05
3、ssh 免密码登录
在每台操作
[root@hadoop01 ~]# mkidr ~/.ssh
[root@hadoop01 ~]# chmod 700 ~/.ssh
[root@hadoop01 ~]#cd ~/.ssh/
[root@hadoop01 .ssh ]ssh-keygen -t rsa
五台操作完成 后做成公钥文件
[root@hadoop01 .ssh ] ssh hadoop02 cat /root/.ssh/id_rsa.pub >> authorized_keys
[root@hadoop01 .ssh ] ssh hadoop03 cat /root/.ssh/id_rsa.pub >> authorized_keys
[root@hadoop01 .ssh ] ssh hadoop04 cat /root/.ssh/id_rsa.pub >> authorized_keys
[root@hadoop01 .ssh ] ssh hadoop05 cat /root/.ssh/id_rsa.pub >> authorized_keys
[root@hadoop01 .ssh ] ssh hadoop01 cat /root/.ssh/id_rsa.pub >> authorized_keys
[root@hadoop01 .ssh]# chmod 600 authorized_keys
[root@hadoop01 .ssh]# scp authorized_keys hadoop02:/root/.ssh/
[root@hadoop01 .ssh]# scp authorized_keys hadoop03:/root/.ssh/
[root@hadoop01 .ssh]# scp authorized_keys hadoop04:/root/.ssh/
[root@hadoop01 .ssh]# scp authorized_keys hadoop05:/root/.ssh/
测试ssh信任
[root@hadoop01 .ssh]# ssh hadoop02 date
Mon Aug 8 11:07:23 CST 2016
[root@hadoop01 .ssh]# ssh hadoop03 date
Mon Aug 8 11:07:26 CST 2016
[root@hadoop01 .ssh]# ssh hadoop04 date
Mon Aug 8 11:07:29 CST 2016
[root@hadoop01 .ssh]# ssh hadoop05 date
5.服务时间同步(五台操作)
yum -y install ntpdate
[root@hadoop01 .ssh]# crontab -l
0 * * * * /usr/sbin/ntpdate 0.rhel.pool.ntp.org && /sbin/clock -w
可以采用别的方案同步时间
6.修改文件打开数(五台操作)
[root@hadoop01 ~]# vi /etc/security/limits.conf
root soft nofile 65535
root hard nofile 65535
root soft nproc 32000
root hard nproc 32000
[root@hadoop01 ~]# vi /etc/pam.d/login
session required pam_limits.so
修改完后重启系统
二、安装hadoop+zookeeper HA
1.安装jdk (五台操作)
解压jdk
[root@hadoop01 ~] cd /opt
[root@hadoop01 opt]# tar zxvf jdk-7u21-linux-x64.tar.gz
[root@hadoop01 opt]# mv jdk1.7.0_21 jdk
配置到环境变量/etc/profile
[root@hadoop01 opt]# vi /etc/profile
#java
JAVA_HOME=/opt/jdk
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME
export PATH
export CLASSPATH
配置文件生效
[root@hadoop01 opt]# source /etc/profile
[root@hadoop01 opt]# java -version
java version "1.7.0_21"
Java(TM) SE Runtime Environment (build 1.7.0_21-b11)
Java HotSpot(TM) 64-Bit Server VM (build 23.21-b01, mixed mode)
以上说明生效
2.解压hadoop并修改环境变量
[root@hadoop01 ~]# tar zxvf hadoop-2.6.3.tar.gz
[root@hadoop01 ~]#mkdir /data
[root@hadoop01 ~]# mv hadoop-2.6.3 /data/hadoop
[root@hadoop01 data]# vi /etc/profile
##hadoop
export HADOOP_HOME=/data/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/bin
[root@hadoop01 data]# source /etc/profile
3.修改hadoop配置文件
[root@hadoop01 data]# cd /data/hadoop/etc/hadoop/
[root@hadoop01 hadoop]# vi slaves
hadoop01
hadoop02
hadoop03
hadoop04
hadoop05
以上利用hadoop01,hadoop02两台磁盘空间,也增加进去了,不介意增加。
[root@hadoop01 hadoop]# vi hadoop-env.sh
[root@hadoop01 hadoop]# vi yarn-env.sh
修改core-site.xml文件
[root@hadoop01 hadoop]# vi core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
<description>The name of the default file system.</description>
<final>true</final>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2190,hadoop02:2190,hadoop03:2190,hadoop04:2190,hadoop05:2190</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>2048</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
</configuration>
修改hdfs-site.xml文件
[root@hadoop01 hadoop]# vi hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>hadoop01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>hadoop02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn1</name>
<value>hadoop01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>hadoop02:50070</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.cluster.nn1</name>
<value>hadoop01:53333</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address.cluster.nn2</name>
<value>hadoop02:53333</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485;hadoop04:8485;hadoop05:8485/cluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/mydata/journal</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hadoop/mydata/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hadoop/mydata/data</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.journalnode.http-address</name>
<value>0.0.0.0:8480</value>
</property>
<property>
<name>dfs.journalnode.rpc-address</name>
<value>0.0.0.0:8485</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
修改mapred-site.xml
[root@hadoop01 hadoop]# vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.cluster.temp.dir</name>
<value>/data/hadoop/mydata/mr_temp</value>
</property>
<property>
<name>mareduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
</configuration>
修改yarn-site.xml文件
[root@hadoop01 hadoop]# vi yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>60000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rm-cluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop02</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2190,hadoop02:2190,hadoop03:2190,hadoop04:2190,hadoop05:2190,</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>${yarn.resourcemanager.hostname.rm1}:23140</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>${yarn.resourcemanager.hostname.rm1}:23130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>${yarn.resourcemanager.hostname.rm1}:23189</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>${yarn.resourcemanager.hostname.rm1}:23188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>${yarn.resourcemanager.hostname.rm1}:23125</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>${yarn.resourcemanager.hostname.rm1}:23141</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>${yarn.resourcemanager.hostname.rm2}:23140</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>${yarn.resourcemanager.hostname.rm2}:23130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>${yarn.resourcemanager.hostname.rm2}:23189</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>${yarn.resourcemanager.hostname.rm2}:23188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>${yarn.resourcemanager.hostname.rm2}:23125</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>${yarn.resourcemanager.hostname.rm2}:23141</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>${yarn.home.dir}/etc/hadoop/fairscheduler.xml</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/mydata/yarn_local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/hadoop/mydata/yarn_log</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data/hadoop/mydata/yarn_remotelog</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/data/hadoop/mydata/yarn_userstag</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/hadoop/mydata/yarn_intermediatedone</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/hadoop/mydata/yarn_done</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4.2</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<description>Classpath for typical applications.</description>
<name>yarn.application.classpath</name>
<value>
$HADOOP_HOME/etc/hadoop,
$HADOOP_HOME/share/hadoop/common/*,
$HADOOP_HOME/share/hadoop/common/lib/*,
$HADOOP_HOME/share/hadoop/hdfs/*,
$HADOOP_HOME/share/hadoop/hdfs/lib/*,
$HADOOP_HOME/share/hadoop/mapreduce/*,
$HADOOP_HOME/share/hadoop/mapreduce/lib/*,
$HADOOP_HOME/share/hadoop/yarn/*,
$HADOOP_HOME/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
修改fairscheduler.xml文件
[root@hadoop01 hadoop]# vi fairscheduler.xml
<?xml version="1.0"?>
<allocations>
<queue name="news">
<minResources>1024 mb, 1 vcores </minResources>
<maxResources>1536 mb, 1 vcores </maxResources>
<maxRunningApps>5</maxRunningApps>
<minSharePreemptionTimeout>300</minSharePreemptionTimeout>
<weight>1.0</weight>
<aclSubmitApps>root,yarn,search,hdfs</aclSubmitApps>
</queue>
<queue name="crawler">
<minResources>1024 mb, 1 vcores</minResources>
<maxResources>1536 mb, 1 vcores</maxResources>
</queue>
<queue name="map">
<minResources>1024 mb, 1 vcores</minResources>
<maxResources>1536 mb, 1 vcores</maxResources>
</queue>
</allocations>
创建相关xml配置中目录
mkdir -p /data/hadoop/mydata/yarn
4.解压zookeeper并修改环境变量
[root@hadoop01 ~]# tar zxvf zookeeper-3.4.6.tar.gz
[root@hadoop01 ~]#mv zookeeper-3.4.6 /data/zookeeper
[root@hadoop01 ~]# vi /etc/profile
##zookeeper
export ZOOKEEPER_HOME=/data/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
[root@hadoop01 ~]# source /etc/profile
5.修改zookeeper配置文件
[root@hadoop01 ~]# cd /data/zookeeper/conf/
[root@hadoop01 conf]# cp zoo_sample.cfg zoo.cfg
[root@hadoop01 conf]# vi zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/hadoop/mydata/zookeeper
dataLogDir=/data/hadoop/mydata/zookeeperlog
# the port at which the clients will connect
clientPort=2190
server.1=hadoop01:2888:3888
server.2=hadoop02:2888:3888
server.3=hadoop03:2888:3888
server.4=hadoop04:2888:3888
server.5=hadoop05:2888:3888
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance #
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
创建目录
mkdir /data/hadoop/mydata/zookeeper
mkdir /data/hadoop/mydata/zookeeperlog
6.把配置hadoop、zookeeper文件目录到其他四台中
[root@hadoop01 ~]# scp -r /data/hadoop hadoop02:/data/
[root@hadoop01 ~]# scp -r /data/hadoop hadoop03:/data/
[root@hadoop01 ~]# scp -r /data/hadoop hadoop04:/data/
[root@hadoop01 ~]# scp -r /data/hadoop hadoop05:/data/
[root@hadoop01 ~]# scp -r /data/zookeeper hadoop02:/data/
[root@hadoop01 ~]# scp -r /data/zookeeper hadoop03:/data/
[root@hadoop01 ~]# scp -r /data/zookeeper hadoop04:/data/
[root@hadoop01 ~]# scp -r /data/zookeeper hadoop05:/data/
在hadoop02修改yarn-site.xml
[root@hadoop02 hadoop]# cd /data/hadoop/etc/hadoop/
把rm1修改成rm2
[root@hadoop02 hadoop]# vi yarn-site.xml
<name>yarn.resourcemanager.ha.id</name>
<value>rm2</value>
[root@hadoop01 ~]# vi /data/hadoop/mydata/zookeeper/myid
1
[root@hadoop02 ~]# vi /data/hadoop/mydata/zookeeper/myid
2
[root@hadoop03 ~]# vi /data/hadoop/mydata/zookeeper/myid
3
[root@hadoop04 ~]# vi /data/hadoop/mydata/zookeeper/myid
4
[root@hadoop05 ~]# vi /data/hadoop/mydata/zookeeper/myid
5
7、启动zookeeper
五台操作zkServer.sh start
[root@hadoop01 ~]# zkServer.sh start
[root@hadoop01 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/bin/../conf/zoo.cfg
Mode: follower
[root@hadoop03 ~]# zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/zookeeper/bin/../conf/zoo.cfg
Mode: leader
You have new mail in /var/spool/mail/root
正常情况只有一台leader状态
8、格式化zookeeper集群
在hadoop机器执行命令
[root@hadoop01 ~]# hdfs zkfc -formatZK
9.启动journalnode进程
在每台启动(五台)
[root@hadoop01 ~]# cd /data/hadoop/sbin/
[root@hadoop01 sbin]# ./hadoop-daemon.sh start journalnode
10.格式化namenode
在hadoop01上执行命令
[root@hadoop01 ~]# hdfs namenode -format
11.启动namenode
在hadoop01执行命令
[root@hadoop01 ~]# cd /data/hadoop/sbin/
[root@hadoop01 sbin]# ./hadoop-daemon.sh start namenode
12.将刚才格式化的namenode信息同步么备用namenode上
[root@hadoop01 ~]# hdfs namenode -bootstrapStandby
13.在hadoop02上启动namenode
[root@hadoop02 ~]# cd /data/hadoop/sbin/
[root@hadoop02 sbin]# ./hadoop-daemon.sh start namenode
14.启动所有datanode
在每台执行这是根据slaves来的
[root@hadoop01 ~]# cd /data/hadoop/sbin/
[root@hadoop01 sbin]# ./hadoop-daemon.sh start datanode
15.启动yarn
在hadoop01上执行命令
root@hadoop01 ~]# cd /data/hadoop/sbin/
[root@hadoop01 sbin]# ./start-yarn.sh
16.启动ZKFC
在hadoop01和hadoop02上启动
[root@hadoop01 ~]# cd /data/hadoop/sbin/
[root@hadoop01 sbin]# ./hadoop-daemon.sh start zkfc
17.启动成功结果
三、安装hbase HA
1.解压hbase修改配置文件
[root@hadoop01 ~]# tar zxvf hbase-1.0.2-bin.tar.gz
[root@hadoop01 ~]# mv hbase-1.0.2 /data/hbase
配置环境变量
[root@hadoop01 ~]# vi /etc/profile
##hbase
export HBASE_HOME=/data/hbase
export PATH=$PATH:$HBASE_HOME/bin
[root@hadoop01 ~]# source /etc/profile
[root@hadoop01 ~]# cd /data/hbase/conf/
[root@hadoop01 conf]# vi hbase-env.sh
# The java implementation to use. Java 1.7+ required.
export JAVA_HOME="/opt/jdk"
# Extra Java CLASSPATH elements. Optional.
#记得以下一定要配置,HMaster会启动不了
export HBASE_CLASSPATH=/data/hadoop/etc/hadoop
# Where log files are stored. $HBASE_HOME/logs by default.
export HBASE_LOG_DIR=/data/hbase/logs
# Tell HBase whether it should manage it's own instance of Zookeeper or not.
export HBASE_MANAGES_ZK=false
修改hbase-site.xml
[root@hadoop01 conf]# vi hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
/**
*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0 *
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
-->
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://cluster/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/data/hbase/tmp</value>
</property>
<property>
<name>hbase.master.port</name>
<value>60000</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/data/hadoop/mydata/zookeeper</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01,hadoop02,hadoop03,hadoop04,hadoop05</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2190</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
<property>
<name>hbase.regionserver.restart.on.zk.expire</name>
<value>true</value>
</property>
</configuration>
[root@hadoop01 conf]# vi regionservers
hadoop01
hadoop02
hadoop03
hadoop04
hadoop05
~
创建文件目录
mkdir /data/hbase/tmp
增加backup-master
[root@hadoop01 conf]# vi backup-masters
hadoop02
以上都配置完成
2、把文件传到其他服务器上
[root@hadoop01 conf]# scp -r /data/hbase hadoop02:/data/
[root@hadoop01 conf]# scp -r /data/hbase hadoop03:/data/
[root@hadoop01 conf]# scp -r /data/hbase hadoop04:/data/
[root@hadoop01 conf]# scp -r /data/hbase hadoop05:/data/
3.启动hbase
在hadoop01执行命令
[root@hadoop01 conf]# start-hbase.sh
4.启动结果
可以通过jps查看
[root@hadoop01 conf]# jps
2540 NodeManager
1686 QuorumPeerMain
2134 JournalNode
2342 DFSZKFailoverController
3041 HMaster
1933 DataNode
3189 HRegionServer
2438 ResourceManager
7848 Jps
1827 NameNode
以后启动过程
每台执行(五台)
[root@hadoop01 ~]# zkServer.sh start
在hadoop01启动
[root@hadoop01 ~]# cd /data/hadoop/sbin/
[root@hadoop01 sbin]# ./start-dfs.sh
[root@hadoop01 sbin]# ./start-yarn.sh
最后启动hbase
[root@hadoop01 sbin]# start-hbase.sh
关闭过程
先关闭hbase
stop-hbase.sh
在hadoop01关闭
[root@hadoop01 ~]# cd /data/hadoop/sbin/
[root@hadoop01 sbin]# ./stop-yarn.sh
[root@hadoop01 sbin]# ./stop-dfs.sh
附件:http://down.51cto.com/data/2368030

相关文章推荐
- Hadoop2.6+zookeeper3.4.6+hbase1.1.0.1完全分布式配置方案
- hadoop2.6+ zookeeper3.4.6搭建
- Mac系统下,Hadoop 2.6.2 + ZooKeeper 3.4.6 + HBase 1.1.5 完全分布式环境搭建
- Hadoop 2.5.1高可用,hadoop2.5.1+zookeeper3.4.6+hbase1.2.1
- Hadoop 2.4.0+zookeeper3.4.6+hbase0.98.3分布式集群搭建
- Dubbo项目实战 (二) 注册中心zookeeper-3.4.6集群以及高可用
- hadoop 2.5.1+zookeeper-3.4.6+hbase-0.98.8-hadoop2 完全安装
- Hadoop-2.6.0 + Zookeeper-3.4.6 + HBase-0.98.9-hadoop2环境搭建示例
- Zookeeper 3.4.6 试水 & Hbase 0.98.3 for Hadoop 2 单节点配置
- Hadoop-2.6.0+Zookeeper-3.4.6+Spark-1.5.0+Hbase-1.1.2+Hive-1.2.0集群搭建
- Dubbo项目实战 (二) 注册中心zookeeper-3.4.6集群以及高可用
- [置顶] Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
- centos 7 第一次启动hadoop生态之zookeeper-3.4.6
- Zookeeper(四)Hadoop HA高可用集群搭建
- Hadoop 2.4.0+zookeeper3.4.6+hbase0.98.3分布式集群搭建
- Hadoop-2.6.0 + Zookeeper-3.4.6 + HBase-0.98.9-hadoop2环境搭建示例
- Mac系统下,Hadoop 2.6.2 + Zookeeper 3.4.6 完全分布式配置
- 集群环境下Hadoop2.5.2+Zookeeper3.4.6+Hbase0.98+Hive1.0.0安装目录总汇
- hadoop2.5.2+zookeeper3.4.6+hbase0.99.2
- 开始玩hadoop10 高可用(HA)配置;Hadoop2.6+HA+Zookeeper3.4.6+Hbase1.0.0