监督学习之线性回归
2016-08-06 16:35
260 查看
一、监督学习
让我们首先谈一些监督学习问题的例子。假定我们有一个数据集,数据集中给出了来自俄勒冈波特兰的47所房子的居住面积(living areas)和价格(price):
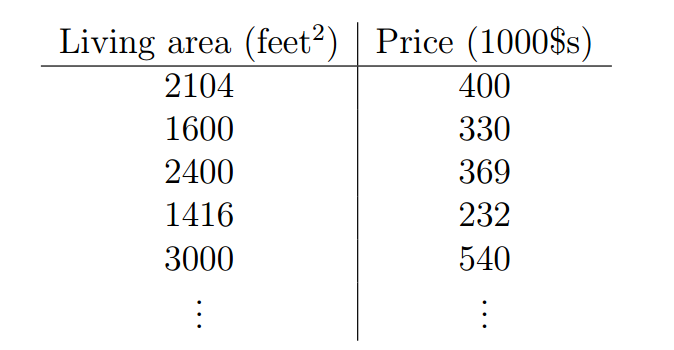
我们可以将这些数据标识于图表上:
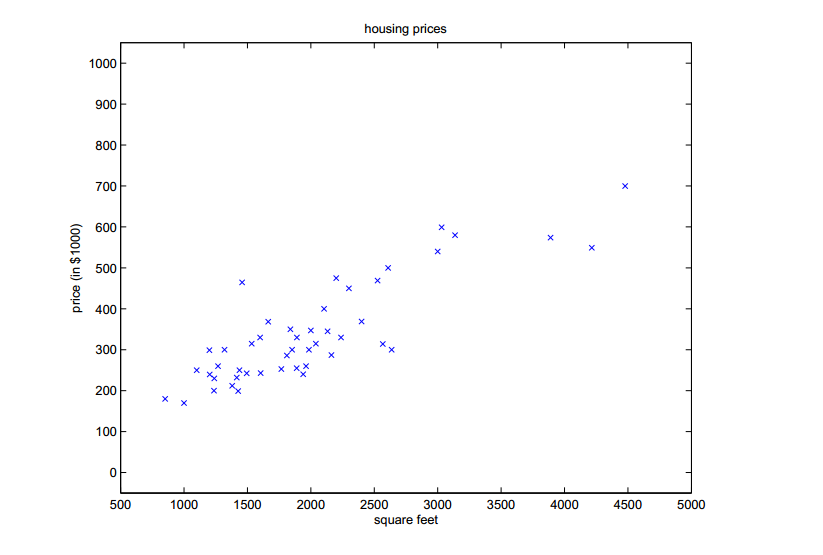
给定这样的数据,我们如何学习基于居住面积的大小的函数,来预测波兰特其它房子的价格。
为了建立以后使用的符号,我们使用
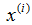
表示“输入”变量(这个例子中的居住面积),也被称作输入特征,
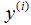
表示我们尽力预测的“输出”或者目标变量(价格)。一组
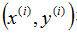
被称作一个训练例子,我们将要用来学习的数据集——m个训练例子
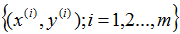
——被称作一个训练集。注意符号中的上标
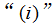
仅仅是一个指向训练集的索引,和指数没有关系。我们使用表示输入值的空间,表示输出值的空间。在这个例子中,
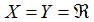
。
为了稍微更加正式的描述监督学习问题,我们的目标是在给定一组训练集的情况下,学习一个函数

,
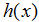
是一个对相对应值的好的预测器。由于历史原因,这个函数
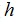
被叫做一个假设。可以形象地看出,过程就像这样:
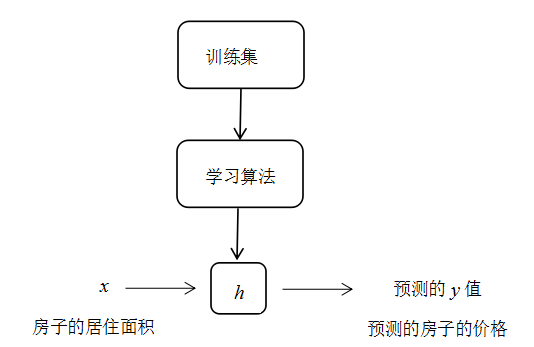
当我们正努力预测的目标变量是连续时,正如在我们房子的例子中,我们成这种学习问题为一个回归问题。当
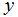
只能取少量的离散值时(比如,如果给定居住面积,我们想预测一个住处时一个house还是一个apartment),我们把它称作一个分类问题。
第一部分 线性回归
为了使我们的房子案例更有趣,让我们考虑一个更加丰富的数据集,在这个数据集里我们还知道每个房子里的卧室的数量:
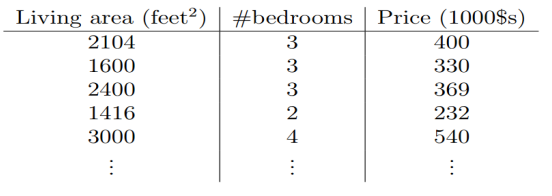
这里,
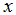
是
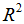
里的二维向量。比如说,
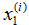
是训练集中第
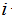
个房子的居住面积,
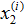
是卧室的数量。(一般来说,当设计一个学习问题时,决定选择什么特征取决于你,所以如果你在波兰特收集房子数据,你也可能决定包含其他的特征,比如是否每个房子有一个壁炉,浴室的数量等等。我们之后将会关于特征选择谈到更多,但是现在让我们假定特征已经给定。)
为了进行监督学习,我们必须决定我们将如何在电脑里表示函数/假设
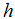
。作为一个初始的选择,我们决定来使用
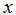
的线性函数来近似
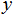
:
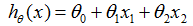
这里,
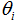
是参数(也成为权重),用来参数化
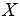
到
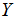
映射的线性函数空间。当不存在混淆的风险时,我们也会去掉
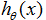
中的下标
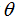
,把它更简单的写作
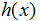
。为了简化我们的符号,我们也引入

的惯例(这个是截距项),以致
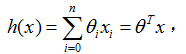
在上式的右端项我们把
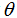
和
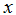
都当作向量,
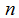
是输入变量的个数(不算

)。
现在,给定一个训练集,我们如何选择或者学习参数
?一个合理的方法看起来是使得
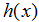
接近
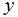
,至少对于我们训练的例子是成立的。为了使其形式化,我们将会定义一个函数,用来测量对于每组
值,
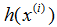
和相对应
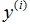
的值有多接近。我们定义代价函数:
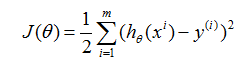
如果你之前看过线性回归,你可以认出这是熟悉的最小二乘代价函数,它引出了普通最小二乘回归模型。无论你之前是否看过线性回归,让我们继续,我们最终会说明这是一个更宽广算法家族的一种特殊情况。
1 LMS( Least mean square,最小均方)算法
我们想选择

以便最小化

。为此,我们使用一个以对
进行某些初始猜测作为开始的搜索算法,然后反复改变
来使
越来越小,直到希望上收敛到一个使
最小的
值。明确地,让我们考虑梯度下降算法,它以某些初始的
值作为开始,反复地执行更新:
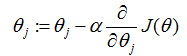
(这个更新是对所有
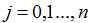
的值同时执行的。)这里,
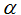
被称作学习率。反复地以
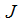
下降最快的方向走一步是一个非常自然的算法。
为了执行这个算法,我们必须算出右边的偏导数项是什么。让我们首先计算我们只有一个训练样本

的情况,以致我们可以忽略
定义中的和。我们有:
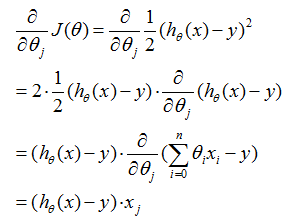
对于一个训练样本(的情况),给出更新规则:
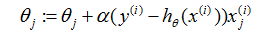
这条规则被称作LMS更新规则(LMS代表“最小均方”),也被叫做widrow-hoff学习规则。这条规则有一些看起来很自然和直观的特征。比如,更新的量级和误差项
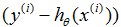
成比例;从而,比如说,如果我们正好遇到一个预测值几乎匹配

实际值的训练样本,然后我们发现几乎不需要改变参数;相反,如果我们的预测值

有很大的误差(也就是说和
相差较大),参数需要做较大的改变。
我们已经得到了当只有一个训练样本的LMS规则。对于多于一个训练样本的训练集,有两种方式可以修改这个方法。第一种方法是用以下的算法替换它:
重复直到收敛{
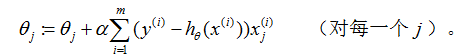
}
读者可以很简单证明上面更新规则中的求和量就是
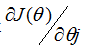
(对于
的初始定义)。所以,这仅仅是对原始的代价函数用了梯度下降。这个方法在每一步都会看整个训练集中的每个样本,被称作批梯度下降。注意到,尽管梯度下降一般对局部最小值很敏感,但我们在这里关于线性回归提出的最优化问题只有一个全局的最优,没有其他局部最优;因此梯度下降总是收敛(假定学习率
不是太大)至全局最小值。实际上,
是一个凸二次函数。这里有一个最小化某二次函数的梯度下降的例子。
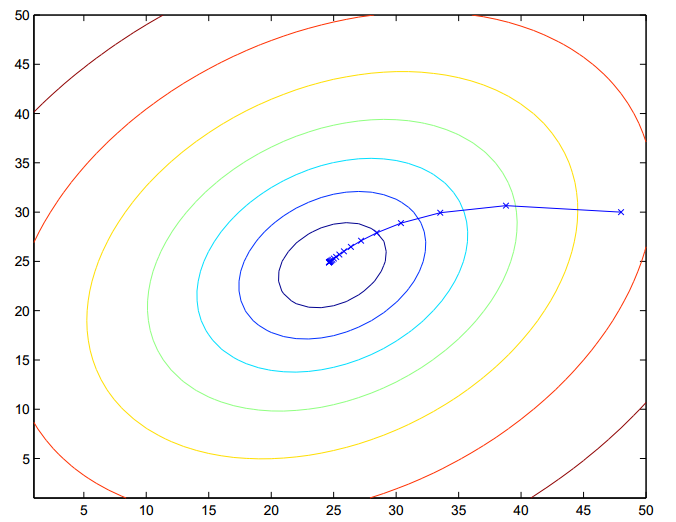
上面显示的椭圆形是一个二次函数的轮廓。梯度下降的轨迹也被显示了,初始值(48,30)。图形中x(叉号,被直线连接的)标记着梯度下降经过的连续的
值。
为了学习预测房子价格的关于居住面积的函数,当我们对原来的数据集运行批梯度下降来寻求恰当的
值时,我们得到
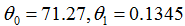
。当我们画出
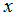
(面积)的函数
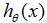
,同时画出训练数据,我们得到下面的图形:

如果卧室的数量也被包含成为一个输入特征,我们得到
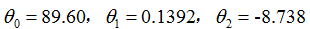
。
上面的结果是通过块梯度下降得到的。还有一种可以替代块梯度下降也工作不错的的算法。考虑以下的算法:
Loop{
For i=1 to m,{
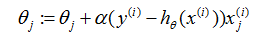
, (for every j)
}
}
在这个算法中,我们反复地遍历训练集,每次我们针对一个训练样本。我们根据只基于单个训练例子的误差的梯度来更新参数。这个算法被称作随机梯度下降(也称作增量梯度下降)。批梯度下降在走一步之前必须扫描整个的训练集——如果m值太大的话,就是代价很高的操作——然而随机梯度下降可以立即前进,然后通过看每一个例子继续前进。经常,随机梯度下降得到接近最小值的远比批梯度下降更快。(注意到尽管它可能永远收敛不到最小值,参数
持续在的
最小值附近震荡,但是在实际中,大多数接近最小值的值是对真实最小值的相当好的近似)。由于这个原因,特别是当训练集较大时,随机梯度下降胜过批梯度下降。
2
正规方程
梯度下降给了一种最小化
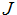
的方式。让我们讨论另外一种最小化
的方式,这次明确地进行行最小化,而且不用求助于迭代算法。在这个方法中,我们通过明确地的求关于
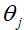
的偏导数并令其为0来使
最小化。为了让我们能够做这些而不写大量的代数和满页的矩阵导数(此处不懂),让我们引进一些矩阵微积分学的符号。
2.1 矩阵的导数
对于一个函数
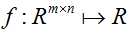
,从m x n的矩阵映射至实数,我们定义
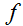
关于

的导数:
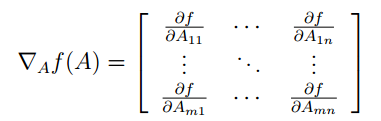
因此,梯度
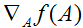
是一个m x n的矩阵,它的元素
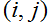
是
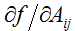
。例如,假定
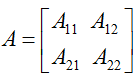
是一个2
x 2的矩阵,函数
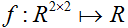
为
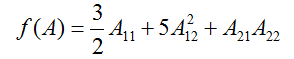
这里,
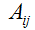
表示矩阵
的

元素。我们然后得到
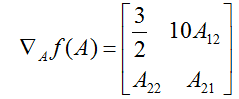
我们也引入运算符迹,写作
。对于一个n x n的(方)矩阵
,
的迹被定义为它的对角线元素的和:
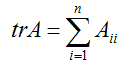
如果
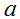
是一个实数(也就是说,
是一个1 x 1的矩阵),然后
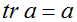
。(如果你之前没有看到过这个“运算符符号”,你应该把
的迹看作
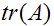
,或者是“迹”函数作用于矩阵
。然而,不写括号的迹更常见。)
迹运算符有这样的特征,对于两个矩阵
和
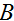
,满足
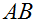
是方阵,我们有
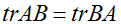
。(自己证明)
作为这个的推论,我们还可得到,比如,
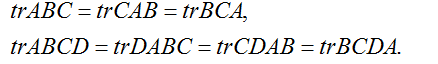
迹运算符的一下特征也同样容易证明。这里,
和
都是方阵,
是一个实数:

我们现在不加证明的陈述一下矩阵导数的一些事实(我们直到本节的晚些时候才需要它们中的一些)。等式(4)只应用于非奇异方阵
,其中

表示
的行列式。我们有:
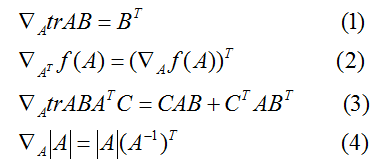
为了使我们的矩阵符号更具体化,让我们现在详细的解释一下这些等式中的第一个式子的意义。假定我们有某个固定的矩阵

。然后我们可以定义一个函数
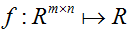
为
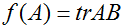
。注意到这个定义是有意义的,因为如果
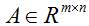
,那么
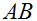
就是一个方阵,我们就可以把迹运算符应用到它;因此,
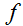
的确从

映射到

。然后我们可以运用我们矩阵导数的定义来求得
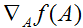
,它也是一个m
x n的矩阵。上面等式(1)说明了这个矩阵的

元素将会是
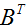
的
元素,或者相等地,由

给出。
等式(1-3)的证明相当简单,给读者留作习题。等式(4)可以通过矩阵逆的伴随矩阵表示得到。
2.2 最小二乘再回顾
有了矩阵导数的工具,让我们继续求解使
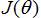
最小的
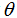
的解析解。我们先以矩阵-向量符号重新写出

。
给定一个训练集,定义一个m x n的设计矩阵
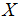
(如果我们包括截距项,实际上是m
x n+1),每行是训练例子的输入值:
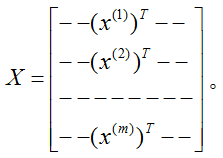
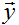
是m维的向量,包括训练集中所有目标值:
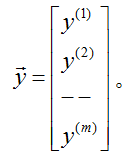
现在,因为
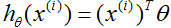
,我们可以很容易地证明
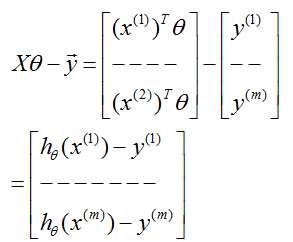
因此,使用关于向量
的事实,我们有

:

最后,为了最小化
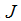
,让我们求得它关于
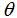
的偏导数。结合等式(2)和(3)得,我们发现
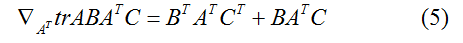
因此,
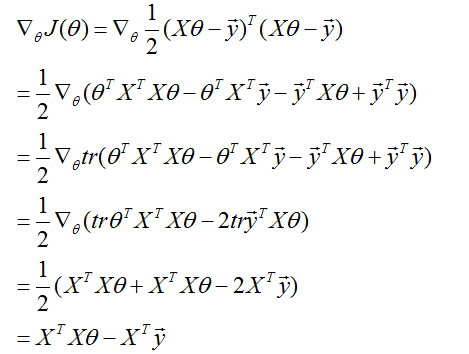
在第三步中,我们使用了一个实数的迹就是这个实数的事实;第四步使用了
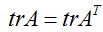
的事实,第五步使用了等式(5),令
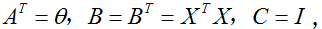
,和等式(1).为了最小化
,我们令它的导数为0,得到正规方程:
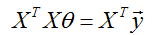
因此,使
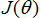
最小的
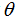
的解析解由该等式给出
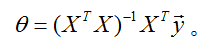
接下来讲到线性回归的概率解释和局部加权线性回归,详见下一讲。
想写一写机器学习的翻译来巩固一下自己的知识,同时给需要的朋友们提供参考,鉴于作者水平有限,翻译不对或不恰当的地方,欢迎指正和建议。
让我们首先谈一些监督学习问题的例子。假定我们有一个数据集,数据集中给出了来自俄勒冈波特兰的47所房子的居住面积(living areas)和价格(price):
我们可以将这些数据标识于图表上:
给定这样的数据,我们如何学习基于居住面积的大小的函数,来预测波兰特其它房子的价格。
为了建立以后使用的符号,我们使用
表示“输入”变量(这个例子中的居住面积),也被称作输入特征,
表示我们尽力预测的“输出”或者目标变量(价格)。一组
被称作一个训练例子,我们将要用来学习的数据集——m个训练例子
——被称作一个训练集。注意符号中的上标
仅仅是一个指向训练集的索引,和指数没有关系。我们使用表示输入值的空间,表示输出值的空间。在这个例子中,
。
为了稍微更加正式的描述监督学习问题,我们的目标是在给定一组训练集的情况下,学习一个函数
,
是一个对相对应值的好的预测器。由于历史原因,这个函数
被叫做一个假设。可以形象地看出,过程就像这样:
当我们正努力预测的目标变量是连续时,正如在我们房子的例子中,我们成这种学习问题为一个回归问题。当
只能取少量的离散值时(比如,如果给定居住面积,我们想预测一个住处时一个house还是一个apartment),我们把它称作一个分类问题。
第一部分 线性回归
为了使我们的房子案例更有趣,让我们考虑一个更加丰富的数据集,在这个数据集里我们还知道每个房子里的卧室的数量:
这里,
是
里的二维向量。比如说,
是训练集中第
个房子的居住面积,
是卧室的数量。(一般来说,当设计一个学习问题时,决定选择什么特征取决于你,所以如果你在波兰特收集房子数据,你也可能决定包含其他的特征,比如是否每个房子有一个壁炉,浴室的数量等等。我们之后将会关于特征选择谈到更多,但是现在让我们假定特征已经给定。)
为了进行监督学习,我们必须决定我们将如何在电脑里表示函数/假设
。作为一个初始的选择,我们决定来使用
的线性函数来近似
:
这里,
是参数(也成为权重),用来参数化
到
映射的线性函数空间。当不存在混淆的风险时,我们也会去掉
中的下标
,把它更简单的写作
。为了简化我们的符号,我们也引入
的惯例(这个是截距项),以致
在上式的右端项我们把
和
都当作向量,
是输入变量的个数(不算
)。
现在,给定一个训练集,我们如何选择或者学习参数
?一个合理的方法看起来是使得
接近
,至少对于我们训练的例子是成立的。为了使其形式化,我们将会定义一个函数,用来测量对于每组
值,
和相对应
的值有多接近。我们定义代价函数:
如果你之前看过线性回归,你可以认出这是熟悉的最小二乘代价函数,它引出了普通最小二乘回归模型。无论你之前是否看过线性回归,让我们继续,我们最终会说明这是一个更宽广算法家族的一种特殊情况。
1 LMS( Least mean square,最小均方)算法
我们想选择
以便最小化
。为此,我们使用一个以对
进行某些初始猜测作为开始的搜索算法,然后反复改变
来使
越来越小,直到希望上收敛到一个使
最小的
值。明确地,让我们考虑梯度下降算法,它以某些初始的
值作为开始,反复地执行更新:
(这个更新是对所有
的值同时执行的。)这里,
被称作学习率。反复地以
下降最快的方向走一步是一个非常自然的算法。
为了执行这个算法,我们必须算出右边的偏导数项是什么。让我们首先计算我们只有一个训练样本
的情况,以致我们可以忽略
定义中的和。我们有:
对于一个训练样本(的情况),给出更新规则:
这条规则被称作LMS更新规则(LMS代表“最小均方”),也被叫做widrow-hoff学习规则。这条规则有一些看起来很自然和直观的特征。比如,更新的量级和误差项
成比例;从而,比如说,如果我们正好遇到一个预测值几乎匹配
实际值的训练样本,然后我们发现几乎不需要改变参数;相反,如果我们的预测值
有很大的误差(也就是说和
相差较大),参数需要做较大的改变。
我们已经得到了当只有一个训练样本的LMS规则。对于多于一个训练样本的训练集,有两种方式可以修改这个方法。第一种方法是用以下的算法替换它:
重复直到收敛{
}
读者可以很简单证明上面更新规则中的求和量就是
(对于
的初始定义)。所以,这仅仅是对原始的代价函数用了梯度下降。这个方法在每一步都会看整个训练集中的每个样本,被称作批梯度下降。注意到,尽管梯度下降一般对局部最小值很敏感,但我们在这里关于线性回归提出的最优化问题只有一个全局的最优,没有其他局部最优;因此梯度下降总是收敛(假定学习率
不是太大)至全局最小值。实际上,
是一个凸二次函数。这里有一个最小化某二次函数的梯度下降的例子。
上面显示的椭圆形是一个二次函数的轮廓。梯度下降的轨迹也被显示了,初始值(48,30)。图形中x(叉号,被直线连接的)标记着梯度下降经过的连续的
值。
为了学习预测房子价格的关于居住面积的函数,当我们对原来的数据集运行批梯度下降来寻求恰当的
值时,我们得到
。当我们画出
(面积)的函数
,同时画出训练数据,我们得到下面的图形:
如果卧室的数量也被包含成为一个输入特征,我们得到
。
上面的结果是通过块梯度下降得到的。还有一种可以替代块梯度下降也工作不错的的算法。考虑以下的算法:
Loop{
For i=1 to m,{
, (for every j)
}
}
在这个算法中,我们反复地遍历训练集,每次我们针对一个训练样本。我们根据只基于单个训练例子的误差的梯度来更新参数。这个算法被称作随机梯度下降(也称作增量梯度下降)。批梯度下降在走一步之前必须扫描整个的训练集——如果m值太大的话,就是代价很高的操作——然而随机梯度下降可以立即前进,然后通过看每一个例子继续前进。经常,随机梯度下降得到接近最小值的远比批梯度下降更快。(注意到尽管它可能永远收敛不到最小值,参数
持续在的
最小值附近震荡,但是在实际中,大多数接近最小值的值是对真实最小值的相当好的近似)。由于这个原因,特别是当训练集较大时,随机梯度下降胜过批梯度下降。
2
正规方程
梯度下降给了一种最小化
的方式。让我们讨论另外一种最小化
的方式,这次明确地进行行最小化,而且不用求助于迭代算法。在这个方法中,我们通过明确地的求关于
的偏导数并令其为0来使
最小化。为了让我们能够做这些而不写大量的代数和满页的矩阵导数(此处不懂),让我们引进一些矩阵微积分学的符号。
2.1 矩阵的导数
对于一个函数
,从m x n的矩阵映射至实数,我们定义
关于
的导数:
因此,梯度
是一个m x n的矩阵,它的元素
是
。例如,假定
是一个2
x 2的矩阵,函数
为
这里,
表示矩阵
的
元素。我们然后得到
我们也引入运算符迹,写作
。对于一个n x n的(方)矩阵
,
的迹被定义为它的对角线元素的和:
如果
是一个实数(也就是说,
是一个1 x 1的矩阵),然后
。(如果你之前没有看到过这个“运算符符号”,你应该把
的迹看作
,或者是“迹”函数作用于矩阵
。然而,不写括号的迹更常见。)
迹运算符有这样的特征,对于两个矩阵
和
,满足
是方阵,我们有
。(自己证明)
作为这个的推论,我们还可得到,比如,
迹运算符的一下特征也同样容易证明。这里,
和
都是方阵,
是一个实数:
我们现在不加证明的陈述一下矩阵导数的一些事实(我们直到本节的晚些时候才需要它们中的一些)。等式(4)只应用于非奇异方阵
,其中
表示
的行列式。我们有:
为了使我们的矩阵符号更具体化,让我们现在详细的解释一下这些等式中的第一个式子的意义。假定我们有某个固定的矩阵
。然后我们可以定义一个函数
为
。注意到这个定义是有意义的,因为如果
,那么
就是一个方阵,我们就可以把迹运算符应用到它;因此,
的确从
映射到
。然后我们可以运用我们矩阵导数的定义来求得
,它也是一个m
x n的矩阵。上面等式(1)说明了这个矩阵的
元素将会是
的
元素,或者相等地,由
给出。
等式(1-3)的证明相当简单,给读者留作习题。等式(4)可以通过矩阵逆的伴随矩阵表示得到。
2.2 最小二乘再回顾
有了矩阵导数的工具,让我们继续求解使
最小的
的解析解。我们先以矩阵-向量符号重新写出
。
给定一个训练集,定义一个m x n的设计矩阵
(如果我们包括截距项,实际上是m
x n+1),每行是训练例子的输入值:
是m维的向量,包括训练集中所有目标值:
现在,因为
,我们可以很容易地证明
因此,使用关于向量
的事实,我们有
:
最后,为了最小化
,让我们求得它关于
的偏导数。结合等式(2)和(3)得,我们发现
因此,
在第三步中,我们使用了一个实数的迹就是这个实数的事实;第四步使用了
的事实,第五步使用了等式(5),令
,和等式(1).为了最小化
,我们令它的导数为0,得到正规方程:
因此,使
最小的
的解析解由该等式给出
接下来讲到线性回归的概率解释和局部加权线性回归,详见下一讲。
想写一写机器学习的翻译来巩固一下自己的知识,同时给需要的朋友们提供参考,鉴于作者水平有限,翻译不对或不恰当的地方,欢迎指正和建议。

相关文章推荐
- 非监督特征学习与深度学习(一)----线性回归
- 十大统计技术,包括线性回归、分类、重采样、降维、无监督学习等。
- MachineLearning-监督学习之线性回归
- 从线性回归到无监督学习,数据科学家需要掌握的十大统计技术
- Ng深度学习笔记 1-线性回归、监督学习、成本函数、梯度下降
- 一文综述数据科学家必备的10大统计技术:线性回归、分类、无监督学习...
- 干货丨从线性回归到无监督学习,数据科学家需要掌握的十大统计技术
- 监督学习之线性回归(续)
- 机器学习相关内容介绍,包括有监督、无监督学习,线性回归分类问题等
- 机器学习入门:线性回归及梯度下降
- 数据科学之机器学习4:线性回归3
- 对数线性模型之一(逻辑回归), 广义线性模型学习总结
- 网易公开课“机器学习”学习笔记(一)线性回归
- 机器学习--线性回归、逻辑回归
- 机器学习入门:线性回归及梯度下降
- 对数线性模型之一(逻辑回归), 广义线性模型学习总结
- 深度学习3线性回归,逻辑回归
- 深度学习2线性回归,逻辑回归
- 机器学习入门:线性回归及梯度下降
- 对数线性模型之一(逻辑回归), 广义线性模型学习总结