文章标题
2016-08-05 21:19
288 查看
最大流最小割定理
在一个网络流中,能够从源点s到达汇点t的最大流量,等于,如果从网络中移除就能够导致网络流中断的边的集合的最小容量和
水流管道的最大流量(流动的水量)由最细的管子容量决定。
对于每条边(u,v),有一个*容量*c(u,v)
对于每条边(u,v),有一个*流量*f(u,v).
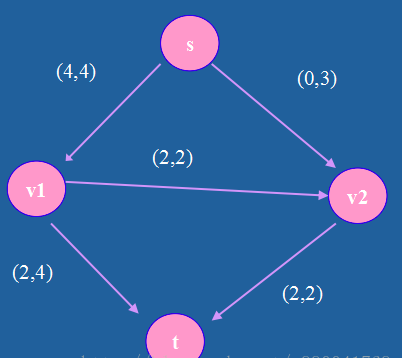
网络流的三个性质:
1、容量限制: f[u,v]<=c[u,v]
2、反对称性:f[u,v] = - f[v,u]
3、流量平衡: 对于不是源点也不是汇点的任意结点,流入该结点的流量和等于流出该结点的流量和。
只要满足这三个性质,就是一个合法的网络流.
最大流问题,就是求在满足网络流性质的情况下,源点 s 到汇点 t 的最大流量。
而数据项部分则表示对应顶点属于前景或者背景的惩罚项。
于Graph Cuts需要有2个终端节点”S”和”T”,分别表示初始的目标区域和背景区域,在计算机视觉的图像分割领域时,需要人工指定初始的s顶点和t顶点
**
Markov Random Field
马尔克夫随机场定义:它包含两层意思:一是什么是马尔可夫,二是什么是随机场。
马尔可夫一般是马尔可夫性质的简称。它指的是一个随机变量序列按时间先后关系依次排开的时候,第N+1时刻的分布特性,与N时刻以前的随机变量的取值无关。拿天气来打个比方。如果我们假定天气是马尔可夫的,其意思就是我们假设今天的天气仅仅与昨天的天气存在概率上的关联,而与前天及前天以前的天气没有关系。其它如传染病和谣言的传播规律,就是马尔可夫的。
随机场包含两个要素:位置(site),相空间(phase space)。当给每一个位置中按照某种分布随机赋予相空间的一个值之后,其全体就叫做随机场。我们不妨拿种地来打个比方。“位置”好比是一亩亩农田;“相空间”好比是种的各种庄稼。我们可以给不同的地种上不同的庄稼,这就好比给随机场的每个“位置”,赋予相空间里不同的值。所以,俗气点说,随机场就是在哪块地里种什么庄稼的事情。
好了,明白了上面两点,就可以讲马尔可夫随机场了。还是拿种地打比方,如果任何一块地里种的庄稼的种类仅仅与它邻近的地里种的庄稼的种类有关,与其它地方的庄稼的种类无关,那么这些地里种的庄稼的集合,就是一个马尔可夫随机场。
在图割的图构造里面,其实就是:当前节点只与邻近的四邻域或八邻域节点相关,故可以只构建四邻域或八邻域图
图构造的数学模型
说到这里,先看看典型的能量函数模型:
E(L)=∑p∈PDp(Lp)+∑(p,q)∈NVp,q(Lp,Lq)
这里有L={Lp∣p∈P}
以上两项都叫做惩罚项,意味着突袭那个分割的每一次“割断”,都会带来惩罚,如何使得总惩罚最小,即可看作是最优的完成了图像分割的任务。
我们知道基于图割的图像分割大多都是交互式分割,什么叫做交互式分割?
就是用户提供一些先验知识,然后根据这些先验知识对原有的数学模型进行量化,得到一个可优化的数学表达式。例如,用户可以通过认定一张图像上的一个苹果是他所要的目标,则他在图像上圈定苹果,程序知道了用户圈定的点是属于前景点,则可以将所有类似苹果的像素点都归类为前景点,这就是交互式的一种方法。
在此也是,前面一项Dp(Lp)表示根据观测信息(用户提供)判断当前点是否归类为前景点,并且设定,如果归类错误,其付出的代价是多少。
也许由前面的信息就可以大致判断当前像素的归类了,那后面一项有什么意义呢?
后面一项表示相邻像素点间的约束信息,举个例子:如果当前像素属于前景点,那么它左边一个点或者右边一个点与当前点相似,那么它属于前景的概率是不是也很大?在前面一项不能准确判断的时候,这时候这个约束关系就作用明显了。
Tlink的构建
Tlink,在能量函数中一般称为数据项,即上式左半部分:Dp(Lp),在s-t图中为与源点,汇点相连的边的权值,T在这里表示Terminal,一般而言,源点表示的是前景,汇点表示的是背景。
如前面所说,Tlink的构建与所给信息相关,考虑到Maxflow/Mincut切断的是权值最小的点,假设用相似性作为Tlink的权值的话,则如果当前像素属于前景,切断的应该是与汇点s连接的Tlink,反之则切断与源点相连接的Tlink。
假设,将相似性归一化,则相似性可看作是属于某一类的概率值,如根据已有信息,得到某个归一化的相似性权值p,则可以说它属于前景的概率为p,这样属于背景的概率就是1-p了。
当然很多情况下,为了公平起见,还是会提供一些背景点,用类似前景Tlink的方法构建背景Tlink。
然而,这里就有个问题:在我有一堆点作为前景点的前提下,我如何算一个点与给定点的相似度?
事实上,这本身就是一个值得探讨的问题,我只是说说我见过的一些方法:
1)算距离平均值/得到中心点算距离;
2)算与最近/最远点的距离;
3)用已有点构建单高斯模型,用所构建的单高斯模型算相似性;
4)用已有点构建多高斯模型(GMM),用所构建的GMM来算相似性;
这些都是比较常用的方法,在所发表的文章中看,用的最多的是4,我想一来是效果好,而来是有更好的理论可以些(原来我这么揣测)
Nlink的构建
对比来说,Nlink的构建是比较简单的。这里N可以解释为Neighbor,在图的构造上即为相互邻接的像素点相连,Nlink表示“邻接”像素点之间的约束关系,即切断“邻接”像素点(换句话说,将邻接的像素点分为不同类)所需花费的惩罚,所以简单来说,就只需要弄清两个问题:
1)怎样算是“邻接”?
2)作为邻接的像素点,其权值如何设定?
一般来说,“邻接”都是采用四邻域或八领域,理由如前面所述,权值的设定,一般都采用高斯权值:
w_{ij}=\left{ exp(−β∥f(i)−f(j)2)如果(i,j)相邻 0其他 \right.
β是用来控制权值比重的,f(i),f(j)分别表示像素i与像素j的特征,这里的特征既可以指颜色特征,也可以指其它特征。
简略总结Tlink与Nlink的作用
Tlink作为数据项,尽可能的将像素归类为正确的类别,保证像素分类的正确性;
Nlink作为平滑项,尽可能的约束相邻像素不被切断,保持数据的平滑,在图像上,表现为边界平滑;
最终结果在以上两者的共同影响下得到!
参考资料:
http://blog.csdn.net/y990041769/article/details/21026445
在一个网络流中,能够从源点s到达汇点t的最大流量,等于,如果从网络中移除就能够导致网络流中断的边的集合的最小容量和
水流管道的最大流量(流动的水量)由最细的管子容量决定。
对于每条边(u,v),有一个*容量*c(u,v)
对于每条边(u,v),有一个*流量*f(u,v).
网络流的三个性质:
1、容量限制: f[u,v]<=c[u,v]
2、反对称性:f[u,v] = - f[v,u]
3、流量平衡: 对于不是源点也不是汇点的任意结点,流入该结点的流量和等于流出该结点的流量和。
只要满足这三个性质,就是一个合法的网络流.
最大流问题,就是求在满足网络流性质的情况下,源点 s 到汇点 t 的最大流量。
而数据项部分则表示对应顶点属于前景或者背景的惩罚项。
于Graph Cuts需要有2个终端节点”S”和”T”,分别表示初始的目标区域和背景区域,在计算机视觉的图像分割领域时,需要人工指定初始的s顶点和t顶点
**
图割
**Markov Random Field
马尔克夫随机场定义:它包含两层意思:一是什么是马尔可夫,二是什么是随机场。
马尔可夫一般是马尔可夫性质的简称。它指的是一个随机变量序列按时间先后关系依次排开的时候,第N+1时刻的分布特性,与N时刻以前的随机变量的取值无关。拿天气来打个比方。如果我们假定天气是马尔可夫的,其意思就是我们假设今天的天气仅仅与昨天的天气存在概率上的关联,而与前天及前天以前的天气没有关系。其它如传染病和谣言的传播规律,就是马尔可夫的。
随机场包含两个要素:位置(site),相空间(phase space)。当给每一个位置中按照某种分布随机赋予相空间的一个值之后,其全体就叫做随机场。我们不妨拿种地来打个比方。“位置”好比是一亩亩农田;“相空间”好比是种的各种庄稼。我们可以给不同的地种上不同的庄稼,这就好比给随机场的每个“位置”,赋予相空间里不同的值。所以,俗气点说,随机场就是在哪块地里种什么庄稼的事情。
好了,明白了上面两点,就可以讲马尔可夫随机场了。还是拿种地打比方,如果任何一块地里种的庄稼的种类仅仅与它邻近的地里种的庄稼的种类有关,与其它地方的庄稼的种类无关,那么这些地里种的庄稼的集合,就是一个马尔可夫随机场。
在图割的图构造里面,其实就是:当前节点只与邻近的四邻域或八邻域节点相关,故可以只构建四邻域或八邻域图
图构造的数学模型
说到这里,先看看典型的能量函数模型:
E(L)=∑p∈PDp(Lp)+∑(p,q)∈NVp,q(Lp,Lq)
这里有L={Lp∣p∈P}
以上两项都叫做惩罚项,意味着突袭那个分割的每一次“割断”,都会带来惩罚,如何使得总惩罚最小,即可看作是最优的完成了图像分割的任务。
我们知道基于图割的图像分割大多都是交互式分割,什么叫做交互式分割?
就是用户提供一些先验知识,然后根据这些先验知识对原有的数学模型进行量化,得到一个可优化的数学表达式。例如,用户可以通过认定一张图像上的一个苹果是他所要的目标,则他在图像上圈定苹果,程序知道了用户圈定的点是属于前景点,则可以将所有类似苹果的像素点都归类为前景点,这就是交互式的一种方法。
在此也是,前面一项Dp(Lp)表示根据观测信息(用户提供)判断当前点是否归类为前景点,并且设定,如果归类错误,其付出的代价是多少。
也许由前面的信息就可以大致判断当前像素的归类了,那后面一项有什么意义呢?
后面一项表示相邻像素点间的约束信息,举个例子:如果当前像素属于前景点,那么它左边一个点或者右边一个点与当前点相似,那么它属于前景的概率是不是也很大?在前面一项不能准确判断的时候,这时候这个约束关系就作用明显了。
Tlink的构建
Tlink,在能量函数中一般称为数据项,即上式左半部分:Dp(Lp),在s-t图中为与源点,汇点相连的边的权值,T在这里表示Terminal,一般而言,源点表示的是前景,汇点表示的是背景。
如前面所说,Tlink的构建与所给信息相关,考虑到Maxflow/Mincut切断的是权值最小的点,假设用相似性作为Tlink的权值的话,则如果当前像素属于前景,切断的应该是与汇点s连接的Tlink,反之则切断与源点相连接的Tlink。
假设,将相似性归一化,则相似性可看作是属于某一类的概率值,如根据已有信息,得到某个归一化的相似性权值p,则可以说它属于前景的概率为p,这样属于背景的概率就是1-p了。
当然很多情况下,为了公平起见,还是会提供一些背景点,用类似前景Tlink的方法构建背景Tlink。
然而,这里就有个问题:在我有一堆点作为前景点的前提下,我如何算一个点与给定点的相似度?
事实上,这本身就是一个值得探讨的问题,我只是说说我见过的一些方法:
1)算距离平均值/得到中心点算距离;
2)算与最近/最远点的距离;
3)用已有点构建单高斯模型,用所构建的单高斯模型算相似性;
4)用已有点构建多高斯模型(GMM),用所构建的GMM来算相似性;
这些都是比较常用的方法,在所发表的文章中看,用的最多的是4,我想一来是效果好,而来是有更好的理论可以些(原来我这么揣测)
Nlink的构建
对比来说,Nlink的构建是比较简单的。这里N可以解释为Neighbor,在图的构造上即为相互邻接的像素点相连,Nlink表示“邻接”像素点之间的约束关系,即切断“邻接”像素点(换句话说,将邻接的像素点分为不同类)所需花费的惩罚,所以简单来说,就只需要弄清两个问题:
1)怎样算是“邻接”?
2)作为邻接的像素点,其权值如何设定?
一般来说,“邻接”都是采用四邻域或八领域,理由如前面所述,权值的设定,一般都采用高斯权值:
w_{ij}=\left{ exp(−β∥f(i)−f(j)2)如果(i,j)相邻 0其他 \right.
β是用来控制权值比重的,f(i),f(j)分别表示像素i与像素j的特征,这里的特征既可以指颜色特征,也可以指其它特征。
简略总结Tlink与Nlink的作用
Tlink作为数据项,尽可能的将像素归类为正确的类别,保证像素分类的正确性;
Nlink作为平滑项,尽可能的约束相邻像素不被切断,保持数据的平滑,在图像上,表现为边界平滑;
最终结果在以上两者的共同影响下得到!
参考资料:
http://blog.csdn.net/y990041769/article/details/21026445

相关文章推荐
- 随机收缩算法
- [BZOJ1266][AHOI2006][最短路][最小割]上学路线
- uva 11248
- poj 2914
- 【网络流之最小割模型】poj3469 BZOJ3144 UVA1212
- uva1660 最大流
- hdu 3879 最小割模型
- bzoj1412[狼和羊的故事]最小割
- bzoj1001[狼爪兔子]最小割转最短路
- 浅谈最大流-最小割
- hihoCoder1252 2015北京区域赛 D.Kejin Game
- 网络流 最小割最大流定理
- 最小割算法
- BZOJ1497: [NOI2006]最大获利
- POJ 1815 Friendship
- bzoj-3144 切糕
- 【网络流】最大流:求最小割值、求(边)不交路径数量、求二分匹配最大匹配数
- POJ 3469 Dual Core CPU(最小割)
- HDU 5452 Minimum Cut (2015年沈阳赛区网络赛C题)
- SCU 4371 Interesting matrix