ZooKeeper集群搭建详细步骤
2016-08-05 00:28
543 查看
Apache ZooKeeper是一个非常出色的分布式协调系统,在配置管理、命名服务、分布式同步等方面应用广泛。其基本思想来源于Google的Chubby,可以认为是其开源实现。在Hadoop生态系统中,ZooKeeper发挥着非常作用的作用,kafka等很多系统都依赖于ZooKeeper提供服务。ZooKeeper通过选举产生一个Leader,其他节点作为Follower。Leader发生故障时会自动重新选举,具备很高的可用性。
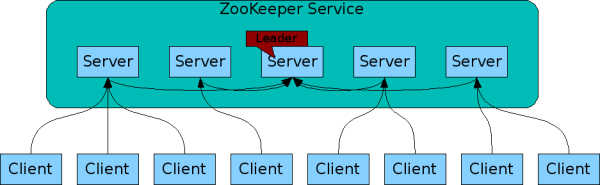
ZooKeeper集群组成如下,写操作都由Leader来完成,如果其他节点接受到写操作,会自动转发给Leader:
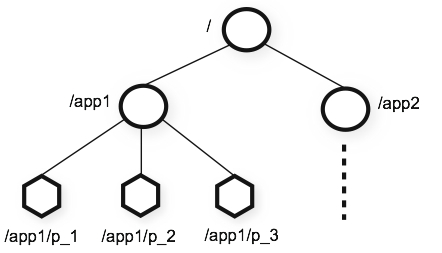
ZooKeeper的数据模型通过ZNode组成类似文件系统的目录结构;
本文描述一个3节点集群的搭建步骤,分别为master,slave1,slave2.
下面是一个基本的配置
tickTime是ZooKeeper很多地方用到的一个时间单位,其他时间配置很多以这个为单位来计算。这配置为2秒钟。
initLimit是ZooKeeper启动时,Follower节点从Leader节点同步数据允许的最长时间。
syncLimit时节点通信时请求响应的最长时间。
dataDir和dataLogDir分别配置存储ZooKeeper数据和事务日志的目录。
clientPort是ZooKeeper对外提供服务的端口,客户端通过该端口连接ZooKeeper。
节点组成部分配置的是集群中各个节点的信息,1,2,3分别表示各个节点的id,每个节点的数据目录下需要配置一个叫myid的文件,指定该ZooKeeper节点的id,下面会提到。右边分别是主机、集群通信端口(Follower联系Leader的时候连接到该端口),最后一个端口是选举Leader的时候使用的端口。
创建数据和日志目录:
配置id:
文件内容:
scp中的
同时需要在132和134创建相应的目录,然后myid文件分别为2,3. 具体做法参考前文。
使用bin目录中的脚本启动ZooKeeper,主要目录前面的./。
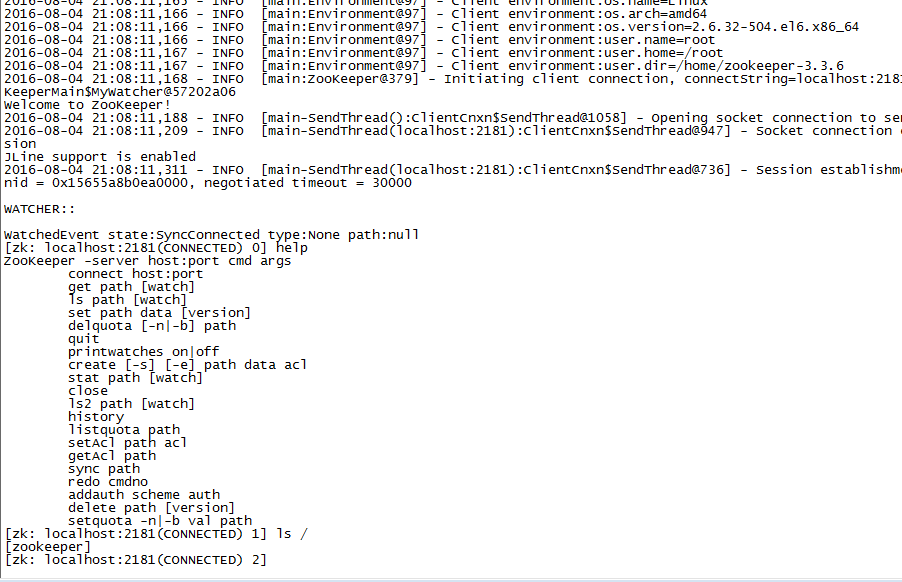
测试,使用zkCli.sh连接到ZooKeeper:
没有提供主机和端口,默认连接到本地的2181端口:
如果安装了HBase,在HBase管理界面可以看到使用了搭建的ZooKeeper集群:

(完)
ZooKeeper集群组成如下,写操作都由Leader来完成,如果其他节点接受到写操作,会自动转发给Leader:
ZooKeeper的数据模型通过ZNode组成类似文件系统的目录结构;
本文描述一个3节点集群的搭建步骤,分别为master,slave1,slave2.
1. 下载安装
在master节点上:#wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.3.6/zookeeper-3.3.6.tar.gz # tar zxvf zookeeper-3.3.6.tar.gz # mv zookeeper-3.3.6 /home/zookeeper-3.3.6
2. 配置ZooKeeper:
ZooKeeper的配置集中在conf/zoo.cfg文件中,基础的配置包括一些时间参数,数据目录,机器其他节点等。cd /home/zookeeper-3.3.6/conf cp zoo_sample.cfg zoo.cfg vim zoo.cfg
下面是一个基本的配置
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. dataDir=/home/data/zookeeper/data dataLogDir=/home/data/zookeeper/log # the port at which the clients will connect clientPort=2181 #集群节点组成 server.1=master:2888:3888 server.2=slave1:2888:3888 server.3=slave2:2888:3888
tickTime是ZooKeeper很多地方用到的一个时间单位,其他时间配置很多以这个为单位来计算。这配置为2秒钟。
initLimit是ZooKeeper启动时,Follower节点从Leader节点同步数据允许的最长时间。
syncLimit时节点通信时请求响应的最长时间。
dataDir和dataLogDir分别配置存储ZooKeeper数据和事务日志的目录。
clientPort是ZooKeeper对外提供服务的端口,客户端通过该端口连接ZooKeeper。
节点组成部分配置的是集群中各个节点的信息,1,2,3分别表示各个节点的id,每个节点的数据目录下需要配置一个叫myid的文件,指定该ZooKeeper节点的id,下面会提到。右边分别是主机、集群通信端口(Follower联系Leader的时候连接到该端口),最后一个端口是选举Leader的时候使用的端口。
创建数据和日志目录:
mkdir /home/data/zookeeper mkdir /home/data/zookeeper/data mkdir /home/data/zookeeper/log
配置id:
vim /home/data/zookeeper/data/myid
文件内容:
1
3. 复制到其他节点
将master的ZooKeeper复制到slave1和slave2:scp -rp /home/zookeeper-3.3.6/ root@slave1:/home scp -rp /home/zookeeper-3.3.6/ root@slave2:/home
scp中的
r参数表示复制的是个目录,
p保留权限等信息。
同时需要在132和134创建相应的目录,然后myid文件分别为2,3. 具体做法参考前文。
4. 启动,测试
在3台机器上分别启动ZooKeeper。使用bin目录中的脚本启动ZooKeeper,主要目录前面的./。
cd /home/zookeeper-3.3.6/bin/ ./zkServer start
测试,使用zkCli.sh连接到ZooKeeper:
./zkCli.sh
没有提供主机和端口,默认连接到本地的2181端口:
help命令可以获取帮助,
ls列出当前ZooKeeper中的节点列表。
如果安装了HBase,在HBase管理界面可以看到使用了搭建的ZooKeeper集群:
(完)

相关文章推荐
- Kafka(自带的zookeeper)集群搭建详细步骤
- Spark 集群搭建详细步骤
- Hadoop2.2.0 HA + Jdk1.8.0 + Zookeeper3.4.5 + Hbase0.98 集群搭建详细过程(服务器集群)
- Zookeeper3.4.6与Kafka0.8.1.1集群安装和配置详细步骤
- 超详细zookeeper集群搭建及解析说明
- hadoop2.6.4的HA集群搭建超详细步骤
- mesos+marathon+zookeeper的docker管理集群亲手搭建实例(详细)
- HBase的单节点集群详细启动步骤(分为Zookeeper自带还是外装)
- Redis主从架构和主从从架构集群搭建详细步骤
- Linux Centos7下ZooKeeper集群安装详细步骤
- 超详细zookeeper集群搭建及解析说明
- Hadoop集群环境搭建详细步骤
- spark 集群搭建 详细步骤
- Redis Cluster高可用(HA)集群环境搭建详细步骤
- Hadoop2.2.0 HA + Jdk1.8.0 + Zookeeper3.4.5 + Hbase0.98 集群搭建详细过程(服务器集群)
- Redis3.0集群环境的搭建详细步骤
- redis集群搭建详细步骤
- Zookeeper的多节点集群详细启动步骤(3或5节点)
- HBase0.99.2集群的搭建步骤(在hadoop2.6.4集群和zookeeper3.4.5集群上)
- Kafka的3节点集群详细启动步骤(Zookeeper是外装)