Spark RDD概念学习系列之RDD的创建(六)
2016-07-31 19:48
218 查看
RDD的创建
两种方式来创建RDD:
1)由一个已经存在的Scala集合创建
2)由外部存储系统的数据集创建,包括本地文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase、Amazon S3等。
RDD只能基于在稳定物理存储中的数据集和其他已有的RDD上执行确定性操作来创建。这些确定性操作称为转换,如map、filter、groupBy、join。
第1个RDD:代表了spark应用程序输入数据的来源,通过Transformation来对RDD进行各种算子的转换和实现算法。
初始RDD(或第1个RDD)创建的几个方式:(有300多种)
1、 使用程序中的集合创建RDD; 意义是:测试
2、 使用本地文件系统创建RDD; 意义是:测试大量数据的文件
3、 使用HDFS创建RDD; 意义是:生产环境里最常用
4、 基于DB创建RDD;
5、 基于NoSQL,例如HBase
6、 基于S3创建RDD;
7、 基于数据流创建RDD;
以上是典型的7种,我们这里重点讲解前3种方式。







SparkContext.scala里, SparkContext.createTaskScheduler,进入该方法



我们进一步,来学习







原来如此,所以是32。



以上是并行度,默认为1。
会利用最大,即32 = 8 X 4台worker
现在,我们来采取并行度为10,来玩玩。


问:实际上spark的并行度到底应该设置为多少呢?
答:最佳是,2-4 partitions for each CPU core。
如我们这里的CPU core是32个。每个worker给的是8个。共4台机器。
32 X 2 =64 32 X 4 = 128 即64~128之间。
说明的是,跟数据规模没关系,只跟每个task在计算partitions时的CPU使用时间和内存使用情况有关。
oom是内存溢出。


RDDBaseedOnLocalFile.scala
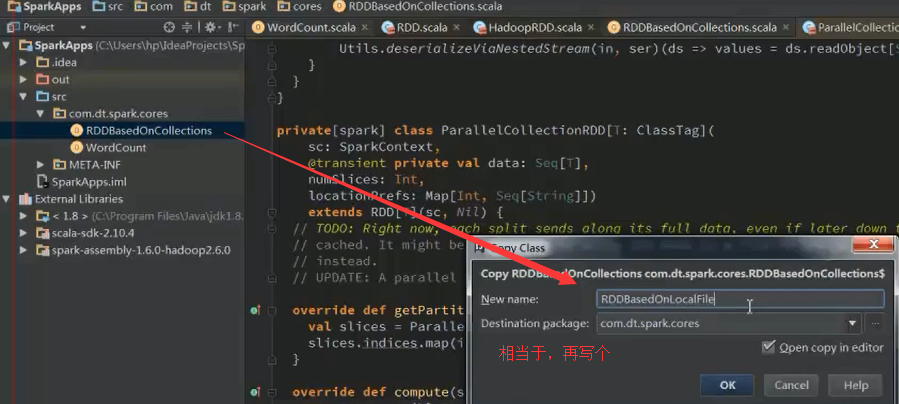

假如,计算每行的长度总和









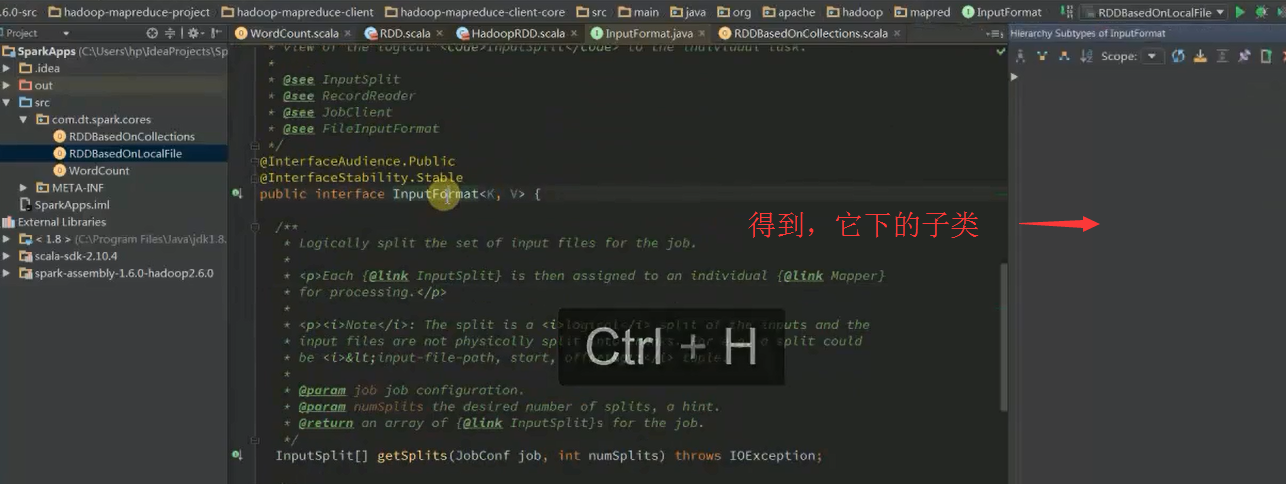


好的,关于此处的源码解读,自行去深究。不多赘述。
以上是在local模式下,下面开始
集群模式





欢迎大家,加入我的微信公众号:大数据躺过的坑 免费给分享
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
以及对应本平台的QQ群:161156071(大数据躺过的坑)


两种方式来创建RDD:
1)由一个已经存在的Scala集合创建
2)由外部存储系统的数据集创建,包括本地文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase、Amazon S3等。
RDD只能基于在稳定物理存储中的数据集和其他已有的RDD上执行确定性操作来创建。这些确定性操作称为转换,如map、filter、groupBy、join。
第1个RDD:代表了spark应用程序输入数据的来源,通过Transformation来对RDD进行各种算子的转换和实现算法。
初始RDD(或第1个RDD)创建的几个方式:(有300多种)
1、 使用程序中的集合创建RDD; 意义是:测试
2、 使用本地文件系统创建RDD; 意义是:测试大量数据的文件
3、 使用HDFS创建RDD; 意义是:生产环境里最常用
4、 基于DB创建RDD;
5、 基于NoSQL,例如HBase
6、 基于S3创建RDD;
7、 基于数据流创建RDD;
以上是典型的7种,我们这里重点讲解前3种方式。
SparkContext.scala里, SparkContext.createTaskScheduler,进入该方法
我们进一步,来学习
原来如此,所以是32。
以上是并行度,默认为1。
会利用最大,即32 = 8 X 4台worker
现在,我们来采取并行度为10,来玩玩。
问:实际上spark的并行度到底应该设置为多少呢?
答:最佳是,2-4 partitions for each CPU core。
如我们这里的CPU core是32个。每个worker给的是8个。共4台机器。
32 X 2 =64 32 X 4 = 128 即64~128之间。
说明的是,跟数据规模没关系,只跟每个task在计算partitions时的CPU使用时间和内存使用情况有关。
oom是内存溢出。
RDDBaseedOnLocalFile.scala
假如,计算每行的长度总和
好的,关于此处的源码解读,自行去深究。不多赘述。
以上是在local模式下,下面开始
集群模式
欢迎大家,加入我的微信公众号:大数据躺过的坑 免费给分享
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
以及对应本平台的QQ群:161156071(大数据躺过的坑)

相关文章推荐
- Spark RDD概念学习系列之如何创建Pair RDD
- Spark RDD概念学习系列之如何创建RDD
- Spark RDD概念学习系列之RDD的容错机制(十七)
- Spark RDD概念学习系列之RDD接口
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
- Spark RDD概念学习系列之RDD的缺点(二)
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
- Spark RDD概念学习系列之Spark的算子的分类(十一)
- Spark RDD概念学习系列之典型RDD的特征
- Spark RDD概念学习系列之Spark的算子的作用(十四)
- Spark RDD概念学习系列之RDD的5大特点
- Spark RDD概念学习系列之transformation操作
- Spark RDD概念学习系列之Spark的算子的分类
- Spark RDD概念学习系列之为什么会引入RDD?(一)
- Spark RDD概念学习系列之不同角度看RDD
- Spark RDD概念学习系列之RDD的本质特征
- Spark RDD概念学习系列之Spark Hash Shuffle内幕彻底解密(二十)
- Spark RDD概念学习系列之细谈RDD的弹性(十六)
- Spark RDD/Core概念学习系列
- Spark RDD概念学习系列之RDD的操作(七)