XML解析及相关问题
2016-07-30 14:27
204 查看
常见的XML解析方式主要有jdom,sax等,不过jdom貌似用的更多点。
在开发中,我们可能会碰到XML解析相关的问题,至于xml结构定义相关的错误就不提了,无非就是多了空格,差个收尾标签之类的低级错误,相信你仔细找找肯定能发现症结所在。这里,我们就谈谈XML无法解析特殊字符的解决方法。
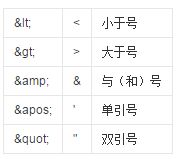
我们知道,XML解析器的解析原理肯定是利用一些特殊的标记符来分离XML文档中,基本的XML标签元素和标签内容的。完整的标签都是以<></>这种方式定义的,那么作为组成元素之一的'<'和'>',毫无疑问会被解析器特殊处理,说的书面一点,'<'和'>'就是XML中的预定义实体引用。XML中一共有五个类似的特殊实体引用:
那么如果我们想读取XML文件中这些特殊符号该怎么处理呢?比如'1<4',解析的时候肯定报语法错误了。
现在有两种解决方法:
1.用实体引用代替符号
2.使用CDATA处理特殊字符(CDATA 指的是不由 XML 解析器进行解析的文本数据)
值得注意的是,CDATA的文本内容中不能出现字符串“]]>”,且不可嵌套使用。
下面有个实例程序可供参考:
package jj.io;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.List;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.JDOMException;
import org.jdom.input.SAXBuilder;
public class TestPushBackInputStream {
public static void main(String[] args) {
testXML();
}
public static void testXML() {
try {
String path = "E:/xml01.xml";
SAXBuilder sb = new SAXBuilder();
InputStreamReader isr = new InputStreamReader(new FileInputStream(path),"gbk");
//Document doc1 = sb.build(new File(path));这种方式简单,但可能会碰到乱码问题
Document doc = sb.build(isr);
Element ele = doc.getRootElement();
List<Element> eL = ele.getChildren("p");
for (Element e : eL) {
System.out.println("#####");
System.out.println(e.getAttributeValue("name"));
System.out.println(e.getText());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (JDOMException e) {
e.printStackTrace();
}
}
}
相关的XML文件如下:
<?xml version="1.0" encoding="gbk"?>
<table>
<p name="姜哥哥">帅帅哒!</p>
<p name="特殊字符">><&"</p>
<p name="CDATA"><![CDATA[<,>]]></p>
</table>
解析出的效果如下:
#####
姜哥哥
帅帅哒!
#####
特殊字符
><&"
#####
CDATA
<,>
在开发中,我们可能会碰到XML解析相关的问题,至于xml结构定义相关的错误就不提了,无非就是多了空格,差个收尾标签之类的低级错误,相信你仔细找找肯定能发现症结所在。这里,我们就谈谈XML无法解析特殊字符的解决方法。
我们知道,XML解析器的解析原理肯定是利用一些特殊的标记符来分离XML文档中,基本的XML标签元素和标签内容的。完整的标签都是以<></>这种方式定义的,那么作为组成元素之一的'<'和'>',毫无疑问会被解析器特殊处理,说的书面一点,'<'和'>'就是XML中的预定义实体引用。XML中一共有五个类似的特殊实体引用:
那么如果我们想读取XML文件中这些特殊符号该怎么处理呢?比如'1<4',解析的时候肯定报语法错误了。
现在有两种解决方法:
1.用实体引用代替符号
2.使用CDATA处理特殊字符(CDATA 指的是不由 XML 解析器进行解析的文本数据)
值得注意的是,CDATA的文本内容中不能出现字符串“]]>”,且不可嵌套使用。
下面有个实例程序可供参考:
package jj.io;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.List;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.JDOMException;
import org.jdom.input.SAXBuilder;
public class TestPushBackInputStream {
public static void main(String[] args) {
testXML();
}
public static void testXML() {
try {
String path = "E:/xml01.xml";
SAXBuilder sb = new SAXBuilder();
InputStreamReader isr = new InputStreamReader(new FileInputStream(path),"gbk");
//Document doc1 = sb.build(new File(path));这种方式简单,但可能会碰到乱码问题
Document doc = sb.build(isr);
Element ele = doc.getRootElement();
List<Element> eL = ele.getChildren("p");
for (Element e : eL) {
System.out.println("#####");
System.out.println(e.getAttributeValue("name"));
System.out.println(e.getText());
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (JDOMException e) {
e.printStackTrace();
}
}
}
相关的XML文件如下:
<?xml version="1.0" encoding="gbk"?>
<table>
<p name="姜哥哥">帅帅哒!</p>
<p name="特殊字符">><&"</p>
<p name="CDATA"><![CDATA[<,>]]></p>
</table>
解析出的效果如下:
#####
姜哥哥
帅帅哒!
#####
特殊字符
><&"
#####
CDATA
<,>

相关文章推荐
- iOS开发使用XML解析网络数据
- Java解析xml的四种方法汇总
- Android中 xml 的解析
- QT中使用QXmlStreamReader解析XML文件
- 解析带有命名空间xmlns的xml文件 (XML解析中的namespace初探)
- php的simplexml
- xml解析
- 使用spring+maven时配置文件中的特殊字符处理
- Android XML 解析
- 解析XML—— Dom4j的SAX解析
- java SAX解析分析
- pull解析器解析xml
- Android学习笔记 day02 _ 测试 & 文件读写操作
- XML解析
- 只需要一步即可将xml数据转化成自定义类的对象模型
- 欢迎使用CSDN-markdown编辑器
- XML解析之SAX解析
- XML解析之Jdom解析
- XML解析之dom4j解析
- SAXReader saxReader = new SAXReader();来解析xml文件