Mean shift 算法
2016-07-30 11:26
267 查看
常见的聚类算法除了Kmeans,还有Meanshift及AP。这里先总结一下Meanshift相关知识。
对于每一个样本点,计算以它为中心的某个范围内所有样本点的均值,作为新的中心(这就是shift既中心的移动),移动直至收敛。这样每一轮迭代,中心都会向数据更密集的地方移动。
伪代码可以写成:
###如何完成中心的shift过程?###
可以对概率密度求梯度,梯度的方向就是概率密度增加最大的方向,从而也就是数据最密集的方向。
####预备知识####
- 核 Kernels :
核是满足如下条件的函数:
1.

2.

常见的核函数包括 :
1. Rectangular

2. Gaussian
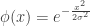
3. Epanechnikov

- 核密度估计 Kernels Density Estimation :
核密度估计是一种通过非参数估计来估计变量的密度函数的方法,通常也被称为是Parzen窗技术。给定核函数Kernel和带宽 bandwidth(记为h) , d维样本点的核参数估计如下:

- Mean shift的梯度下降计算
对概率密度求梯度 ,

令梯度为0,
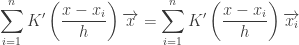
最后可得到中心的变化

记
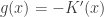
, 有


就是 mean shift. 所以mean shift过程可被总结为 : 对每一个样本点

1. 计算mean shift 向量

2. 移动概率估计窗
3. 重复上述过程直至收敛
以高斯核为例,
1.
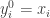
2.

K-means 需要给出聚类中心的个数并且聚类结果形状要比较平整成球状或者椭球状;而Mean shift作为一种非参数估计的方法不需要给出聚类中心个数,对聚类形状也没有要求 。.
K-means需要初始化聚类中心,而且不同初始化会带来不同的聚类效果;Mean shift 对初始化具有鲁棒性,因为它是对每一个样本点或者对特征空间中uniformly选择出的样本点执行的 ;此外 , K-means 对异常点敏感而Mean Shift 不敏感
K-means 速度比较快,时间复杂度为
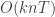
其中 k是聚类中心个数 , n 是样本点数, T 是迭代次数. 一般mean shift 在计算时间上开销很大,时间复杂度为
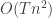
.
带宽参数的选择对Mean shift影响很大,带宽
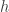
选的小时收敛速度慢;
选的大时虽然会加速收敛但是聚类效果不会很好. 对于
的选择有很多方法,scikit-learn中有关于mean shift的实现以及带宽选择的方法
Mean shift基本思想
Mean shift将特征空间视为先验概率密度函数,那么输入就被视为是一组满足某种概率分布的样本点,这样一来,特征空间中数据最密集的地方,对应于概率密度最大的地方,且概率密度的质心就可以被视为是概率密度函数的局部最优值,也就是要求的聚类中心。对于每一个样本点,计算以它为中心的某个范围内所有样本点的均值,作为新的中心(这就是shift既中心的移动),移动直至收敛。这样每一轮迭代,中心都会向数据更密集的地方移动。
伪代码可以写成:
重复移动直至收敛{ 对每一个数据点,固定一个窗口(数据范围): 计算窗口内数据的中心; 移动窗口至新的中心 }
###如何完成中心的shift过程?###
可以对概率密度求梯度,梯度的方向就是概率密度增加最大的方向,从而也就是数据最密集的方向。
####预备知识####
- 核 Kernels :
核是满足如下条件的函数:
1.
2.
常见的核函数包括 :
1. Rectangular
2. Gaussian
3. Epanechnikov
- 核密度估计 Kernels Density Estimation :
核密度估计是一种通过非参数估计来估计变量的密度函数的方法,通常也被称为是Parzen窗技术。给定核函数Kernel和带宽 bandwidth(记为h) , d维样本点的核参数估计如下:
- Mean shift的梯度下降计算
对概率密度求梯度 ,
令梯度为0,
最后可得到中心的变化
总结
以每一个样本点作为窗口的中心点,再寻得最终中心点,最终中心点相同的样本点就是同一类。记
, 有
就是 mean shift. 所以mean shift过程可被总结为 : 对每一个样本点
1. 计算mean shift 向量
2. 移动概率估计窗
3. 重复上述过程直至收敛
以高斯核为例,
1.
2.
Mean shift VS. K-Means
K-Means 是一种常见的聚类方法,简单有效。下面从参数个数来对比两种聚类方法。K-means 需要给出聚类中心的个数并且聚类结果形状要比较平整成球状或者椭球状;而Mean shift作为一种非参数估计的方法不需要给出聚类中心个数,对聚类形状也没有要求 。.
K-means需要初始化聚类中心,而且不同初始化会带来不同的聚类效果;Mean shift 对初始化具有鲁棒性,因为它是对每一个样本点或者对特征空间中uniformly选择出的样本点执行的 ;此外 , K-means 对异常点敏感而Mean Shift 不敏感
K-means 速度比较快,时间复杂度为
其中 k是聚类中心个数 , n 是样本点数, T 是迭代次数. 一般mean shift 在计算时间上开销很大,时间复杂度为
.
带宽参数的选择对Mean shift影响很大,带宽
选的小时收敛速度慢;
选的大时虽然会加速收敛但是聚类效果不会很好. 对于
的选择有很多方法,scikit-learn中有关于mean shift的实现以及带宽选择的方法

相关文章推荐
- 书评:《算法之美( Algorithms to Live By )》
- 动易2006序列号破解算法公布
- C#递归算法之分而治之策略
- Ruby实现的矩阵连乘算法
- C#插入法排序算法实例分析
- C#算法之大牛生小牛的问题高效解决方法
- C#算法函数:获取一个字符串中的最大长度的数字
- 超大数据量存储常用数据库分表分库算法总结
- C#数据结构与算法揭秘二
- C#冒泡法排序算法实例分析
- 算法练习之从String.indexOf的模拟实现开始
- C#算法之关于大牛生小牛的问题
- C#实现的算24点游戏算法实例分析
- 经典排序算法之冒泡排序(Bubble sort)代码
- c语言实现的带通配符匹配算法
- 浅析STL中的常用算法
- 算法之排列算法与组合算法详解
- C++实现一维向量旋转算法
- Ruby实现的合并排序算法
- C#折半插入排序算法实现方法