LDA整体流程
2016-07-29 16:48
316 查看
http://blog.csdn.net/u014313009/article/details/39825827
这篇文章讲贝叶斯公式的共轭分布非常容易理解,
http://wenku.baidu.com/link?url=AiymZjMA0FWi1DBgqSjpakTR6dDWpNVG01uaReI9DJVtR3Hhxn6RFbnvI6ckx-Iu01w0ZLyR5kL_XEwzroz4kelmRLsWqP88JdGtEOZ-CjS 对beta分布共厄的解释。
参考了文章
http://www.52nlp.cn/lda-math-lda-%E6%96%87%E6%9C%AC%E5%BB%BA%E6%A8%A1 ,写得非常好,但理解还是很难。
下面这篇文章讲了LDA的源代码分析,主要写采样了流程。
http://blog.csdn.net/pirage/article/details/50239209
LDA的训练主要是从训练语料中得出主题-词的统计情况,其认为每个主题与一些词强关联,且与每个词的关联情况不一;也可以把主题看做为词上的概率分布,即主题在不同的词上有不同的概率(关联强度),且每个不同主题的主题-词分布不一样。Gibbs Sampling是在训练过程中根据词选每个主题的概率且根据一定的方法为这个词选择一个主题。
其认为每一篇文章是按照如下的方法生成的:

LDA学习过程
先随机的给训练语料中的每个词赋一个topic,得出θd和φt赋值(θ是一个二维数组,第一维表示文章id,第二维表示topic id,各元素值代表文档取相应主题的概率;φ也是一个二维数组,第一维为topic id,第二维为词ID),然后如下迭代:
1)对于训练语料的每个单词,用Gibbs Sampling采用的方法,为其选择一个主题。选择的方法如下:
Gibbs Sampling方法中计算词i取主题k的概率如下:
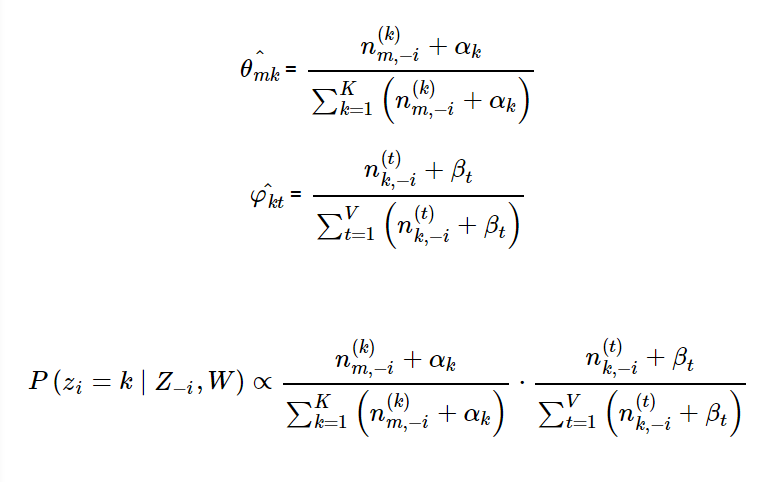
上面三个公式中:
第一公式表示第m篇文章中每个主题k的概率;
第二个公式表示第k个主题对应选每个词的概率。
第三个式子计算第i个词分类为各主题k的概率统计(没有包含第i个词)
n(k)m,−i 代表第m篇文档中除去第i位置的词外,分类为k的词的总数。
n(t)k,−i 代表所有文档除去第i位置的词外,词t分类为主题k的数量
K代表主题的数量,V代表词汇表里词的总量;-i代表计算时不考虑第i个位置
采样的代码可以参考 http://blog.csdn.net/pirage/article/details/50239209一文中的sample方法。
nw[w][k]表示训练语料中词w分类为主题k的个数; nwsum[k]表示训练训练语料中分类为主题K的词的总数;nd[m][k]表示文档m中分类为k的词的个数;ndsum[m]文档m中词的个数。注意上面的统计量都是没有包括当前被采样主题的词。
2)按照第一步为语料库中每个文档的每个词选择一个主题知道全部选择了主题称之为一个epoch;然后开始下一轮的主题选择,全部迭代次数完成后统计θd和ϕt,这就是模型最终的结果
LDA推断:
推断和训练的方法是一样的,只是在之前的训练中已经得到了主题-词的统计结果ϕt,所以在inference的过程中认为他不变。
这里的nw和nwsum是之前训练得到的数组,在推断的时候是保持不变的。nw[w][k]表示训练语料中词w分类为主题k的个数; nwsum[k]表示训练训练语料中分类为主题K的词的总数

这篇文章讲贝叶斯公式的共轭分布非常容易理解,
http://wenku.baidu.com/link?url=AiymZjMA0FWi1DBgqSjpakTR6dDWpNVG01uaReI9DJVtR3Hhxn6RFbnvI6ckx-Iu01w0ZLyR5kL_XEwzroz4kelmRLsWqP88JdGtEOZ-CjS 对beta分布共厄的解释。
参考了文章
http://www.52nlp.cn/lda-math-lda-%E6%96%87%E6%9C%AC%E5%BB%BA%E6%A8%A1 ,写得非常好,但理解还是很难。
下面这篇文章讲了LDA的源代码分析,主要写采样了流程。
http://blog.csdn.net/pirage/article/details/50239209
LDA的训练主要是从训练语料中得出主题-词的统计情况,其认为每个主题与一些词强关联,且与每个词的关联情况不一;也可以把主题看做为词上的概率分布,即主题在不同的词上有不同的概率(关联强度),且每个不同主题的主题-词分布不一样。Gibbs Sampling是在训练过程中根据词选每个主题的概率且根据一定的方法为这个词选择一个主题。
其认为每一篇文章是按照如下的方法生成的:
LDA学习过程
先随机的给训练语料中的每个词赋一个topic,得出θd和φt赋值(θ是一个二维数组,第一维表示文章id,第二维表示topic id,各元素值代表文档取相应主题的概率;φ也是一个二维数组,第一维为topic id,第二维为词ID),然后如下迭代:
1)对于训练语料的每个单词,用Gibbs Sampling采用的方法,为其选择一个主题。选择的方法如下:
Gibbs Sampling方法中计算词i取主题k的概率如下:
上面三个公式中:
第一公式表示第m篇文章中每个主题k的概率;
第二个公式表示第k个主题对应选每个词的概率。
第三个式子计算第i个词分类为各主题k的概率统计(没有包含第i个词)
n(k)m,−i 代表第m篇文档中除去第i位置的词外,分类为k的词的总数。
n(t)k,−i 代表所有文档除去第i位置的词外,词t分类为主题k的数量
K代表主题的数量,V代表词汇表里词的总量;-i代表计算时不考虑第i个位置
采样的代码可以参考 http://blog.csdn.net/pirage/article/details/50239209一文中的sample方法。
for (int k = 0; k < K; k++) {
p[k] = (nw[w][k] + beta) / (nwsum[k] + Vbeta) *
(nd[m][k] + alpha) / (ndsum[m] + Kalpha);
}
for k in xrange(1,self.K):
self.p[k] += self.p[k-1]
u = random.uniform(0,self.p[self.K-1])
for topic in xrange(self.K):
if self.p[topic]>u:
break
#注意这里加上1,在采样结束后,各统计量必须加上当前词。
self.nw[word][topic] +=1nw[w][k]表示训练语料中词w分类为主题k的个数; nwsum[k]表示训练训练语料中分类为主题K的词的总数;nd[m][k]表示文档m中分类为k的词的个数;ndsum[m]文档m中词的个数。注意上面的统计量都是没有包括当前被采样主题的词。
2)按照第一步为语料库中每个文档的每个词选择一个主题知道全部选择了主题称之为一个epoch;然后开始下一轮的主题选择,全部迭代次数完成后统计θd和ϕt,这就是模型最终的结果
LDA推断:
推断和训练的方法是一样的,只是在之前的训练中已经得到了主题-词的统计结果ϕt,所以在inference的过程中认为他不变。
for (int k = 0; k < K; k++) {
p[k] = (nw[w][k] + newnw[_w][k] + beta)/(nwsum[k] + newnwsum[k] + Vbeta) * (newnd[m][k] + alpha)/(newndsum[m] + Kalpha);
}这里的nw和nwsum是之前训练得到的数组,在推断的时候是保持不变的。nw[w][k]表示训练语料中词w分类为主题k的个数; nwsum[k]表示训练训练语料中分类为主题K的词的总数

相关文章推荐
- JbibbLDA使用。
- 我对LDA的一点理解
- 我对主题模型的理解
- LDA模型解析(变分推断)
- LDA摘要
- 机器学习-线性判别分析(LDA), 主成分分析(PCA)
- Gibbs sampling -- batch LDA
- [机器学习] LDA理论
- LDA(文档主题生成模型)--零基础(一)
- LDA in spark测试备忘
- 一个LDA(Latent Dirichlet Allocation)主题模型的Java实现
- 机器学习中特征选择和特征提取区别
- 几种分类方法简述
- 使用LDA线性判别分析进行多类的训练分类
- LDA算法入门
- 在Python里安装Jieba中文分词组件
- LDA文档主题生成模型
- 线性鉴别分析(LDA)之二分类问题
- 用 LDA 做主题模型:当 MLlib 邂逅 GraphX
- 线性判别分析(LDA), 主成分分析(PCA)