Hadoop:NameNode和Secondary NameNode
2016-07-28 10:21
393 查看
Hadoop培训教程:NameNode和Secondary NameNode,NameNode将对文件系统的改动追加保存到本地文件系统上的一个日志文件edits。当一个NameNode启动时,它首先从一个映像文件(fsimage)中读取HDFS的状态,接着执行日志文件中的编辑操作。然后将新的HDFS状态写入fsimage中,并使用一个空的edits文件开始正常操作。因为NameNode只有在启动阶段才合并fsimage和edits,久而久之日志文件可能会变得非常庞大,特别是对于大型的集群。日志文件太大的另一个副作用是下一次NameNode启动会花很长时间,NameNode和Secondary
NameNode之间的通信示意图如图3-2所示。
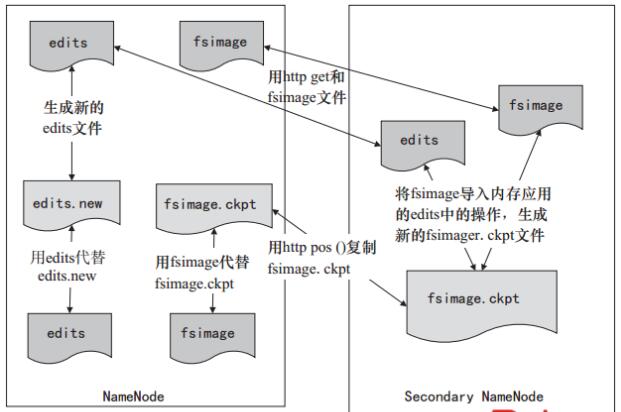
如图3-2所示,NameNode和Secondary NameNode间数据的通信使用的是HTTP协议,Secondary NameNode定期合并fsimage和edits日志,将edits日志文件大小控制在一个限度下。因为内存需求和NameNode在一个数量级上,所以通常Secondary NameNode和NameNode运行在不同的机器上。Secondary NameNode通过bin/start-dfs.sh在conf/masters中指定的节点上启动。
Secondary NameNode的检查点进程启动,是由以下两个配置参数控制的:
fs.checkpoint.period指定连续两次检查点的最大时间间隔,默认值是1小时。
fs.checkpoint.size定义了日志文件的最大值,一旦超过这个值会导致强制执行检查点(即使没到检查点的最大时间间隔),默认值是64MB。
Secondary NameNode保存最新检查点的目录与NameNode的目录结构相同。所以NameNode可以在需要的时候读取Secondary NameNode上的检查点镜像。
如果NameNode上除了最新的检查点以外,所有的其他历史镜像和edits文件都丢失了,NameNode可以引入这个最新的检查点。以下操作可以实现这个功能:
1)在配置参数dfs.name.dir指定的位置建立一个空文件夹。
2)把检查点目录的位置赋值给配置参数fs.checkpoint.dir。
3)启动NameNode,加上-importCheckpoint。
NameNode会从fs.checkpoint.dir目录读取检查点,并把它保存在dfs.name.dir目录下。如果dfs.name.dir目录下有合法的镜像文件,NameNode会启动失败。NameNode会检查fs.checkpoint.dir目录下镜像文件的一致性,但是不会去改动它。来源:CUUG官网
NameNode之间的通信示意图如图3-2所示。
如图3-2所示,NameNode和Secondary NameNode间数据的通信使用的是HTTP协议,Secondary NameNode定期合并fsimage和edits日志,将edits日志文件大小控制在一个限度下。因为内存需求和NameNode在一个数量级上,所以通常Secondary NameNode和NameNode运行在不同的机器上。Secondary NameNode通过bin/start-dfs.sh在conf/masters中指定的节点上启动。
Secondary NameNode的检查点进程启动,是由以下两个配置参数控制的:
fs.checkpoint.period指定连续两次检查点的最大时间间隔,默认值是1小时。
fs.checkpoint.size定义了日志文件的最大值,一旦超过这个值会导致强制执行检查点(即使没到检查点的最大时间间隔),默认值是64MB。
Secondary NameNode保存最新检查点的目录与NameNode的目录结构相同。所以NameNode可以在需要的时候读取Secondary NameNode上的检查点镜像。
如果NameNode上除了最新的检查点以外,所有的其他历史镜像和edits文件都丢失了,NameNode可以引入这个最新的检查点。以下操作可以实现这个功能:
1)在配置参数dfs.name.dir指定的位置建立一个空文件夹。
2)把检查点目录的位置赋值给配置参数fs.checkpoint.dir。
3)启动NameNode,加上-importCheckpoint。
NameNode会从fs.checkpoint.dir目录读取检查点,并把它保存在dfs.name.dir目录下。如果dfs.name.dir目录下有合法的镜像文件,NameNode会启动失败。NameNode会检查fs.checkpoint.dir目录下镜像文件的一致性,但是不会去改动它。来源:CUUG官网

相关文章推荐
- LC117 Populating Next Right Pointers in Each Node II
- [leetcode] 19. Remove Nth Node From End of List
- 程序员使用Node的十个技巧
- hadoop namenode及yarn resourcemanager HA配置
- LeetCode进阶之路(Reverse Nodes in k-Group)
- Node.js GET/POST请求
- Node.js 文件操作
- Node.js安装及常用命令(Mac OS )
- JS, Node.js, npm简介
- Populating Next Right Pointers in Each Node
- node anyproxy ssi简易支持
- 《nodejs实战》一
- Nodejs 学习笔记
- 24. Swap Nodes in Pairs
- Node.js 全局对象
- 使用NodeJS调用Dubbo工程
- node.js中文资料导航
- Nodejs——搭建电影展台(grunt)配置
- Node.js exports 和 require 两个对象
- nodejs的后端字符串验证器-validator