Hadoop
2016-07-27 21:10
260 查看
Hadoop
环境:rhel6.5 selinux and iptables disabled, sshd enabled主机: 172.25.35.1 master
172.25.35.2 slave
172.25.35.3 slave
172.25.35.4 slave
Hadoop 主从节点分解,如图:
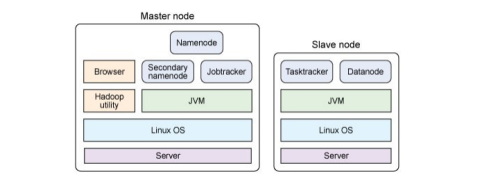
主节点包括名称节点、从属名称节点和 jobtracker 守护进程(即所谓的主守护进程)以及管理集群所用的实用程序和浏览器。从节点包括 tasktracker 和数据节点(从属守护进程)。两种设置的不同之处在于,主节点包括提供 Hadoop 集群管理和协调的守护进程,而从节点包括实现Hadoop 文件系统(HDFS)存储功能和 MapReduce 功能(数据处理功能)的守护进程。每个守护进程在 Hadoop 框架中的作用。namenode 是 Hadoop 中的主服务器,它管理文件系统名称空间和对集群中存储的文件的访问。还有一个 secondary namenode,它不是namenode 的冗余守护进程,而是提供周期检查点和清理任务。在每个 Hadoop 集群中可以找到一个 namenode 和一个 secondary namenode。datanode 管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个 datanode 守护进程。
每个集群有一个jobtracker,它负责调度 datanode上的工作。每个datanode有一个tasktracker,它们执行实际工作。jobtracker和tasktracker采用主-从形式,jobtracker跨datanode 分发工作,而 tasktracker执行任务。jobtracker还检查请求的工作,如果一个datanode由于某种原因失败,jobtracker会重新调度以前的任务。
1.安装并配置Hadoop
useradd -u 900 hadoop
sh jdk-6u32-linux-x64.bin
mv jdk1.6.0_32/ /home/hadoop/java
mv hadoop-1.2.1.tar.gz /home/hadoop/
echo westos | passwd --stdin hadoop
su - hadoop ##切换到普通用户hadoop
tar zxf hadoop-1.2.1.tar.gz
ln -s hadoop-1.2.1 hadoop
vim .bash_profile
# User specific environment and startup programs
export JAVA_HOME=/home/hadoop/java
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
source .bash_profile ##生效
执行java,javac无报错说明成功
cd /hadoop/conf/
vim hadoop-env.sh
export JAVA_HOME=/home/hadoop/java ##指定JAVA_HOME
vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://172.25.35.1:9000</value> ##指定namenode
</property>
</configuration>
vim mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>172.25.35.1:9001</value> ##指定jobtracker
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value> ##指定文件保存的副本数
</property>
</configuration>
mkdir input
cp conf/*.xml input/ ##把conf里所有xml结尾的文件放到input下用作检测
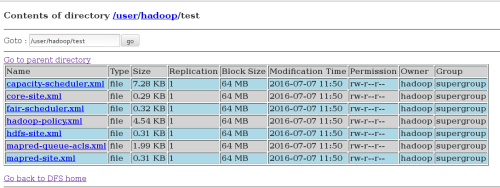
bin/hadoop jar hadoop-examples-1.2.1.jar grep input output 'dfs[a-z.]+' ##运行发行版提供的示例程序
如图:
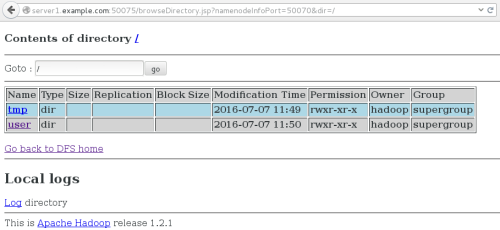
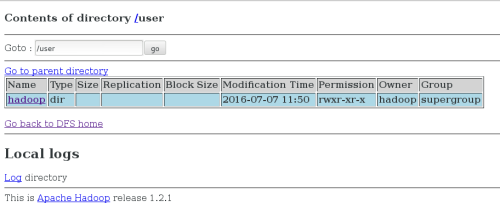
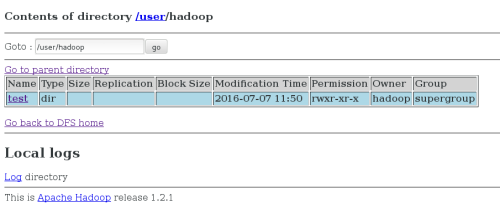
2.伪分布式文件管理系统
su - hadoop ##切换到普通用户
ssh-keygen ##
ssh-copy-id localhost ##保证master到所有的slave节点都能实现无密码登陆
测试:
[hadoop@server1 ~]$ ssh server1.example.com
The authenticity of host 'server1.example.com (172.25.35.1)' can't be established.
RSA key fingerprint is 3a:ca:c6:3b:e4:06:cf:04:31:97:6f:2d:0d:b0:df:7e.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'server1.example.com,172.25.35.1' (RSA) to the list of known hosts.
Last login: Wed Jul 6 10:31:46 2016 from localhost
cd hadoop/
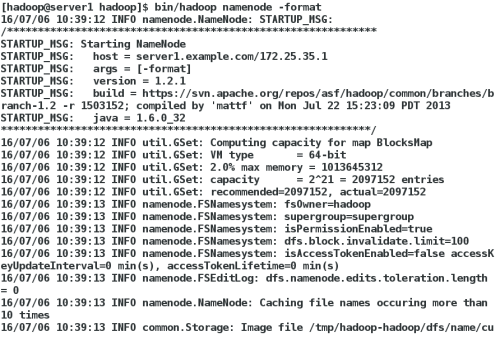
bin/hadoop namenode -format ##格式化新的分布式文件系统
如图:
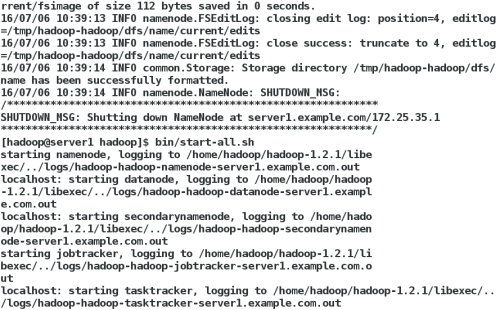
bin/start-dfs.sh ##开启Namenode
bin/start-mapred.sh ##开启Jobtracker
bin/hadoop fs -put input test ##将输入文件拷贝到分布式文件系统
[hadoop@server1 hadoop]$ jps
4885 JobTracker
5271 Jps
4611 DataNode
4731 SecondaryNameNode
4498 NameNode
4997 TaskTracker
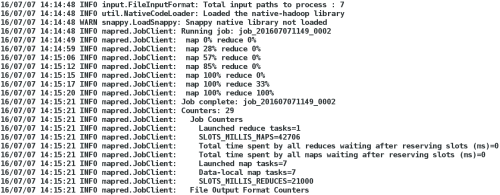
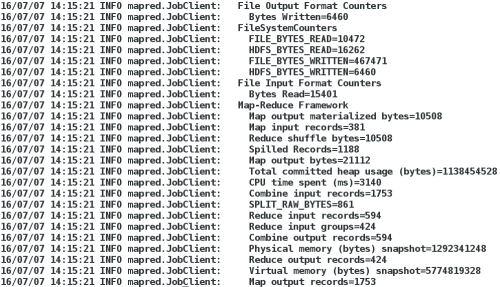
bin/hadoop jar hadoop-examples-1.2.1.jar wordcount test output ##统计test字数并输出
到output
如图:

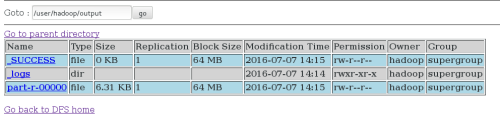
bin/hadoop fs -get output test ##将输出文件从分布式文件系统拷贝到本地文件系统查看
如图:

[hadoop@server1 hadoop]$ cat output/*
1dfsadmin
bin/hadoop fs -cat output/* ##查看输出文件
bin/stop-all.sh ##完成所有操作后关掉守护进程
3.hadoop在线添加,删除节点
在server端,client端分别:
yum install -y nfs-utils
/etc/init.d/rpcbind start
/etc/init.d/nfs start
并在client端分别创建相同的hadoop用户,uid等要保持一致
vim /etc/exports
/home/hadoop *(rw,all_squash,anonuid=900,anongid=900)
在client端:
[root@server2 ~]# mount 172.25.35.1:/home/hadoop/ /home/hadoop/
如图:

通过在server端设置ssh,实现了slave端的无密码登陆:
[hadoop@server1 ~]$ ssh 172.25.35.2
Last login: Wed Jul 6 16:43:18 2016 from server1.example.com
[hadoop@server2 ~]$ exit
logout
Connection to 172.25.35.2 closed.
[hadoop@server1 ~]$ ssh 172.25.35.3
Last login: Wed Jul 6 16:38:00 2016 from server1.example.com
[hadoop@server3 ~]$ exit
logout
Connection to 172.25.35.3 closed.
cd /hadoop/conf/
vim masters
172.25.35.1
vim slaves
172.25.35.2
172.25.35.3
cd hadoop/
bin/hadoop namenode -format ##重新格式化
bin/start-mapred.sh ##开启Jobtracker
bin/start-dfs.sh ##开启Namenode
bin/hadoop fs -put input test
bin/hadoop jar hadoop-examples-1.2.1.jar grep test output 'dfs[a-z.]+'
如图:
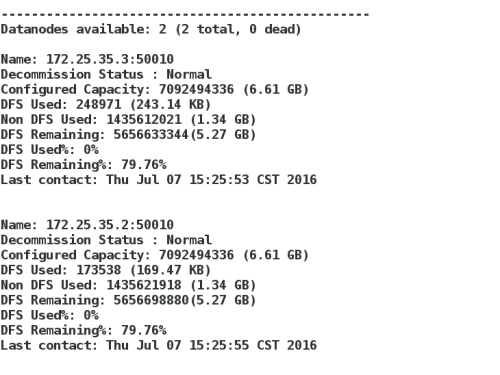
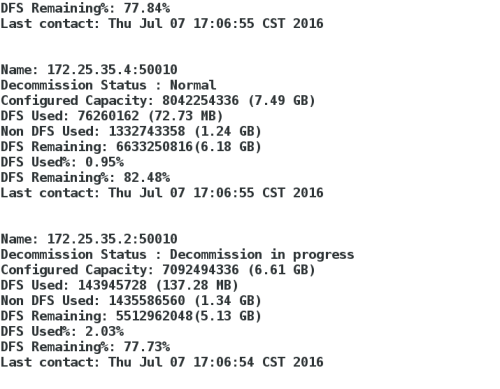
bin/hadoop dfsadmin -report
如图:
dd if=/dev/zero of=gaofang bs=1M count=200
bin/hadoop fs -put gaofang test ##把截取的文件上传到test
如图:
新开一台虚拟机作为新节点用作在线添加
在client的server4上:
yum install -y nfs-utils
/etc/init.d/rpcbind start
/etc/init.d/nfs start
[root@server4 ~]# mount 172.25.35.1:/home/hadoop/ /home/hadoop/
[hadoop@server4 ~]$ df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 7853764 902164 6552652 13% /
tmpfs 510200 0 510200 0% /dev/shm
/dev/vda1 495844 33477 436767 8% /boot
172.25.35.1:/home/hadoop/ 6926336 2913408 3661056 45% /home/hadoop
bin/hadoop-daemon.sh start datanode
bin/hadoop-daemon.sh start tasktracker
bin/hadoop dfsadmin -report ##查看
如图:

在server端:
vim /hadoop/conf/slaves
172.25.35.2
172.25.35.3
172.25.35.4
vim mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>172.25.35.1:9001</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/home/hadoop/hadoop/conf/datanode-excludes</value>
</property>
</configuration>
vim /home/hadoop/hadoop/conf/datanode-excludes
172.25.35.2 ##加上打算删掉的主机
bin/hadoop dfsadmin -refreshNodes ##刷新节点
bin/hadoop dfsadmin -report ##查看
如图:
本文出自 “jeffrey13” 博客,请务必保留此出处http://jeffrey13.blog.51cto.com/8875406/1830872

相关文章推荐
- shell 关于&
- poj3258River Hopscotch(二分)
- Centos7 安装 matplotlib问题
- DC/OS专题之安装部署篇
- Centos下使用packstack安装openstack allinone版本
- linux、SecureCRT安装JDK
- Linux目录结构及文件基本操作
- 新手学Linux获取帮助的几个途径
- 中文输入引发的异常
- Linux Kernel 4.7版本发布
- Opencv中视频播放与进度控制
- Linux第二弹
- Java Web访问Linux的Mysql
- nginx 菜鸟入门一
- POJ-3258 River Hopscotch
- River Hopscotch<poj3528>
- linux后台运行任务——screen
- 查看Apache并发请求数及其TCP连接状态
- linux find命令
- apache2.2后修改最大并发连接数