Java Charset
2016-07-27 15:18
691 查看
package com.demo.test;
import java.nio.charset.Charset;
import java.util.Arrays;
/**
(1)在中国,字符串转化默认使用GBK编码
(2)转化表
英文(L) 中文(L) 混合(英文L1 + 中文L2)
DEFAULT(GBK) L 2*L L1 + 2*L2
ISO8859-1 L L L1 + L2
ASCII L L L1 + L2
GBK L 2*L L1 + 2*L2
UTF-8 L 3*L L1 + 3*L2
UNICODE 2*L+2 2*L+2 2*(L1 + L2)+2
*/
public class CharsetDemo {
public static void main(String[] args) {
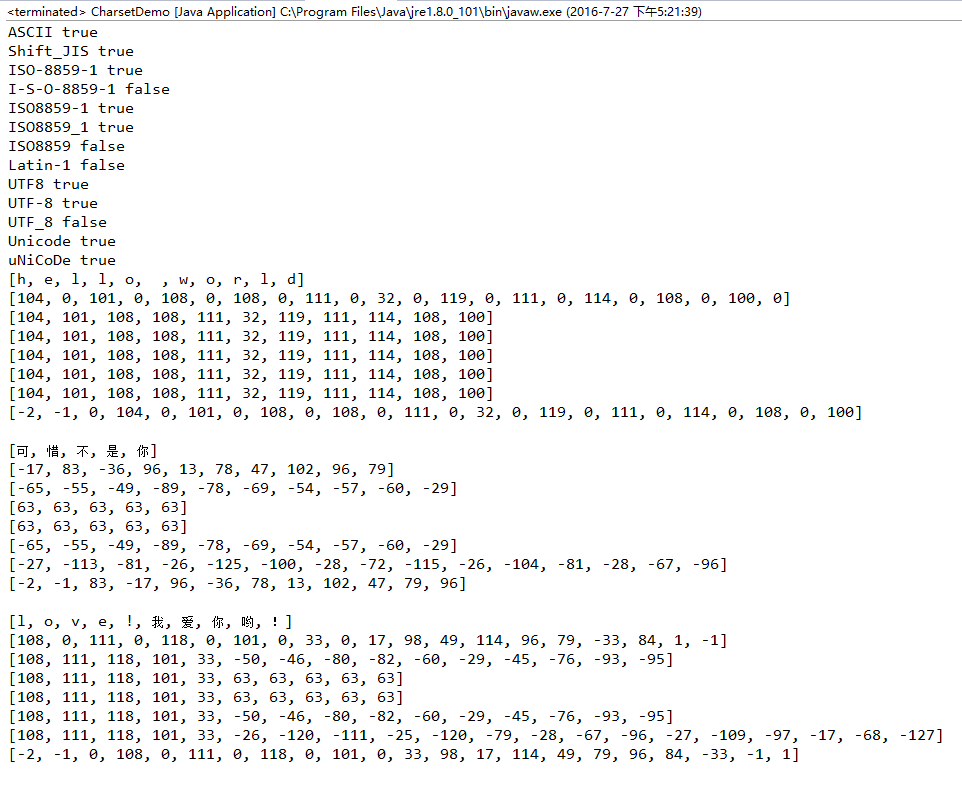
System.out.println("ASCII " + Charset.isSupported("ASCII"));//true
System.out.println("Shift_JIS " + Charset.isSupported("Shift_JIS"));//true
System.out.println("ISO-8859-1 " + Charset.isSupported("ISO-8859-1"));//true
System.out.println("I-S-O-8859-1 " + Charset.isSupported("I-S-O-8859-1"));//false
System.out.println("ISO8859-1 " + Charset.isSupported("ISO8859-1"));//true
System.out.println("ISO8859_1 " + Charset.isSupported("ISO8859_1"));//true
//error: java.nio.charset.IllegalCharsetNameException
// System.out.println("ISO8859 1 " + Charset.isSupported("ISO8859 1"));
//ISO8859必须有第一版的标识否则不合法
System.out.println("ISO8859 " + Charset.isSupported("ISO8859"));//false
//ISO/IEC8859-1,又称Latin-1或“ 西欧语言”,但这里用Latin-1却是不合法的
System.out.println("Latin-1 " + Charset.isSupported("Latin-1"));//false
System.out.println("UTF8 " + Charset.isSupported("UTF8"));//true
System.out.println("UTF-8 " + Charset.isSupported("UTF-8"));//true
System.out.println("UTF_8 " + Charset.isSupported("UTF_8"));//false
//CharsetName跟大小写无关
System.out.println("Unicode " + Charset.isSupported("Unicode"));//true
System.out.println("uNiCoDe " + Charset.isSupported("uNiCoDe"));//true
String str1 = "hello world";//11位
System.out.println(Arrays.toString(str1.toCharArray()));
System.out.println(Arrays.toString(toCharBytes(str1)));
System.out.println(Arrays.toString(str1.getBytes()));//11位,[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
System.out.println(Arrays.toString(str1.getBytes(Charset.forName("ISO8859-1"))));//11位,[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
System.out.println(Arrays.toString(str1.getBytes(Charset.forName("ASCII"))));//11位,[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
System.out.println(Arrays.toString(str1.getBytes(Charset.forName("GBK"))));//11位,[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
System.out.println(Arrays.toString(str1.getBytes(Charset.forName("UTF-8"))));//11位,[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
System.out.println(Arrays.toString(str1.getBytes(Charset.forName("Unicode"))));//24位,[-2, -1, 0, 104, 0, 101, 0, 108, 0, 108, 0, 111, 0, 32, 0, 119, 0, 111, 0, 114, 0, 108, 0, 100]
System.out.println();
String str2 = "可惜不是你";//5位
System.out.println(Arrays.toString(str2.toCharArray()));
System.out.println(Arrays.toString(toCharBytes(str2)));
System.out.println(Arrays.toString(str2.getBytes()));//10位,[-65, -55, -49, -89, -78, -69, -54, -57, -60, -29]
System.out.println(Arrays.toString(str2.getBytes(Charset.forName("ISO8859-1"))));//5位,[63, 63, 63, 63, 63]
System.out.println(Arrays.toString(str2.getBytes(Charset.forName("ASCII"))));//5位,[63, 63, 63, 63, 63]
System.out.println(Arrays.toString(str2.getBytes(Charset.forName("GBK"))));//10位,[-65, -55, -49, -89, -78, -69, -54, -57, -60, -29]
System.out.println(Arrays.toString(str2.getBytes(Charset.forName("UTF-8"))));//15位,[-27, -113, -81, -26, -125, -100, -28, -72, -115, -26, -104, -81, -28, -67, -96]
System.out.println(Arrays.toString(str2.getBytes(Charset.forName("Unicode"))));//12位,[-2, -1, 83, -17, 96, -36, 78, 13, 102, 47, 79, 96]
System.out.println();
String str3 = "love!我爱你哟!";//5+5位
System.out.println(Arrays.toString(str3.toCharArray()));
System.out.println(Arrays.toString(toCharBytes(str3)));
System.out.println(Arrays.toString(str3.getBytes()));//15位,[108, 111, 118, 101, 33, -50, -46, -80, -82, -60, -29, -45, -76, -93, -95]
System.out.println(Arrays.toString(str3.getBytes(Charset.forName("ISO8859-1"))));//10位,[108, 111, 118, 101, 33, 63, 63, 63, 63, 63]
System.out.println(Arrays.toString(str3.getBytes(Charset.forName("ASCII"))));//10位,[108, 111, 118, 101, 33, 63, 63, 63, 63, 63]
System.out.println(Arrays.toString(str3.getBytes(Charset.forName("GBK"))));//15位,[108, 111, 118, 101, 33, -50, -46, -80, -82, -60, -29, -45, -76, -93, -95]
System.out.println(Arrays.toString(str3.getBytes(Charset.forName("UTF-8"))));//20位,[108, 111, 118, 101, 33, -26, -120, -111, -25, -120, -79, -28, -67, -96, -27, -109, -97, -17, -68, -127]
System.out.println(Arrays.toString(str3.getBytes(Charset.forName("Unicode"))));//22位,[-2, -1, 0, 108, 0, 111, 0, 118, 0, 101, 0, 33, 98, 17, 114, 49, 79, 96, 84, -33, -1, 1]
}
public static byte[] toCharBytes(String str) {
char[] charArr = str.toCharArray();
byte[] byteArr = new byte[charArr.length*2];
for(int i=0;i<charArr.length;i++) {
//当字符是英文时,该位的编码与ASCII和ISO8859-1均相同
byteArr[2*i] = (byte)(charArr[i] & 0xFF);
//当字符是英文的时候,高位是0;如果字符是中文,那么高位不为0。并且该编码也与GBK、UTF8、Unicode都不同
byteArr[2*i+1] = (byte)((charArr[i] & 0xFF00) >>> 8);
}
return byteArr;
}
}
import java.nio.charset.Charset;
import java.util.Arrays;
/**
(1)在中国,字符串转化默认使用GBK编码
(2)转化表
英文(L) 中文(L) 混合(英文L1 + 中文L2)
DEFAULT(GBK) L 2*L L1 + 2*L2
ISO8859-1 L L L1 + L2
ASCII L L L1 + L2
GBK L 2*L L1 + 2*L2
UTF-8 L 3*L L1 + 3*L2
UNICODE 2*L+2 2*L+2 2*(L1 + L2)+2
*/
public class CharsetDemo {
public static void main(String[] args) {
System.out.println("ASCII " + Charset.isSupported("ASCII"));//true
System.out.println("Shift_JIS " + Charset.isSupported("Shift_JIS"));//true
System.out.println("ISO-8859-1 " + Charset.isSupported("ISO-8859-1"));//true
System.out.println("I-S-O-8859-1 " + Charset.isSupported("I-S-O-8859-1"));//false
System.out.println("ISO8859-1 " + Charset.isSupported("ISO8859-1"));//true
System.out.println("ISO8859_1 " + Charset.isSupported("ISO8859_1"));//true
//error: java.nio.charset.IllegalCharsetNameException
// System.out.println("ISO8859 1 " + Charset.isSupported("ISO8859 1"));
//ISO8859必须有第一版的标识否则不合法
System.out.println("ISO8859 " + Charset.isSupported("ISO8859"));//false
//ISO/IEC8859-1,又称Latin-1或“ 西欧语言”,但这里用Latin-1却是不合法的
System.out.println("Latin-1 " + Charset.isSupported("Latin-1"));//false
System.out.println("UTF8 " + Charset.isSupported("UTF8"));//true
System.out.println("UTF-8 " + Charset.isSupported("UTF-8"));//true
System.out.println("UTF_8 " + Charset.isSupported("UTF_8"));//false
//CharsetName跟大小写无关
System.out.println("Unicode " + Charset.isSupported("Unicode"));//true
System.out.println("uNiCoDe " + Charset.isSupported("uNiCoDe"));//true
String str1 = "hello world";//11位
System.out.println(Arrays.toString(str1.toCharArray()));
System.out.println(Arrays.toString(toCharBytes(str1)));
System.out.println(Arrays.toString(str1.getBytes()));//11位,[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
System.out.println(Arrays.toString(str1.getBytes(Charset.forName("ISO8859-1"))));//11位,[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
System.out.println(Arrays.toString(str1.getBytes(Charset.forName("ASCII"))));//11位,[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
System.out.println(Arrays.toString(str1.getBytes(Charset.forName("GBK"))));//11位,[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
System.out.println(Arrays.toString(str1.getBytes(Charset.forName("UTF-8"))));//11位,[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
System.out.println(Arrays.toString(str1.getBytes(Charset.forName("Unicode"))));//24位,[-2, -1, 0, 104, 0, 101, 0, 108, 0, 108, 0, 111, 0, 32, 0, 119, 0, 111, 0, 114, 0, 108, 0, 100]
System.out.println();
String str2 = "可惜不是你";//5位
System.out.println(Arrays.toString(str2.toCharArray()));
System.out.println(Arrays.toString(toCharBytes(str2)));
System.out.println(Arrays.toString(str2.getBytes()));//10位,[-65, -55, -49, -89, -78, -69, -54, -57, -60, -29]
System.out.println(Arrays.toString(str2.getBytes(Charset.forName("ISO8859-1"))));//5位,[63, 63, 63, 63, 63]
System.out.println(Arrays.toString(str2.getBytes(Charset.forName("ASCII"))));//5位,[63, 63, 63, 63, 63]
System.out.println(Arrays.toString(str2.getBytes(Charset.forName("GBK"))));//10位,[-65, -55, -49, -89, -78, -69, -54, -57, -60, -29]
System.out.println(Arrays.toString(str2.getBytes(Charset.forName("UTF-8"))));//15位,[-27, -113, -81, -26, -125, -100, -28, -72, -115, -26, -104, -81, -28, -67, -96]
System.out.println(Arrays.toString(str2.getBytes(Charset.forName("Unicode"))));//12位,[-2, -1, 83, -17, 96, -36, 78, 13, 102, 47, 79, 96]
System.out.println();
String str3 = "love!我爱你哟!";//5+5位
System.out.println(Arrays.toString(str3.toCharArray()));
System.out.println(Arrays.toString(toCharBytes(str3)));
System.out.println(Arrays.toString(str3.getBytes()));//15位,[108, 111, 118, 101, 33, -50, -46, -80, -82, -60, -29, -45, -76, -93, -95]
System.out.println(Arrays.toString(str3.getBytes(Charset.forName("ISO8859-1"))));//10位,[108, 111, 118, 101, 33, 63, 63, 63, 63, 63]
System.out.println(Arrays.toString(str3.getBytes(Charset.forName("ASCII"))));//10位,[108, 111, 118, 101, 33, 63, 63, 63, 63, 63]
System.out.println(Arrays.toString(str3.getBytes(Charset.forName("GBK"))));//15位,[108, 111, 118, 101, 33, -50, -46, -80, -82, -60, -29, -45, -76, -93, -95]
System.out.println(Arrays.toString(str3.getBytes(Charset.forName("UTF-8"))));//20位,[108, 111, 118, 101, 33, -26, -120, -111, -25, -120, -79, -28, -67, -96, -27, -109, -97, -17, -68, -127]
System.out.println(Arrays.toString(str3.getBytes(Charset.forName("Unicode"))));//22位,[-2, -1, 0, 108, 0, 111, 0, 118, 0, 101, 0, 33, 98, 17, 114, 49, 79, 96, 84, -33, -1, 1]
}
public static byte[] toCharBytes(String str) {
char[] charArr = str.toCharArray();
byte[] byteArr = new byte[charArr.length*2];
for(int i=0;i<charArr.length;i++) {
//当字符是英文时,该位的编码与ASCII和ISO8859-1均相同
byteArr[2*i] = (byte)(charArr[i] & 0xFF);
//当字符是英文的时候,高位是0;如果字符是中文,那么高位不为0。并且该编码也与GBK、UTF8、Unicode都不同
byteArr[2*i+1] = (byte)((charArr[i] & 0xFF00) >>> 8);
}
return byteArr;
}
}

相关文章推荐
- javaweb学习总结(十四)——JSP原理
- Java中的二分法查找算法
- Java 序列化Serializable详解
- Java后台---从底层了解Session会话、pageContext
- windows下Java使用RXTX的安装与配置
- 每天学Java!一分钟了解JRE与JDK
- LRU页面置换算法原理及Java代码的实现
- Java中常用工具类(效率)
- JAVA实现zip包压缩工具类
- java设计模式——抽象工厂模式(Abstract Factory Pattern)
- Java基本语法二
- Java 时期格式 星期显示英文
- Java:按值传递还是按引用传递详细解说
- Java-交通管理灯系统项目
- Java 两个变量交换值
- spring-boot actuator(监控)配置和使用
- java中的byte运算
- java过滤Emoji表情
- Java集合总结
- Java解码网页表单post内容小记