LZMA SDK 9.20(与C相关)
2016-07-27 10:35
1096 查看
1.概述
lzma是7-Zip压缩项目中7z格式的默认与通用压缩方法,压缩率高,解压速度快,需要的内存小。目录中包括ANSI-C/C++/C#/Java源码,以及用于windows的编译好的文件,以及几个文档:lzma.txt - LZMA SDK描述文件
7zFormat.txt - 7z格式描述文件
7zC.txt - 7z ANSI-C解码描述文件
methods.txt - .7z文件的压缩方式
lzma.exe - 编译好的文件,用于windows下文件到文件的解压缩
7zr.exe - 编译好的7-Zip,支持7z/lzma/xz等格式
history.txt - LZMA SDK的历史版本
2.C文件
C文件夹下:- 7zCrc*.* - CRC code
- Alloc.* - Memory allocation functions
- Bra*.* - Filters for x86, IA-64, ARM, ARM-Thumb, PowerPC and SPARC code
- LzFind.* - Match finder for LZ (LZMA) encoders
- LzFindMt.* - Match finder for LZ (LZMA) encoders for multithreading encoding
- LzHash.h - Additional file for LZ match finder
- LzmaDec.* - LZMA decoding
- LzmaEnc.* - LZMA encoding
- LzmaLib.* - LZMA Library for DLL calling
- Types.h - Basic types for another .c files
- Threads.* - The code for multithreading.
Util文件夹下:
LzmaLib - LZMA库 (.DLL for Windows)
Lzma - LZMA使用方法 (文件到文件的 LZMA encoder/decoder).
7z - 7z ANSI-C 解码器
3.用法
LZMA <e|d> inputFile outputFile [<switches>...]
e: encode file
d: decode file
<Switches>
-a{N}: 压缩模式 0 = fast, 1 = normal
default: 1 (normal)
-d{N}: 字典大小 - [0, 30], default: 23 (8MB)
字典大小最大值为 1 GB = 2^30 bytes.
计算方式为 DictionarySize = 2^N bytes.
对于用LZMA压缩的文件解压,字典大小为 D = 2^N 就需要 D bytes 内存(RAM)
-fb{N}: fast bytes 数 - [5, 273], default: 128
这个数越大,压缩比越大,速度也越慢
-lc{N}: literal context bits 数 - [0, 8], default: 3
对于大文件,通常设置 lc=4.
-lp{N}: literal pos bits 数 - [0, 4], default: 0
当周期为 2^N 时,预留给周期数据.
例如,对于 32-bit (4 bytes),可以设 lp=2.
如果这里有变化,通常要设置 lc0.
-pb{N}: pos bits 数 - [0, 4], default: 2
当周期为 2^N 时,预留给周期数据.
-mf{MF_ID}: Match Finder. Default: bt4.
hc* 组算法压缩比不好, 但当与fast mode(-a0)结合时速度很快.
内存需求取决于字典大小(下表中的参数"d").| MF_ID | Memory | Description |
|---|---|---|
| bt2 | d * 9.5 + 4MB | Binary Tree with 2 bytes hashing. |
| bt3 | d * 11.5 + 4MB | Binary Tree with 3 bytes hashing. |
| bt4 | d * 11.5 + 4MB | Binary Tree with 4 bytes hashing. |
| hc4 | d * 7.5 + 4MB | Hash Chain with 4 bytes hashing. |
-eos: 写流结束的标记.默认情况LZMA不写eos标记, 因为LZMA解码器能从.lzma文件头中知道未压缩的大小 -si: 从stdin中读数据 (将会写eos标记). -so: 把数据写到stdout
4.LZMA 压缩文件格式
| Offset | Size | Description |
|---|---|---|
| 0 | 1 | Special LZMA properties (lc,lp, pb in encoded form) |
| 1 | 4 | Dictionary size (little endian) |
| 5 | 8 | Uncompressed size (little endian). -1 means unknown size |
| 13 | Compressed data |
5.使用
要把很多头文件和c文件加入到项目中: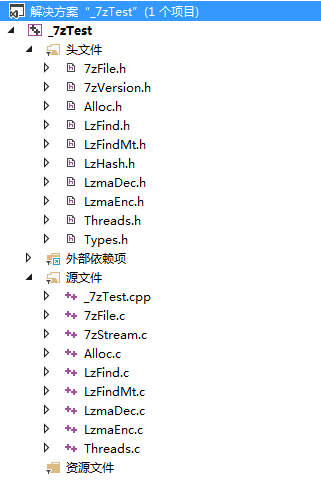
我的主文件_7zTest.cpp中的内容是:
// _7zTest.cpp : 定义控制台应用程序的入口点。
//
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "Alloc.h"
#include "7zFile.h"
#include "7zVersion.h"
#include "LzmaDec.h"
#include "LzmaEnc.h"
const char *kCantReadMessage = "Can not read input file";
const char *kCantWriteMessage = "Can not write output file";
const char *kCantAllocateMessage = "Can not allocate memory";
const char *kDataErrorMessage = "Data error";
static void *SzAlloc(void *p, size_t size) { p = p; return MyAlloc(size); }
static void SzFree(void *p, void *address) { p = p; MyFree(address); }
static ISzAlloc g_Alloc = { SzAlloc, SzFree };
int PrintError(char *buffer, const char *message)
{
strcat(buffer, "\nError: ");
strcat(buffer, message);
strcat(buffer, "\n");
return 1;
}
int PrintErrorNumber(char *buffer, SRes val)
{
sprintf(buffer + strlen(buffer), "\nError code: %x\n", (unsigned)val);
return 1;
}
int PrintUserError(char *buffer)
{
return PrintError(buffer, "Incorrect command");
}
#define IN_BUF_SIZE (1 << 16)
#define OUT_BUF_SIZE (1 << 16)
static SRes Decode2(CLzmaDec *state, ISeqOutStream *outStream, ISeqInStream *inStream,
UInt64 unpackSize)
{
int thereIsSize = (unpackSize != (UInt64)(Int64)-1);
Byte inBuf[IN_BUF_SIZE];
Byte outBuf[OUT_BUF_SIZE];
size_t inPos = 0, inSize = 0, outPos = 0;
//Init LzmaDec structure before any new LZMA stream. And call LzmaDec_DecodeToBuf in loop
LzmaDec_Init(state);
for (;;)
{
if (inPos == inSize)
{
inSize = IN_BUF_SIZE;
RINOK(inStream->Read(inStream, inBuf, &inSize));
inPos = 0;
}
{
SRes res;
SizeT inProcessed = inSize - inPos;
SizeT outProcessed = OUT_BUF_SIZE - outPos;
ELzmaFinishMode finishMode = LZMA_FINISH_ANY;
ELzmaStatus status;
if (thereIsSize && outProcessed > unpackSize)
{
outProcessed = (SizeT)unpackSize;
finishMode = LZMA_FINISH_END;
}
res = LzmaDec_DecodeToBuf(state, outBuf + outPos, &outProcessed,
inBuf + inPos, &inProcessed, finishMode, &status);
inPos += inProcessed;
outPos += outProcessed;
unpackSize -= outProcessed;
if (outStream)
if (outStream->Write(outStream, outBuf, outPos) != outPos)
return SZ_ERROR_WRITE;
outPos = 0;
if (res != SZ_OK || thereIsSize && unpackSize == 0)
return res;
if (inProcessed == 0 && outProcessed == 0)
{
if (thereIsSize || status != LZMA_STATUS_FINISHED_WITH_MARK)
return SZ_ERROR_DATA;
return res;
}
}
}
}
static SRes Decode(ISeqOutStream *outStream, ISeqInStream *inStream)
{
UInt64 unpackSize;
int i;
SRes res = 0;
CLzmaDec state;
/* header: 5 bytes of LZMA properties and 8 bytes of uncompressed size */
unsigned char header[LZMA_PROPS_SIZE + 8];
/* Read and parse header */
RINOK(SeqInStream_Read(inStream, header, sizeof(header)));
unpackSize = 0;
for (i = 0; i < 8; i++)
unpackSize += (UInt64)header[LZMA_PROPS_SIZE + i] << (i * 8);
//Allocate CLzmaDec structures (state + dictionary) using LZMA properties
LzmaDec_Construct(&state);
RINOK(LzmaDec_Allocate(&state, header, LZMA_PROPS_SIZE, &g_Alloc));
res = Decode2(&state, outStream, inStream, unpackSize);
//Free all allocated structures
LzmaDec_Free(&state, &g_Alloc);
return res;
}
static SRes Encode(ISeqOutStream *outStream, ISeqInStream *inStream, UInt64 fileSize, char *rs)
{
CLzmaEncHandle enc;
SRes res;
CLzmaEncProps props;
rs = rs;
//Create CLzmaEncHandle object
enc = LzmaEnc_Create(&g_Alloc);
if (enc == 0)
return SZ_ERROR_MEM;
//initialize CLzmaEncProps properties 初始化各压缩参数
LzmaEncProps_Init(&props);
//Send LZMA properties to LZMA Encoder
res = LzmaEnc_SetProps(enc, &props);
if (res == SZ_OK)
{
//Write encoded properties to header
Byte header[LZMA_PROPS_SIZE + 8];//LZMA properties+Dictionary size(little endian)+Uncompressed size(little endian).
size_t headerSize = LZMA_PROPS_SIZE;
int i;
res = LzmaEnc_WriteProperties(enc, header, &headerSize);//把属性写到header
for (i = 0; i < 8; i++)
header[headerSize++] = (Byte)(fileSize >> (8 * i));
if (outStream->Write(outStream, header, headerSize) != headerSize)
res = SZ_ERROR_WRITE;
else
{
if (res == SZ_OK)
//Call encoding function
res = LzmaEnc_Encode(enc, outStream, inStream, NULL, &g_Alloc, &g_Alloc);
}
}
//Destroy LZMA Encoder Object
LzmaEnc_Destroy(enc, &g_Alloc, &g_Alloc);
return res;
}
int main2(int numArgs, const char *args[], char *rs)
{
CFileSeqInStream inStream; //输入文件流
CFileOutStream outStream; //输出文件流
char c; //记录操作
int res;
int encodeMode;
Bool useOutFile = False; //记录是否自定义输出文件
FileSeqInStream_CreateVTable(&inStream); //
File_Construct(&inStream.file); //
FileOutStream_CreateVTable(&outStream);
File_Construct(&outStream.file);
if (numArgs < 2 || numArgs > 3 || strlen(args[0]) != 1)//参数数量不对或第一个参数长度不为1
return PrintUserError(rs);
c = args[0][0];
encodeMode = (c == 'e' || c == 'E');//encodeMode为1表示压缩
if (!encodeMode && c != 'd' && c != 'D')//encodeMode不为1且不表示解压,出错
return PrintUserError(rs);
{
size_t t4 = sizeof(UInt32);
size_t t8 = sizeof(UInt64);
if (t4 != 4 || t8 != 8) //检查机器位数
return PrintError(rs, "Incorrect UInt32 or UInt64");
}
if (InFile_Open(&inStream.file, args[1]) != 0) //打开输入文件
return PrintError(rs, "Can not open input file");
if (numArgs > 2) //若有输出文件参数
{
useOutFile = True;
if (OutFile_Open(&outStream.file, args[2]) != 0)
return PrintError(rs, "Can not open output file");
}
else if (encodeMode) //压缩模式必须自己定义输出文件
PrintUserError(rs);
if (encodeMode)
{
UInt64 fileSize;
File_GetLength(&inStream.file, &fileSize); //获取文件长度
res = Encode(&outStream.s, &inStream.s, fileSize, rs);
}
else
{
res = Decode(&outStream.s, useOutFile ? &inStream.s : NULL); //解压模式
}
if (useOutFile)
File_Close(&outStream.file);
File_Close(&inStream.file);
if (res != SZ_OK)
{
if (res == SZ_ERROR_MEM)
return PrintError(rs, kCantAllocateMessage);
else if (res == SZ_ERROR_DATA)
return PrintError(rs, kDataErrorMessage);
else if (res == SZ_ERROR_WRITE)
return PrintError(rs, kCantWriteMessage);
else if (res == SZ_ERROR_READ)
return PrintError(rs, kCantReadMessage);
return PrintErrorNumber(rs, res);
}
return 0;
}
int MY_CDECL main()//C Declaration
{
char rs[800] = { 0 };
//const char *args[] = {"e", "Z:\\b.xml", "Z:\\bb.7z" };//压缩
const char *args[] = {"d", "Z:\\bb.7z", "Z:\\b.xml" };//解压
int numArgs = sizeof(args) / sizeof(args[0]);
int res = main2(numArgs, args, rs);
fputs(rs, stdout);
return res;
}由lzma920\C\Util\Lzma\LzmaUtil.c修改而来。

相关文章推荐
- 如何组织构建多文件 C 语言程序(二)
- Android ADT 23.0.0无法更新到23.0.2问题解决方案
- 如何写好 C main 函数
- SDKMAN:轻松管理多个软件开发套件 (SDK) 的命令行工具
- Lua和C语言的交互详解
- 关于C语言中参数的传值问题
- 简要对比C语言中三个用于退出进程的函数
- 深入C++中API的问题详解
- 基于C语言string函数的详解
- C语言中fchdir()函数和rewinddir()函数的使用详解
- C语言内存对齐实例详解
- C语言编程中统计输入的行数以及单词个数的方法
- C 语言简单加减乘除运算
- C语言自动生成enum值和名字映射代码
- C语言练习题:自由落体的小球简单实例
- 使用C语言判断英文字符大小写的方法
- c语言实现的带通配符匹配算法
- C语言实现顺序表基本操作汇总
- C语言中进制知识汇总
- C语言判断一个数是否是2的幂次方或4的幂次方