git原理-文件是如何存储的
2016-07-26 20:42
288 查看
git原理-文件是如何存储的
一直都对git的存储原理都很好奇,所以今天就专门研究了一下,记录一下研究的过程。我们以这样的目录结构为例来研究,

首先cd gitTest目录,初始化使用 git init 命令,执行了这个命令之后gitTest目录下回生成一个.git文件,我们查看一下这个文件下都有什么内容,如下:

然后执行:
git add –all
git commit -am “commit 1 。。。。。。”
这我们优先看objects目录,git会将所有改动的文件存到.git/objects/的文件夹下,查看一下内容:
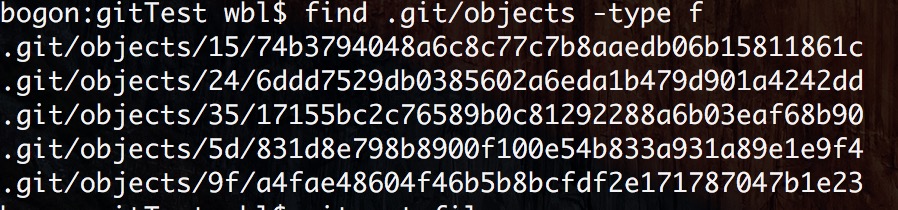
1.git文件对象
git的文件对象分为四类分别为blob、tree、commit、tags。git管理的文件都以blob类型存在,而目录文件则以tree类型存在,tree类型内部可以引用若干个blob和tree文件。
也就是说当我们执行了commit 之后git 会依照我们工程的目录结构在objects里相应的建立一套blob和tree文件,可是我们的示例工程只有两个文件和一个文件夹,为什么objects里确有五个文件那,这里就要说说commit类型了,commit类型内部可以引用一个tree类型文件和一个commit类型文件。
关于文件的名字,objects内部的文件全部是以sha-1命名,如果是blob类型则以文件内容做sha-1计算得出40字符的校验和,然后为了不让这个objects内部文件过多,所以使用40字符的前两位来建立一个文件夹,在以后38位为文件名,包括commit 和tree 全部使用sha-1校验和来命名。
接下来说一下这五个文件是以什么结构关联的:
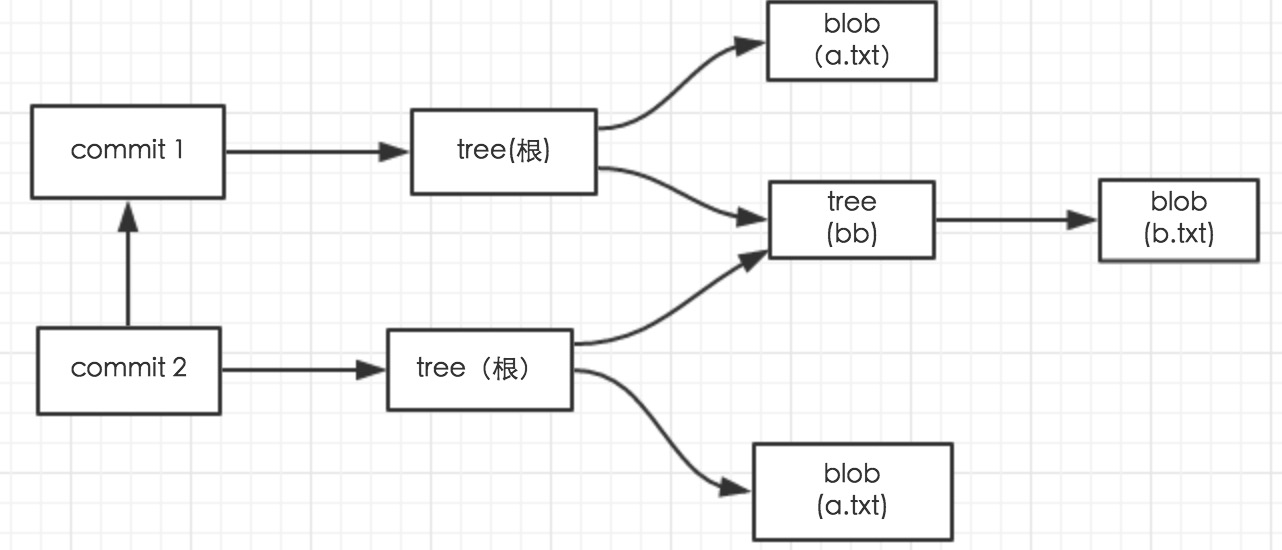
每个commit 引用一个tree,根据工程目录结构这个tree 在引用一个blob(a.txt)和一个tree(bb) ,这个tree(bb)则引用一个blob(b.txt)如图:

通过这个图就可以看出来commit,tree,blob的关系了,也基本能明白为什么objects下有五个文件了,
现在我改动一下a.txt然后在提交一个版本,在a.txt添加22222222222内容执行add和commit,添加一个版本,接下来再看objects内部的情况:
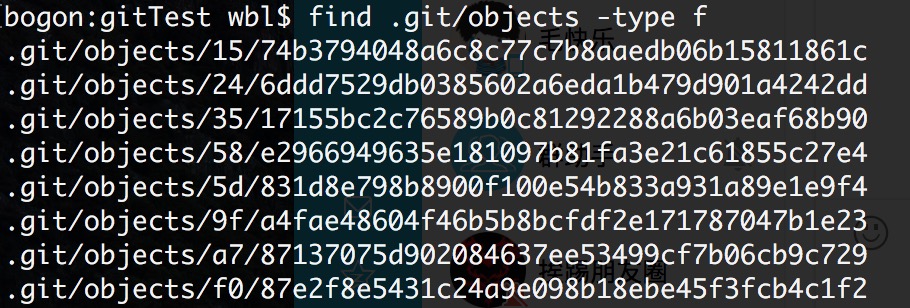
比刚刚多了三个文件,究竟是哪三个文件?因为我们改动了a.txt文件,所以这里在保留上一个版本的a.txt的基础上新增加一个a.txt文件,git只对有改动的文件进行备份保留。另外两个文件分别是commit 2和一个根tree,现在这8个文件的关系如图:
commit文件内部可以引用一个commit,这样commit之间就可以建立关系了,因为只有a.txt文件做了改动所以只有a.txt文件新建了一个,然后被commit2引用,bb和b.txt文件未做改动则commit2依然引用之前的文件。同理如果我们再改动b.txt文件,我们可以设想一下这些文件的关联关系。如图:

2.branch分支
git branch 可以获取当前的分支列表,这个分支列表会保存在./git/refs/heads/这个路径下,这里包含master和一些其他分支文件,以master文件为例查看master文件内容如下:
其实这是一个commit类型 的文件名,这样每个分支都可以拥有一个自己的commit引用,从上上面的图可以看出只要拿到commit的文件名就可以找到所有跟他关联的文件,还有个问题是./git/refs/heads/这个文件下是所有分支信息,总要有一个当前分支,其实这个当前分支是被记录在./git/HEAD文件内部的查看一下:

因为当前是master分支所以HEAD文件里记录的是master,每次我们git checkout 某某来切换分支的时候就是在修改HEAD这个件内容。那么我们基本就可以理解我们首先选择一个分支为当前分支,每个分支里记录着当前分支最顶端的commit对象,这个commit对象又可以找到所有跟它关联tree和blob,同时commit对象又和它的历史commit关联。我们可以任意切换当前分支,同时又可以修改当前分支指向的commit对象,比如我们执行reset可以选择回退到任意一个commit。这些就可以顺理成章切换任意分支并且找到任意版本的文件了。

相关文章推荐
- hdu5754 Life Winner Bo(博弈)
- 【HD 2141】Can you find it?
- Android Studio,“Failed to sync Gradle project 'xxxx' ”的解决
- 【SHOI2001】洛谷2530 化工厂装箱员
- 隐藏标题栏
- 【杭电2141】Can you find it?
- bat批处理设置Java JDK系统环境变量文件
- paper 99:CV界的明星人物经典介绍
- HeadFirst设计模式读书笔记——简单工厂模式
- Volley的使用(三):Volley与Activity的联动 + Volley的二次封装
- ubuntu 环境变量设置
- express,使用session进行身份认证
- Java多线程面试题
- line-height 和 vertical-align 行高与行对齐精解 (图文)
- HDU 5750 Dertouzos (数论)
- 2016.7.26 随记
- 关于输入流(从硬盘文件输入到程序中)
- echo命令的详细用法
- mac maven的配置和安装
- HDU 1003