dalvik VM的解释器分析
2016-07-25 17:29
621 查看
以KK的dalvik源码为基础来解析。
使用的源码基于https://github.com/AOKP/dalvik, 可以从https://github.com/AOKP/dalvik/archive/kitkat.zip
下载。
我是在linux下,使用vim + ctags做分析的。
由于ARM架构是使用最多也是最频繁的架构,所以我分析的重点是ARM的汇编如何实现解释器的。所以我在分析过程中会忽略掉与ARM无关的代码。
dvmCallMethod->dvmCallMethodV->dvmInterpret->dvmMterpStd->dvmMterpStdRun
这一串调用,最终走到了dvmMterpStdRun函数。这个函数是用汇编写成的,在ARM架构中,实现的文件是vm/mterp/out/InterpAsm-armv7-a-neon.S。这个是Android KK ARM版本中使用的文件,也是我们分析的重点。
说了半天,dvmMterpStdRun是干什么的?其实就是用于解释实现各个dex 指令的,是整个解释的核心。不过,在正式了解这个函数之前,我们要分别了解下dvmCallMethodV,dvmInterpret,dvmMethodStd这3个函数的主要功能和涉及到的数据结构。
这些函数并不直接执行代码,但是却为dvmMterpStdRun准备了运行环境,只有理解了这些运行环境,才能更好的理解解释器的工作原理。
首先,我们了解下,一个普通的java method调用链条中的虚拟栈是怎么组织的。
dvmCallMethodV中完成栈构建的函数在callPrep->dvmPushInterpFrame
Thread的interpStackStart和interpStackEnd表示虚拟栈的开始和结束范围。注意,栈的增长方向是由高地址向低地址曾长,因此inpterpStackStart >interpStackEnd。
inpterpSave的curFrame记录了当前虚拟栈(Frame)的位置。
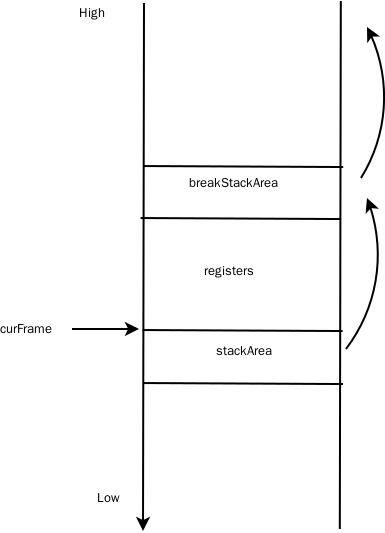
我用下面的表来表示虚拟栈的组成部分:

StackSaveArea保存的是一个method 栈的信息,如当前的Method, 调用的PC地址,返回值地址等,还有prevFrame,指向Caller的frame地址;
curFrame保存当前函数的Frane地址。这个地址不包含StackSaveArea的指针。
method的registersSize指出全部寄存器的个数,包括用作参数传递的寄存器个数;
method的insSize指出作为参数的寄存器的个数;
method的outsSize指出该函数调用其他函数需要的寄存器个数
关于registerSize,insSize和outsSize的关系,以下几点:
参数寄存器 (ins registers)是全部寄存器的一部分,所以,insSize < registerSize;
outsSize是调用其他函数需要的寄存器个数,这只是一个参考值。因为一个函数可以调用N个函数,这些被调用的函数的参数个数不一样,所以,outsSize总是取被调用函数中参数最多的那个值作为它的值;
假设函数A调用函数B,A 向它的out register写入调用参数,当进入B函数后,A的out register就变成了B的ins register。这样,B就可以直接访问A传递过来的参数了。
ins register是register的一部分,在函数内部是可以参与运算的。因为需要和调用者共用,所以ins register总是位于虚拟栈的最高地址处。
关于参数,还需有注意一点:非静态函数,参数P0被隐含定义为this指针。
如下图:
pc: 保存的是当前正在执行的dalvik代码的地址
curFrame: 当前的frame地址,与StackSaveArea中的 curFrame是一致的
method: 当前调用的Method对象
methodClassDex: 当前method所属的DvmDex对象。这个对象包含了一个Dex文件对象和解析表(ResolvedClasses, ResolvedMethod, ResolvedString和ResolevedField等)
retval:返回值
bailPtr: 保存的是寄存器sp的地址,用于恢复解释器的堆栈
prev:指向上一个InterpSaveState对象。这个链表的建立就是在dvmIntepreter函数中实现的。
解释器要不断的更新这些值,保持这些值与运行状态一致。
整个mode可以分为两类,第一类是kSubModeNormal,这种模式下,解释器正常执行dalvik的字节码;其余可以归结为另一类,这类模式下,在执行dalvik字节码之前,先要调用一个dvmCheckBefore函数,这个函数会根据不同的submode,执行不同的操作,为debug,jit的trace code等功能,提供入口。
这个枚举值记录在Thread::InterpBreak.ctl.subMode中。
他通过调用 dvmDisableSubMode/dvmEnableSubMode -> updateInterpBreak函数来实现对模式的切换。
其中,newValue.ctl.curHandlerTable取mainHandlerTable与altHandlerTable中的一个。mainHandlerTable的对应kSubModeNormal,表示不加dvmCheckBefore调用的实现;altHandlerTable就是加dvmCheckBefore的调用。
而curHandleTable就是解释器的入口函数地址。
mainHandlerTable与altHandlerTable的值来自./vm/Thread.cpp的allocThread函数:
当完成这些操作后,dvm就会调用到函数dvmMterpStd。
这里还需要解释下,handleTable是什么样的概念,以及与dvmMterpStd有何不同。
dvmMterpStd是解释器的入口函数,而handleTable则是一个表,与dalvik字节码对应的一个表。dalvik字节码由两部分组成:操作代码(opcode)和操作数(operand)组成。
opcode由1个字节组成,operand则可以是0~5个更多。所以opcode最大是255。比如:
所以,一个opcode对应一段汇编代码,然后将这些汇编代码按照opcode的值顺序排列起来,就成了handleTable了。当我们执行时,只需要取出opcode对应的汇编码地址,就可以直接跳转并执行了。
详细的实现,厚文中介绍。
我们所阅读的汇编代码,主要在vm/mterp/out/InterpAsm-armv7-a-neon.S文件中。
第一行,".balign 64" 表示代码从64字节处对齐。这条伪指令表形成的关键。所有的opcode对应的汇编码都是从64字节处对齐的,也就是说,opcode对应的汇编码,其最大大小是64字节。由此,handleTable就是一个64*opcode_count的数组,只要用 handleTableStart + opcode*64就可以得到opcode对应的地址了。
.L_OP_MOVE: 这个是标签,标签的取名是用 .L_OP_<opcode助记符大写> 组成的
GOTO_OPCODE(ip):该宏的作用,是跳转到下条指令
我们知道,mainHandlerTable对应的dvmAsmInstructionStart是从.L_OP_NONE开始的,汇编代码按照opcode的值顺序排列下来,每个标签间隔64字节,这样,就形成了一个完整的表。
lr是link register的缩小,代表函数返回地址。一般情况下,我们调用一个函数,用bl <func>的形式。bl是branch link的缩写,即跳转到<func>函数入口,然后把返回地址写入lr寄存器。当<func>函数返回时,从lr中读取返回地址。
大家请注意,上面代码最后一句: b dvmCheckBefore,用b指令(branch),则只跳转,不改写lr寄存器的值,那么这个时候,寄存器的值就是.L_OP_MOV的地址,那就是说,当 dvmCheckBefore函数返回后,将直接返回到.L_OP_MOV处继续执行。
这就是dvm的小伎俩。所有的altHandle都是这么处理的。这样,在正式执行指令之前,我们就可以调用dvmCheckBefore做些处理了。
rPC: 是当前正在执行的字节码的地址
rIBASE: 这个是curHandlerTable的地址
rSELF: 当前Thread对象指针
rFP : curFrame的地址
rINST: 当前的字节码值,只有低16位被用到,因为字节码以16位为一个单位。
r0~r3:是用作临时寄存器的
r10 : 作为一个通用寄存器来使用
r12(ip) 用作指令跳转的寄存器
其余的被操作系统使用
他们的作用是获取inst到寄存器rINST或者其他寄存器。
以其中一个为例:
最后的一个"!"表示rPC在取值后要加上_count*2。
如
GOTO_OPCODE宏,就是 pc = rIBASE + (_reg << 6)
_reg << 6 相当于 _reg *64。rIBASE是curHandleTable的值,_reg的值,必须是opcode的值,这个就是直接跳转到指定的opcode上去。
addeq表示标志寄存器比较标志为0时跳转,addne则表示不为零时跳转。
我以const指令为例
const指令的助记符形式是
按照小端字节的排列顺序,这些值保存在 op|AA BBBB bbbb。除了"op"外,一个字母表示4位。
可以看到,上面的代码含义是:
如果DvmDex的pResStrings已经有解析好的stirng对象,直接取出,否则就调用dvmResolveString来解析。dvmResolveString函数会解析出字符串后再把他们添加到DvmDex的pResStrings中去,下次使用时,就不必再次解析了。
在这里,指令里面包含了字符串的string ID,通过该ID来解析字符串。
实现同string非常相似,主要不同在于它调用了dvmResolveClass来解析。
根据名字,我们就大概知道其功能了。其中mov/result, mov/result_wide,是从Thread.retal中读取对应的值。当return时,解释器会将函数结果存储在Thread::retval变量中。
还是看看mov的例子吧
我们只要看看iget就知道他们的大致写法了
field的索引保存在CCCC部分,一个字母表示4位。CCCC最大值是65535。
如果field没有解析,还需有调用dvmResolveInstField先解析他,然后在继续运行。由于iget指令需要的代码数超出了64字节,因此用.LOP_IGET_FINISH完成剩余的工作。
其中static, direct, native函数都是非常接近的。它们的主要不同,在于获取被调用method的方法不同。
对于DVM来说,要invoke一个方法,需要经历3个步骤:
取得method
准备参数
准备栈结构
最后跳转到第一条指令并执行
字节码的形式是
用伪码表示就是
这是最简单的形式
super的实现与virtual很类似,所不同的是,对于super,需要从this->clazz->super->vtable中获取method。
dvmFindInterfaceMethodInCache->dvmInterpFindInterfaceMethod,他们将解析出的真正method缓存起来,用hash表将interface method,class与对应的真实method关联起来。
首先,我们看看,如何从ineterface的method找到implements class的method。
[b]从ineterface的method找到implements class的method
该功能由函数dvmInterpFindInterfaceMethod来实现的。这个算法的核心是InterfaceEntry结构。每个class都有这样一个结构,叫做iftable。iftable是一个InterfaceEntry结构的数组。这个结构如下:
clazz:成员指定了当前一个class implememts其中的一个interface的clazz对象
methodIndexArray:interface的method在implements类中的对应的implement method在vtable中的索引
下面的源代码给出了基本的实现:
cache的结构和存储方法
每次都需要resolve interface method和一个for循环来查找InterfaceEntry结构,效率很低,于是,dvm引入了一个hash表来解决这个问题。
cache的定义通过宏ATOMIC_CACHE_LOOKUP来实现。
hash表的定义在Thread::pDevDex::pInterfaceCache。这个数据是AtomicCache结构,这个结构是一个带有线程同步的cache结构。其中thisClass和methodId作为hash key,用于快速查找数据的实现。进一步的信息可以查看宏ATOMIC_CACHE_LOOKUP
分配"outs"空间
执行参数拷贝
看下分配"outs"空间部分
我将汇编与伪代码对照起来,就是
dvm用了一个小技巧:
.LinvokeArgsDone标签做最后的步骤,即准备栈并调用函数。
准备栈部分的代码如下: (删除部分关系不大的代码)
还是用r10来做临时变量,可以看到,伪代码是这样的
对于native函数的调用,我们将在另外文章中详细描述。
dvmThrowException->dvmThrowChainedException,该函数的基本功能很简单,即创建一个exception对象,然后赋值给Thread::exception成员。这就完成了异常的抛出工作。
对于用户用throw指令抛出的异常,则也是将异常赋值给Thread::exception成员。异常的创建则是由new-instance指令来完成的,而throw指令只负责把对应的exception放入到Thread::exception变量中。
当异常发生时,当前程序流程要立即中断,然后进入到catch和finally块进行处理,这些都是由common_excetptionThrown完成的。
为了方便理解,我直接将其转为伪代码,有兴趣的同学可以看源码(common_exceptionThrown标签的内容)
<span style="font-family:microsoft yahei;"><span style="white-space: pre-wrap;">exception = self->exception;
dvmAddTrackedAlloc(self, exception); //防止GC回收正在处理的exception对象
self->exception = NULL; //情况异常
void *newFP;
ret = dvmFindCatchBlock(self, rPc - self->method->insns, exception, 0, &newFP);
if (self->stackOverflowed) {
dvmCleanupStackOverflow(self, exception);
}
rFP = newFP;
if (ret != 0) //catch到了
{
</span></span> method = (rFP - sizeof(StackSaveArea))->method;
self->method = method;
rPC = method->insns + ret * 2; //指令入口
dvmReleaseTrackedAlloc(exception, self);
rIBASE = self->curHandlerTable;
rINST = *rPC & 0xffff;
ip = rINST & 0xff; //取得opcode
pc = rIBASE + ip * 64;
<span style="font-family: 'microsoft yahei'; white-space: pre-wrap;">} else { //没有catch到
//进一步抛出异常
}</span>dvmFindCatchBlock是整个处理过程的核心,它返回catch(包括finally的处理地址和所在frame的地址。有了这两个信息后,dvm就能重建frame并跳转了。
我们知道,frame上有StackSaveArea,该结构保存了prevFrame和savedPc两个重要成员。prevFrame能让我们遍历整个数据栈,一直遇到一个BreakSaveArea。因为异常的处理不能跨越native函数,即如果A->nativeB->C->D,如果D发生异常,那么遍历到nativeB后就要停止,返回到nativeB函数,让nativeB函数去处理异常,或者继续抛出给A函数处理。
每个method的代码中都包含了catch信息,catch信息由(excetpion, startAddr,code-length, handle addr)组成,只要判断savedPc是否在startAddr和code-length中间,就能知道catch是否找到了。这个由函数dvmFindCatchBlock实现。
使用的源码基于https://github.com/AOKP/dalvik, 可以从https://github.com/AOKP/dalvik/archive/kitkat.zip
下载。
我是在linux下,使用vim + ctags做分析的。
由于ARM架构是使用最多也是最频繁的架构,所以我分析的重点是ARM的汇编如何实现解释器的。所以我在分析过程中会忽略掉与ARM无关的代码。
入口是什么?
从dvmCallMethod开始分析。这个函数是调用一个java method的主要入口函数。dvmCallMethod->dvmCallMethodV->dvmInterpret->dvmMterpStd->dvmMterpStdRun
这一串调用,最终走到了dvmMterpStdRun函数。这个函数是用汇编写成的,在ARM架构中,实现的文件是vm/mterp/out/InterpAsm-armv7-a-neon.S。这个是Android KK ARM版本中使用的文件,也是我们分析的重点。
说了半天,dvmMterpStdRun是干什么的?其实就是用于解释实现各个dex 指令的,是整个解释的核心。不过,在正式了解这个函数之前,我们要分别了解下dvmCallMethodV,dvmInterpret,dvmMethodStd这3个函数的主要功能和涉及到的数据结构。
这些函数并不直接执行代码,但是却为dvmMterpStdRun准备了运行环境,只有理解了这些运行环境,才能更好的理解解释器的工作原理。
dvmCallMethodV
这个函数的核心作用是创建虚拟栈。首先,我们了解下,一个普通的java method调用链条中的虚拟栈是怎么组织的。
dvmCallMethodV中完成栈构建的函数在callPrep->dvmPushInterpFrame
普通java method的虚拟栈
DVM为解释器分配的专门的栈,每个java线程有一个。这些信息保存在Thread结构体中。//vm/interp/InterpState.h
struct InterpSaveState {
const u2* pc; // Dalvik PC
u4* curFrame; // Dalvik frame pointer
const Method *method; // Method being executed
DvmDex* methodClassDex;
JValue retval;
void* bailPtr;
....
struct InterpSaveState* prev; // To follow nested activations
} __attribute__ ((__packed__));
//vm/Thread.h
/*
* Our per-thread data.
*
* These are allocated on the system heap.
*/
struct Thread {
/*
* Interpreter state which must be preserved across nested
* interpreter invocations (via JNI callbacks). Must be the first
* element in Thread.
*/
InterpSaveState interpSave;
.....
/* current limit of stack; flexes for StackOverflowError */
const u1* interpStackEnd;
......
/* start (high addr) of interp stack (subtract size to get malloc addr) */
u1* interpStackStart;
......
};Thread的interpStackStart和interpStackEnd表示虚拟栈的开始和结束范围。注意,栈的增长方向是由高地址向低地址曾长,因此inpterpStackStart >interpStackEnd。
inpterpSave的curFrame记录了当前虚拟栈(Frame)的位置。
我用下面的表来表示虚拟栈的组成部分:
StackSaveArea保存的是一个method 栈的信息,如当前的Method, 调用的PC地址,返回值地址等,还有prevFrame,指向Caller的frame地址;
curFrame保存当前函数的Frane地址。这个地址不包含StackSaveArea的指针。
method的registersSize指出全部寄存器的个数,包括用作参数传递的寄存器个数;
method的insSize指出作为参数的寄存器的个数;
method的outsSize指出该函数调用其他函数需要的寄存器个数
关于registerSize,insSize和outsSize的关系,以下几点:
参数寄存器 (ins registers)是全部寄存器的一部分,所以,insSize < registerSize;
outsSize是调用其他函数需要的寄存器个数,这只是一个参考值。因为一个函数可以调用N个函数,这些被调用的函数的参数个数不一样,所以,outsSize总是取被调用函数中参数最多的那个值作为它的值;
假设函数A调用函数B,A 向它的out register写入调用参数,当进入B函数后,A的out register就变成了B的ins register。这样,B就可以直接访问A传递过来的参数了。
ins register是register的一部分,在函数内部是可以参与运算的。因为需要和调用者共用,所以ins register总是位于虚拟栈的最高地址处。
关于参数,还需有注意一点:非静态函数,参数P0被隐含定义为this指针。
dvmCallMethodV的栈特点
dvmCallMethodV要插入一个BreakStackSaveArea对象,这也是个StackSaveArea,用于模拟一个栈,保证调用链条的连续性。如下图:
dvmInterpret
该函数是解释模式的入口函数。在介绍这个函数之前,需要介绍两个重要的概念:InterpSaveState和ExecutionSubModesInterpSaveState
InterpSaveState 结构体保存在Thread中,用于存储解释模式中重要的数据结构。它的定义如下: (vm/interp/InterpState.h)struct InterpSaveState {
const u2* pc; // Dalvik PC
u4* curFrame; // Dalvik frame pointer
const Method *method; // Method being executed
DvmDex* methodClassDex;
JValue retval;
void* bailPtr;
#if defined(WITH_TRACKREF_CHECKS)
int debugTrackedRefStart;
#else
int unused; // Keep struct size constant
#endif
struct InterpSaveState* prev; // To follow nested activations
} __attribute__ ((__packed__));pc: 保存的是当前正在执行的dalvik代码的地址
curFrame: 当前的frame地址,与StackSaveArea中的 curFrame是一致的
method: 当前调用的Method对象
methodClassDex: 当前method所属的DvmDex对象。这个对象包含了一个Dex文件对象和解析表(ResolvedClasses, ResolvedMethod, ResolvedString和ResolevedField等)
retval:返回值
bailPtr: 保存的是寄存器sp的地址,用于恢复解释器的堆栈
prev:指向上一个InterpSaveState对象。这个链表的建立就是在dvmIntepreter函数中实现的。
解释器要不断的更新这些值,保持这些值与运行状态一致。
ExecutionSubModes
它是一个枚举值,它的定义如下:/*
* Execution sub modes, e.g. debugging, profiling, etc.
* Treated as bit flags for fast access. These values are used directly
* by assembly code in the mterp interpeter and may also be used by
* code generated by the JIT. Take care when changing.
*/
enum ExecutionSubModes {
kSubModeNormal = 0x0000, /* No active subMode */
kSubModeMethodTrace = 0x0001,
kSubModeEmulatorTrace = 0x0002,
kSubModeInstCounting = 0x0004,
kSubModeDebuggerActive = 0x0008,
kSubModeSuspendPending = 0x0010,
kSubModeCallbackPending = 0x0020,
kSubModeCountedStep = 0x0040,
kSubModeCheckAlways = 0x0080,
kSubModeSampleTrace = 0x0100,
kSubModeJitTraceBuild = 0x4000,
kSubModeJitSV = 0x8000,
kSubModeDebugProfile = (kSubModeMethodTrace |
kSubModeEmulatorTrace |
kSubModeInstCounting |
kSubModeDebuggerActive)
};整个mode可以分为两类,第一类是kSubModeNormal,这种模式下,解释器正常执行dalvik的字节码;其余可以归结为另一类,这类模式下,在执行dalvik字节码之前,先要调用一个dvmCheckBefore函数,这个函数会根据不同的submode,执行不同的操作,为debug,jit的trace code等功能,提供入口。
这个枚举值记录在Thread::InterpBreak.ctl.subMode中。
他通过调用 dvmDisableSubMode/dvmEnableSubMode -> updateInterpBreak函数来实现对模式的切换。
/*
* Update interpBreak for a single thread.
*/
void updateInterpBreak(Thread* thread, ExecutionSubModes subMode, bool enable)
{
InterpBreak oldValue, newValue;
do {
.....
#ifndef DVM_NO_ASM_INTERP
newValue.ctl.curHandlerTable = (newValue.ctl.breakFlags) ?
thread->altHandlerTable : thread->mainHandlerTable;
#endif
} while (dvmQuasiAtomicCas64(oldValue.all, newValue.all,
&thread->interpBreak.all) != 0);
};
#endif
} while (dvmQuasiAtomicCas64(oldValue.all, newValue.all,
&thread->interpBreak.all) != 0);
}循环的目的只是为了做原子同步。其中,newValue.ctl.curHandlerTable取mainHandlerTable与altHandlerTable中的一个。mainHandlerTable的对应kSubModeNormal,表示不加dvmCheckBefore调用的实现;altHandlerTable就是加dvmCheckBefore的调用。
而curHandleTable就是解释器的入口函数地址。
mainHandlerTable与altHandlerTable的值来自./vm/Thread.cpp的allocThread函数:
#ifndef DVM_NO_ASM_INTERP thread->mainHandlerTable = dvmAsmInstructionStart; thread->altHandlerTable = dvmAsmAltInstructionStart; thread->interpBreak.ctl.curHandlerTable = thread->mainHandlerTable; #endifdvmAsmInstructionStart和dvmAsmAltInstructionStart的定义在(vm/mterp/out/InterpAsm-armv7-a-neon.S 这是主流设备的架构)
368 .global dvmAsmInstructionStart 369 .type dvmAsmInstructionStart, %function 370 dvmAsmInstructionStart = .L_OP_NOP ..... 9684 .global dvmAsmAltInstructionStart 9685 .type dvmAsmAltInstructionStart, %function 9686 .text 9687 9688 dvmAsmAltInstructionStart = .L_ALT_OP_NOP
当完成这些操作后,dvm就会调用到函数dvmMterpStd。
这里还需要解释下,handleTable是什么样的概念,以及与dvmMterpStd有何不同。
dvmMterpStd是解释器的入口函数,而handleTable则是一个表,与dalvik字节码对应的一个表。dalvik字节码由两部分组成:操作代码(opcode)和操作数(operand)组成。
opcode由1个字节组成,operand则可以是0~5个更多。所以opcode最大是255。比如:
mov v1, v2该字节码就是令v1 = v2。mov是opcode的助记符,v1, v2就是operand。
所以,一个opcode对应一段汇编代码,然后将这些汇编代码按照opcode的值顺序排列起来,就成了handleTable了。当我们执行时,只需要取出opcode对应的汇编码地址,就可以直接跳转并执行了。
详细的实现,厚文中介绍。
dvmMterpStd
dvmMterpStd函数通过调用dvmMterpStdRun以真正进入到解释器入口中。如何读懂VM 解释器的汇编码?
你需要了解基本的ARM汇编。如果不了解可以从网上了解下,只需要一些入门的知识即可。我们所阅读的汇编代码,主要在vm/mterp/out/InterpAsm-armv7-a-neon.S文件中。
HandlerTable
mainHandlerTable
VM汇编解释器中的核心代码是每个dalvik opcode对应的汇编代码段组成的handle表。这个表上面我们已经初步介绍了,现在我们介绍下其具体的实现。大家看一个例子:/* ------------------------------ */ .balign 64 .L_OP_MOVE: /* 0x01 */ /* File: armv6t2/OP_MOVE.S */ /* for move, move-object, long-to-int */ /* op vA, vB */ mov r1, rINST, lsr #12 @ r1<- B from 15:12 ubfx r0, rINST, #8, #4 @ r0<- A from 11:8 FETCH_ADVANCE_INST(1) @ advance rPC, load rINST GET_VREG(r2, r1) @ r2<- fp GET_INST_OPCODE(ip) @ ip<- opcode from rINST SET_VREG(r2, r0) @ fp[A]<- r2 GOTO_OPCODE(ip) @ execute next instruction
第一行,".balign 64" 表示代码从64字节处对齐。这条伪指令表形成的关键。所有的opcode对应的汇编码都是从64字节处对齐的,也就是说,opcode对应的汇编码,其最大大小是64字节。由此,handleTable就是一个64*opcode_count的数组,只要用 handleTableStart + opcode*64就可以得到opcode对应的地址了。
.L_OP_MOVE: 这个是标签,标签的取名是用 .L_OP_<opcode助记符大写> 组成的
GOTO_OPCODE(ip):该宏的作用,是跳转到下条指令
我们知道,mainHandlerTable对应的dvmAsmInstructionStart是从.L_OP_NONE开始的,汇编代码按照opcode的值顺序排列下来,每个标签间隔64字节,这样,就形成了一个完整的表。
altHandlerTable的小技巧
altHandlerTable指向的dvmAsmAltInstructionStart,是一组以.L_ALT_OP_<opcode助记符大写> 的标签组成,这些标签也是以64字节对齐的。 altHandlerTable实际上只是实现了一个跳转,比如.L_ALT_OP_MOVE在调用完dvmCheckBefore后,在转而调用.L_OP_MOV的。我们还是以mov指令为例:/* ------------------------------ */ .balign 64 .L_ALT_OP_MOVE: /* 0x01 */ /* File: armv5te/alt_stub.S */ /* * Inter-instruction transfer stub. Call out to dvmCheckBefore to handle * any interesting requests and then jump to the real instruction * handler. Note that the call to dvmCheckBefore is done as a tail call. * rIBASE updates won't be seen until a refresh, and we can tell we have a * stale rIBASE if breakFlags==0. Always refresh rIBASE here, and then * bail to the real handler if breakFlags==0. */ ldrb r3, [rSELF, #offThread_breakFlags] adrl lr, dvmAsmInstructionStart + (1 * 64) ldr rIBASE, [rSELF, #offThread_curHandlerTable] cmp r3, #0 bxeq lr @ nothing to do - jump to real handler EXPORT_PC() mov r0, rPC @ arg0 mov r1, rFP @ arg1 mov r2, rSELF @ arg2 b dvmCheckBefore @ (dPC,dFP,self) tail call重点看
adrl lr, dvmAsmInstructionStart + (1 * 64)这句话的意思是lr = dvmAsmInstructionStart + 1 * 64,其结果,就是lr = .L_OP_MOV的地址。
lr是link register的缩小,代表函数返回地址。一般情况下,我们调用一个函数,用bl <func>的形式。bl是branch link的缩写,即跳转到<func>函数入口,然后把返回地址写入lr寄存器。当<func>函数返回时,从lr中读取返回地址。
大家请注意,上面代码最后一句: b dvmCheckBefore,用b指令(branch),则只跳转,不改写lr寄存器的值,那么这个时候,寄存器的值就是.L_OP_MOV的地址,那就是说,当 dvmCheckBefore函数返回后,将直接返回到.L_OP_MOV处继续执行。
这就是dvm的小伎俩。所有的altHandle都是这么处理的。这样,在正式执行指令之前,我们就可以调用dvmCheckBefore做些处理了。
寄存器的使用情况
我们看到有如下定义:/* single-purpose registers, given names for clarity */ #define rPC r4 #define rFP r5 #define rSELF r6 #define rINST r7 #define rIBASE r8
rPC: 是当前正在执行的字节码的地址
rIBASE: 这个是curHandlerTable的地址
rSELF: 当前Thread对象指针
rFP : curFrame的地址
rINST: 当前的字节码值,只有低16位被用到,因为字节码以16位为一个单位。
r0~r3:是用作临时寄存器的
r10 : 作为一个通用寄存器来使用
r12(ip) 用作指令跳转的寄存器
其余的被操作系统使用
几个重要的宏说明
FETCH_INST系列
这些包括FETCH_INST,FETCH_ADVANCE_INST, PREFETCH_ADVANCE_INST,FETCH_ADVANCE_INST_RB这些他们的作用是获取inst到寄存器rINST或者其他寄存器。
以其中一个为例:
#define FETCH_ADVANCE_INST(_count) ldrh rINST, [rPC, #((_count)*2)]!该宏的等价表达式是 rINST = *(short*)(rPC += count*2)。
最后的一个"!"表示rPC在取值后要加上_count*2。
FETCH数据系列
包括FETCH, FETCH_S, FETCH_B宏,"S"表示signed,"B"表示byte。如
#define FETCH(_reg, _count) ldrh _reg, [rPC, #((_count)*2)]
GOTO_OPCODE系列
包括下面几个宏#define GOTO_OPCODE(_reg) add pc, rIBASE, _reg, lsl #6 #define GOTO_OPCODE_BASE(_base,_reg) add pc, _base, _reg, lsl #6 #define GOTO_OPCODE_IFEQ(_reg) addeq pc, rIBASE, _reg, lsl #6 #define GOTO_OPCODE_IFNE(_reg) addne pc, rIBASE, _reg, lsl #6
GOTO_OPCODE宏,就是 pc = rIBASE + (_reg << 6)
_reg << 6 相当于 _reg *64。rIBASE是curHandleTable的值,_reg的值,必须是opcode的值,这个就是直接跳转到指定的opcode上去。
addeq表示标志寄存器比较标志为0时跳转,addne则表示不为零时跳转。
VREG操作系列
#define GET_VREG(_reg, _vreg) ldr _reg, [rFP, _vreg, lsl #2] #define SET_VREG(_reg, _vreg) str _reg, [rFP, _vreg, lsl #2]这两个是用来获取虚拟寄存器中的值到指定寄存器的函数。
Thread管理相关的宏
/* save/restore the PC and/or FP from the thread struct */
#define LOAD_PC_FROM_SELF() ldr rPC, [rSELF, #offThread_pc]
#define SAVE_PC_TO_SELF() str rPC, [rSELF, #offThread_pc]
#define LOAD_FP_FROM_SELF() ldr rFP, [rSELF, #offThread_curFrame]
#define SAVE_FP_TO_SELF() str rFP, [rSELF, #offThread_curFrame]
#define LOAD_PC_FP_FROM_SELF() ldmia rSELF, {rPC, rFP}
#define SAVE_PC_FP_TO_SELF() stmia rSELF, {rPC, rFP}
/*
* "export" the PC to the stack frame, f/b/o future exception objects. Must
* be done *before* something throws.
*
* In C this is "SAVEAREA_FROM_FP(fp)->xtra.currentPc = pc", i.e.
* fp - sizeof(StackSaveArea) + offsetof(SaveArea, xtra.currentPc)
*
* It's okay to do this more than once.
*/
#define EXPORT_PC() \
str rPC, [rFP, #(-sizeofStackSaveArea + offStackSaveArea_currentPc)]
/*
* Given a frame pointer, find the stack save area.
*
* In C this is "((StackSaveArea*)(_fp) -1)".
*/
#define SAVEAREA_FROM_FP(_reg, _fpreg) \
sub _reg, _fpreg, #sizeofStackSaveArea上面这些宏都是为了读写Thread对象的成员而准备的。一些常见指令的实现分析
const指令
const指令是对所有立即数的操作,其中包括3类:数字类(整数、浮点数)、字符串类和class操作。const数字
const指令包括const/4, const/16, const, const/high16, const_wide, const_wide/32, const_wide/high16这些指令。这些指令的区别只在于数字宽度不一样。我以const指令为例
/* ------------------------------ */ .balign 64 .L_OP_CONST: /* 0x14 */ /* File: armv5te/OP_CONST.S */ /* const vAA, #+BBBBbbbb */ mov r3, rINST, lsr #8 @ r3<- AA FETCH(r0, 1) @ r0<- bbbb (low) FETCH(r1, 2) @ r1<- BBBB (high) FETCH_ADVANCE_INST(3) @ advance rPC, load rINST orr r0, r0, r1, lsl #16 @ r0<- BBBBbbbb GET_INST_OPCODE(ip) @ extract opcode from rINST SET_VREG(r0, r3) @ vAA<- r0 GOTO_OPCODE(ip) @ jump to next instruction
const指令的助记符形式是
/* const vAA, #+BBBBbbbb */要让vAA = +BBBBbbbb值。
按照小端字节的排列顺序,这些值保存在 op|AA BBBB bbbb。除了"op"外,一个字母表示4位。
可以看到,上面的代码含义是:
r3 = rINST >> 8; r0 = *(++rPC) r0 |= *(++rPC) << 16 ip = rINST & 255; pc = rIBASE + ip * 64
const/string
string是一个java.lang.String对象,需要从解析表中获取,代码如下:.balign 64 .L_OP_CONST_STRING: /* 0x1a */ /* File: armv5te/OP_CONST_STRING.S */ /* const/string vAA, String@BBBB */ FETCH(r1, 1) @ r1<- BBBB ldr r2, [rSELF, #offThread_methodClassDex] @ r2<- self->methodClassDex mov r9, rINST, lsr #8 @ r9<- AA ldr r2, [r2, #offDvmDex_pResStrings] @ r2<- dvmDex->pResStrings ldr r0, [r2, r1, lsl #2] @ r0<- pResStrings[BBBB] cmp r0, #0 @ not yet resolved? beq .LOP_CONST_STRING_resolve FETCH_ADVANCE_INST(2) @ advance rPC, load rINST SET_VREG(r0, r9) @ vAA<- r0 GET_INST_OPCODE(ip) @ extract opcode from rINST GOTO_OPCODE(ip) @ jump to next instruction
如果DvmDex的pResStrings已经有解析好的stirng对象,直接取出,否则就调用dvmResolveString来解析。dvmResolveString函数会解析出字符串后再把他们添加到DvmDex的pResStrings中去,下次使用时,就不必再次解析了。
在这里,指令里面包含了字符串的string ID,通过该ID来解析字符串。
const/class
该指令是获取一个class对象,然后写入到指定的虚拟寄存器中/* ------------------------------ */ .balign 64 .L_OP_CONST_CLASS: /* 0x1c */ /* File: armv5te/OP_CONST_CLASS.S */ /* const/class vAA, Class@BBBB */ FETCH(r1, 1) @ r1<- BBBB ldr r2, [rSELF, #offThread_methodClassDex] @ r2<- self->methodClassDex mov r9, rINST, lsr #8 @ r9<- AA ldr r2, [r2, #offDvmDex_pResClasses] @ r2<- dvmDex->pResClasses ldr r0, [r2, r1, lsl #2] @ r0<- pResClasses[BBBB] cmp r0, #0 @ not yet resolved? beq .LOP_CONST_CLASS_resolve FETCH_ADVANCE_INST(2) @ advance rPC, load rINST SET_VREG(r0, r9) @ vAA<- r0 GET_INST_OPCODE(ip) @ extract opcode from rINST GOTO_OPCODE(ip) @ jump to next instruction
实现同string非常相似,主要不同在于它调用了dvmResolveClass来解析。
mov指令
mov指令按照不同字宽,包括mov, mov/from16, mov/16, mov/wide, mov/wide16,mov/object, mov/from_object, mov/result, mov/result_wide,mov/exception等。根据名字,我们就大概知道其功能了。其中mov/result, mov/result_wide,是从Thread.retal中读取对应的值。当return时,解释器会将函数结果存储在Thread::retval变量中。
还是看看mov的例子吧
/* ------------------------------ */ .balign 64 .L_OP_MOVE: /* 0x01 */ /* File: armv6t2/OP_MOVE.S */ /* for move, move-object, long-to-int */ /* op vA, vB */ mov r1, rINST, lsr #12 @ r1<- B from 15:12 ubfx r0, rINST, #8, #4 @ r0<- A from 11:8 FETCH_ADVANCE_INST(1) @ advance rPC, load rINST GET_VREG(r2, r1) @ r2<- fp[B] GET_INST_OPCODE(ip) @ ip<- opcode from rINST SET_VREG(r2, r0) @ fp[A]<- r2 GOTO_OPCODE(ip) @ execute next instruction实际要达到的效果是 fp[A] = fp[B],fp的地址放在rFP寄存器中。
get/put指令
java中对field的读,对应的是get指令,写,对应的是put指令。get/put分sget/sput和iget/iput。's'表示static即对静态field的读写,'i'表示instance,对对象field的读写。按照数据类型不同,分为iget, iget/wide,iget/object,iget/byte, iget/short,等等。每种get和put都是这样。我们只要看看iget就知道他们的大致写法了
/* ------------------------------ */ .balign 64 .L_OP_IGET: /* 0x52 */ /* File: armv6t2/OP_IGET.S */ /* * General 32-bit instance field get. * * for: iget, iget-object, iget-boolean, iget-byte, iget-char, iget-short */ /* op vA, vB, field@CCCC */ mov r0, rINST, lsr #12 @ r0<- B ldr r3, [rSELF, #offThread_methodClassDex] @ r3<- DvmDex FETCH(r1, 1) @ r1<- field ref CCCC ldr r2, [r3, #offDvmDex_pResFields] @ r2<- pDvmDex->pResFields GET_VREG(r9, r0) @ r9<- fp[B], the object pointer ldr r0, [r2, r1, lsl #2] @ r0<- resolved InstField ptr cmp r0, #0 @ is resolved entry null? bne .LOP_IGET_finish @ no, already resolved 8: ldr r2, [rSELF, #offThread_method] @ r2<- current method EXPORT_PC() @ resolve() could throw ldr r0, [r2, #offMethod_clazz] @ r0<- method->clazz bl dvmResolveInstField @ r0<- resolved InstField ptr cmp r0, #0 bne .LOP_IGET_finish b common_exceptionThrown
field的索引保存在CCCC部分,一个字母表示4位。CCCC最大值是65535。
如果field没有解析,还需有调用dvmResolveInstField先解析他,然后在继续运行。由于iget指令需要的代码数超出了64字节,因此用.LOP_IGET_FINISH完成剩余的工作。
INVOKE指令的分析
INVOKE指令是其中比较复杂的指令,它按照参数,可以分成RANGE和不带RANGE的,区别在于用于传递参数的寄存器是否是一个范围;按照类型可以分为: INVOKE_STATIC/DIRECT/VIRTUAL/INTERFACE/SUPER这几种。其中static, direct, native函数都是非常接近的。它们的主要不同,在于获取被调用method的方法不同。
对于DVM来说,要invoke一个方法,需要经历3个步骤:
取得method
准备参数
准备栈结构
最后跳转到第一条指令并执行
取得method
按照不同的method类型,获取method的方法也不一样direct/static
这3类结构是一样的,即在dalvik字节码中,保存的都是被调用函数的索引字节码的形式是
/* op vB, {vD, vE, vF, vG, vA}, class@CCCC */
/* op {vCCCC..v(CCCC+AA-1)}, meth@BBBB */其中class@CCCC或者meth@BBBB表示的就是method的索引。用伪码表示就是
if (!self->pDvmDex->pResMethods[BBBB]) {
dvmResolveMethod(class, BBBB, MEHOD_DIRECT);
}
....这是最简单的形式
virtual/super
根据不同的this的类型,获取的method对象也不一样,所以,它必须先取得method对象的methodIdx,然后再从对象的class的vtable中取得真正的method,才能得到正确的method对象。用伪代码表示就是/* op vB, {vD, vE, vF, vG, vA}, class@CCCC */
mth = self->pDvmDex->pResMethods[CCCC];
if (mth == NULL) {
mth = dvmResoleMethod(self->inpterState.method->clazz, BBBB, METHOD_VIRTUAL);
}
int mthidx = mth->methodIndex;
mth = this->clazz->vtable[mthidx];super的实现与virtual很类似,所不同的是,对于super,需要从this->clazz->super->vtable中获取method。
interface
interface method的获取与其他method有很大的不同。在dalvik指令中,给出的method@BBBB这样的id,实际上指向的是interface的method,而我们执行时,需要获取的,却是this所属的class的对应的method。完成这个过程,是通过函数dvmFindInterfaceMethodInCache来实现的。dvmFindInterfaceMethodInCache->dvmInterpFindInterfaceMethod,他们将解析出的真正method缓存起来,用hash表将interface method,class与对应的真实method关联起来。
首先,我们看看,如何从ineterface的method找到implements class的method。
[b]从ineterface的method找到implements class的method
该功能由函数dvmInterpFindInterfaceMethod来实现的。这个算法的核心是InterfaceEntry结构。每个class都有这样一个结构,叫做iftable。iftable是一个InterfaceEntry结构的数组。这个结构如下:
/*
* Used for iftable in ClassObject.
*/
struct InterfaceEntry {
/* pointer to interface class */
ClassObject* clazz;
/*
* Index into array of vtable offsets. This points into the ifviPool,
* which holds the vtables for all interfaces declared by this class.
*/
int* methodIndexArray;
};clazz:成员指定了当前一个class implememts其中的一个interface的clazz对象
methodIndexArray:interface的method在implements类中的对应的implement method在vtable中的索引
下面的源代码给出了基本的实现:
/*
* Find the concrete method that corresponds to "methodIdx". The code in
* "method" is executing invoke-method with "thisClass" as its first argument.
*
* Returns NULL with an exception raised on failure.
*/
Method* dvmInterpFindInterfaceMethod(ClassObject* thisClass, u4 methodIdx,
const Method* method, DvmDex* methodClassDex)
{
Method* absMethod;
Method* methodToCall;
int i, vtableIndex;
/*
* Resolve the method. This gives us the abstract method from the
* interface class declaration.
*/
absMethod = dvmDexGetResolvedMethod(methodClassDex, methodIdx);
....
/* 找出来对应的iftable */
for (i = 0; i < thisClass->iftableCount; i++) {
if (thisClass->iftable[i].clazz == absMethod->clazz)
break;
}
.....
/*用methodIndex得到vtableIndex */
vtableIndex =
thisClass->iftable[i].methodIndexArray[absMethod->methodIndex];
assert(vtableIndex >= 0 && vtableIndex < thisClass->vtableCount);
methodToCall = thisClass->vtable[vtableIndex];
......
return methodToCall;
}cache的结构和存储方法
每次都需要resolve interface method和一个for循环来查找InterfaceEntry结构,效率很低,于是,dvm引入了一个hash表来解决这个问题。
cache的定义通过宏ATOMIC_CACHE_LOOKUP来实现。
hash表的定义在Thread::pDevDex::pInterfaceCache。这个数据是AtomicCache结构,这个结构是一个带有线程同步的cache结构。其中thisClass和methodId作为hash key,用于快速查找数据的实现。进一步的信息可以查看宏ATOMIC_CACHE_LOOKUP
准备参数
按照是否是rang,分为common_invokeMethodNoRange和common_invokeMethodRange两个标签。这两个标签的功能都是为了拷贝参数,只是实现方法上有不同。要拷贝参数,都分成两个步骤分配"outs"空间
执行参数拷贝
看下分配"outs"空间部分
@ prepare to copy args to "outs" area of current frame movs r2, rINST, lsr #12 @ r2<- B (arg count) -- test for zero SAVEAREA_FROM_FP(r10, rFP) @ r10<- stack save area FETCH(r1, 2) @ r1<- GFED (load here to hide latency) beq .LinvokeArgsDone首先,令r2 = arg_count, 然后取得r10 = rFP - sizeof(StackSaveArea)。然后将参数依次填充到r10之前的内存中去。这里,r10每次要-4.
我将汇编与伪代码对照起来,就是
.LinvokeNonRange:
rsb r2, r2, #5 @ r2<- 5-r2 | r2 = 5-r2
add pc, pc, r2, lsl #4 @ computed goto, 4 instrs each | switch(r2) {
bl common_abort @ (skipped due to ARM prefetch) |
5: and ip, rINST, #0x0f00 @ isolate A | case 0:
ldr r2, [rFP, ip, lsr #6] @ r2<- vA (shift right 8, left 2) | ip = rINST & 0x0f00; //vA
mov r0, r0 @ nop | r2 = *(rFP + (ip >> 6))
str r2, [r10, #-4]! @ *--outs = vA | *(r10 - 4) = r2; r10 -= 4;
4: and ip, r1, #0xf000 @ isolate G | case 1:
ldr r2, [rFP, ip, lsr #10] @ r2<- vG (shift right 12, left 2) | ip = r1 & 0xf0000; //vG
mov r0, r0 @ nop | r2 = *(rFP + (ip >> 10));
str r2, [r10, #-4]! @ *--outs = vG | *(r10 - 4) = r2; r10 -= 4;
3: and ip, r1, #0x0f00 @ isolate F | case 2:
ldr r2, [rFP, ip, lsr #6] @ r2<- vF | ip = r1 & 0x0f00
mov r0, r0 @ nop | r2 = *(rFP + (ip >> 6));
str r2, [r10, #-4]! @ *--outs = vF | *(r10 - 4) = r2; r10 -= 4;
2: and ip, r1, #0x00f0 @ isolate E | case 3:
ldr r2, [rFP, ip, lsr #2] @ r2<- vE | ip = r1 & 0x00f0;
mov r0, r0 @ nop | r2 = *(rFP + (ip >> 2));
str r2, [r10, #-4]! @ *--outs = vE | *(r10 - 4) = r2; r10 -= 4;
1: and ip, r1, #0x000f @ isolate D | case 4:
ldr r2, [rFP, ip, lsl #2] @ r2<- vD | ip = r1 & 0x000f;
mov r0, r0 @ nop | r2 = *(rFP + (ip << 2));
str r2, [r10, #-4]! @ *--outs = vD | *(r10 - 4) = r2; r10 -= 4; }dvm用了一个小技巧:
add pc, pc, r2, lsl #4巧妙的跳转到指定的位置,以便隔去那些不需要处理的分支。
准备栈结构
准备栈部分的代码如下: (删除部分关系不大的代码)
.LinvokeArgsDone: @ r0=methodToCall ldrh r9, [r0, #offMethod_registersSize] @ r9<- methodToCall->regsSize ldrh r3, [r0, #offMethod_outsSize] @ r3<- methodToCall->outsSize ldr r2, [r0, #offMethod_insns] @ r2<- method->insns ldr rINST, [r0, #offMethod_clazz] @ rINST<- method->clazz @ find space for the new stack frame, check for overflow SAVEAREA_FROM_FP(r1, rFP) @ r1<- stack save area sub r1, r1, r9, lsl #2 @ r1<- newFp (old savearea - regsSize) SAVEAREA_FROM_FP(r10, r1) @ r10<- newSaveArea @ bl common_dumpRegs ldr r9, [rSELF, #offThread_interpStackEnd] @ r9<- interpStackEnd sub r3, r10, r3, lsl #2 @ r3<- bottom (newsave - outsSize) cmp r3, r9 @ bottom < interpStackEnd? ldrh lr, [rSELF, #offThread_subMode] ldr r3, [r0, #offMethod_accessFlags] @ r3<- methodToCall->accessFlags blo .LstackOverflow @ yes, this frame will overflow stack @ set up newSaveArea .... str rFP, [r10, #offStackSaveArea_prevFrame] str rPC, [r10, #offStackSaveArea_savedPc] <pre name="code" class="cpp" style="font-size: 13.3333339691162px;">1: tst r3, #ACC_NATIVE bne .LinvokeNative ...... ldrh r9, [r2] @ r9 <- load INST from new PC ldr r3, [rINST, #offClassObject_pDvmDex] @ r3<- method->clazz->pDvmDex mov rPC, r2 @ publish new rPC @ Update state values for the new method @ r0=methodToCall, r1=newFp, r3=newMethodClass, r9=newINST str r0, [rSELF, #offThread_method] @ self->method = methodToCall str r3, [rSELF, #offThread_methodClassDex] @ self->methodClassDex = ... ..... mov rFP, r1 @ fp = newFp GET_PREFETCHED_OPCODE(ip, r9) @ extract prefetched opcode from r9 mov rINST, r9 @ publish new rINST str r1, [rSELF, #offThread_curFrame] @ curFrame = newFp GOTO_OPCODE(ip) @ jump to next instruction ....
还是用r10来做临时变量,可以看到,伪代码是这样的
r9 = method->registerSize; r2 = method->insns; //code的入口地址 r1 = rFP - sizeof(StackSaveArea); r1 = r1 - r9 * 4; r10 = r1 - sizeof(StackSaveArea); r10->prevFrame = rFP; r10->savedPc = rPC; r9 = *r2; rPc = r9; //即 *method->insns; 第一条指令 rSELF->method = r0; //method to call rSELF->pDvmDex = method_to_call->clazz->pDvmDex; //需要切换pDvmDex为当前调用函数的pDvmDex,否则很多解析表获取会出错 rFP = r1; //新的frame地址 ip = r9 & 0xff; //取得第一条指令的opcode rINST = r9; pc = curHandleTable[ip *64]; //完成跳转
对于native函数的调用,我们将在另外文章中详细描述。
异常处理
抛出异常
异常分为两种,一种是系统运行中,由系统产生的异常,一种是throw指令产生的异常。对于系统产生的异常,比如解析错误等,由内部函数dvmThrowException或者其包装函数产生。dvmThrowException->dvmThrowChainedException,该函数的基本功能很简单,即创建一个exception对象,然后赋值给Thread::exception成员。这就完成了异常的抛出工作。
对于用户用throw指令抛出的异常,则也是将异常赋值给Thread::exception成员。异常的创建则是由new-instance指令来完成的,而throw指令只负责把对应的exception放入到Thread::exception变量中。
处理异常
异常的处理是紧随者异常抛出的。通常,throw指令在设置完self->exception后,就会调用common_exceptionThrown这个标签,而对于系统异常,如dvmResolveClass函数调用完成后,只要判断返回值是否成功,如果失败,就直接跳转到common_exceptionThrown,去处理异常。当异常发生时,当前程序流程要立即中断,然后进入到catch和finally块进行处理,这些都是由common_excetptionThrown完成的。
为了方便理解,我直接将其转为伪代码,有兴趣的同学可以看源码(common_exceptionThrown标签的内容)
<span style="font-family:microsoft yahei;"><span style="white-space: pre-wrap;">exception = self->exception;
dvmAddTrackedAlloc(self, exception); //防止GC回收正在处理的exception对象
self->exception = NULL; //情况异常
void *newFP;
ret = dvmFindCatchBlock(self, rPc - self->method->insns, exception, 0, &newFP);
if (self->stackOverflowed) {
dvmCleanupStackOverflow(self, exception);
}
rFP = newFP;
if (ret != 0) //catch到了
{
</span></span> method = (rFP - sizeof(StackSaveArea))->method;
self->method = method;
rPC = method->insns + ret * 2; //指令入口
dvmReleaseTrackedAlloc(exception, self);
rIBASE = self->curHandlerTable;
rINST = *rPC & 0xffff;
ip = rINST & 0xff; //取得opcode
pc = rIBASE + ip * 64;
<span style="font-family: 'microsoft yahei'; white-space: pre-wrap;">} else { //没有catch到
//进一步抛出异常
}</span>dvmFindCatchBlock是整个处理过程的核心,它返回catch(包括finally的处理地址和所在frame的地址。有了这两个信息后,dvm就能重建frame并跳转了。
我们知道,frame上有StackSaveArea,该结构保存了prevFrame和savedPc两个重要成员。prevFrame能让我们遍历整个数据栈,一直遇到一个BreakSaveArea。因为异常的处理不能跨越native函数,即如果A->nativeB->C->D,如果D发生异常,那么遍历到nativeB后就要停止,返回到nativeB函数,让nativeB函数去处理异常,或者继续抛出给A函数处理。
每个method的代码中都包含了catch信息,catch信息由(excetpion, startAddr,code-length, handle addr)组成,只要判断savedPc是否在startAddr和code-length中间,就能知道catch是否找到了。这个由函数dvmFindCatchBlock实现。

相关文章推荐
- QT之文件对话框
- 隐马尔科夫模型(HMMs)之三:隐马尔科夫模型
- oracle创建表副本
- linux
- iOS中UIWebView的使用详解
- oracle不能导出空的表
- PHP工程师面试常见问题
- spark MetaException(message:Version information not found in metastore. )
- C语言 goto void extern sizeof enum typedef分析
- mysql 行列转换
- Python方法完成农历日历功能代码
- badhair_纪中1264_乱搞
- JAVA多线程和并发基础面试
- iptables练习
- 最近的思考
- STL之Vector(二):Vector常用函数
- 互联网数据库架构设计思路
- EventBus 3 [
- 写给刚接触c/c++语言的新人。
- RMQ+二分——GCD ( HDU 5726 ) ( 2016 Multi-University Training Contest 1 1004 )