spark sql thrift server搭建及踩过的坑
2016-07-23 21:02
423 查看
如何配置
配置hadoop和yarn配置HADOOP_CONF_DIR
copy
hive-site.xml到 spark_home/conf
在spark_env.sh中配置mysql的路径
如何启动
./start-thriftserver.sh \–name olap.thriftserver \
–master yarn-client \
–queue bi \
–conf spark.driver.memory=3G \
–conf spark.shuffle.service.enabled=true \
–conf spark.dynamicAllocation.enabled=true \
–conf spark.dynamicAllocation.minExecutors=1 \
–conf spark.dynamicAllocation.maxExecutors=30 \
–conf spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=5s \
–jars /usr/local/spark-1.6.1-bin-hadoop2.6/lib/*
如何使用
shell进入beeline!connect jdbc:hive2://storage8.test.lan:10000
输入
hive-site.xml中的
javax.jdo.option.ConnectionUserName和
javax.jdo.option.ConnextionPassWord
hive的hbase外部表问题
很多文档中都没提到一个jar,这下坑惨了,大部分文档提到了以下jar:hbase-client-0.98.18-hadoop2.jar
hbase-common-0.98.18-hadoop2.jar
hbase-server-0.98.18-hadoop2.jar
hbase-protocol-0.98.18-hadoop2.jar
protobuf-java-2.5.0.jar
guava-12.0.1.jar
/hive-hbase-handler-1.2.1.jar
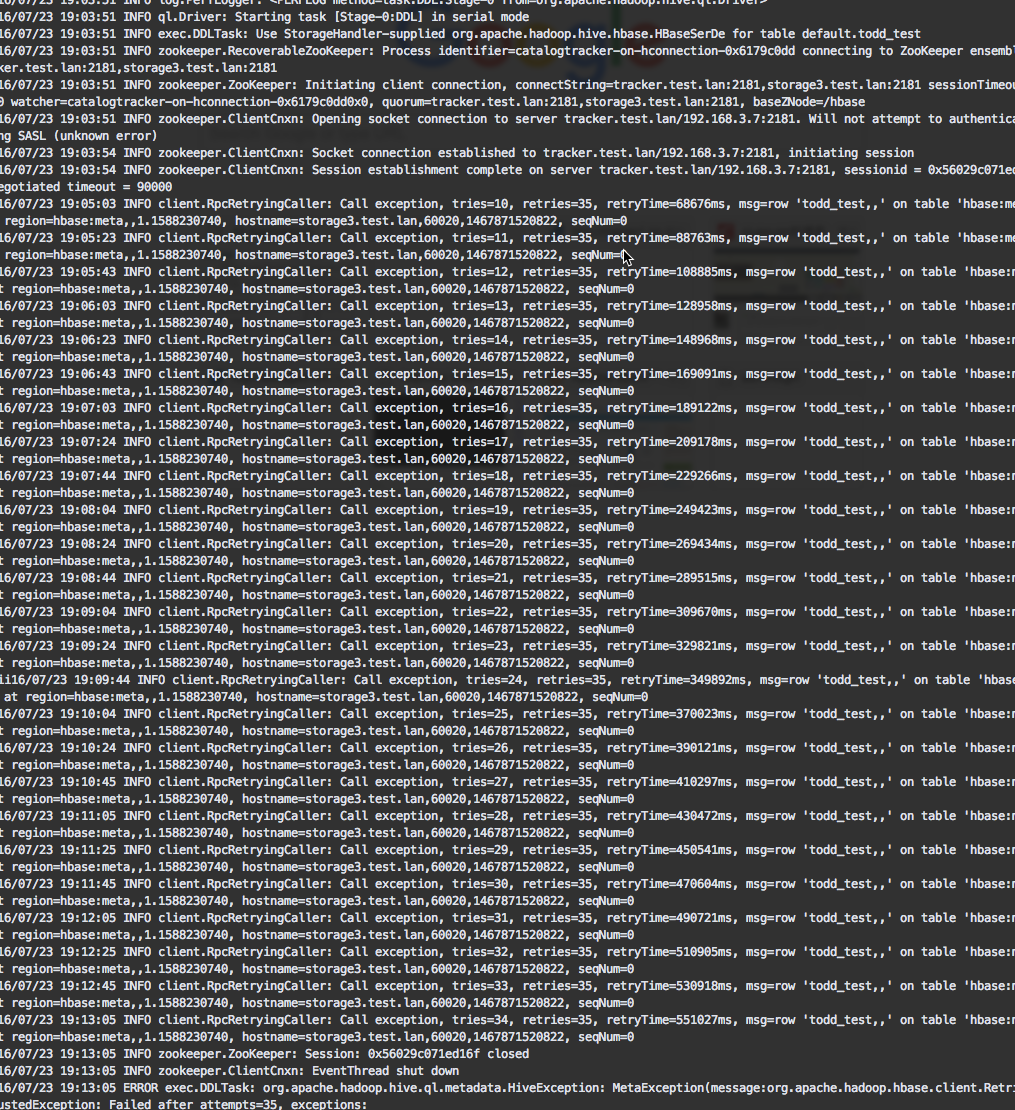
但是hbase坑爹的在35次retry之后抛出了一个
ClassNotFind,时间长达7分钟我也是醉了,后面根据报错加了一个监控的jar,正常运行,最后给出我的配置的
spark-env,sh:
export SPARK_CLASSPATH=$SPARK_HOME/lib/mysql-connector-java-5.1.38.jar:$SPARK_HOME/lib/hbase-server-0.98.18-hadoop2.jar:$SPARK_HOME/lib/hbase-common-0.98.18-hadoop2.jar:$SPARK_HOME/lib/hbase-client-0.98.18-hadoop2.jar:$SPARK_HOME/lib/hbase-protocol-0.98.18-hadoop2.jar:$SPARK_HOME/lib/htrace-core-2.04.jar:$SPARK_HOME/lib/protobuf-java-2.5.0.jar:$SPARK_HOME/lib/guava-12.0.1.jar:$SPARK_HOME/lib/hive-hbase-handler-1.2.1-xima.jar:$SPARK_HOME/lib/com.yammer.metrics.metrics-core-2.2.0.jar:${SPARK_CLASSPATH}另一个hive启动的问题
我们会发现hive每次启动最终都用derby数据库,网上看hive.metastore.schema.verification in hive-site.xml改为false,取消check schema,参考资料,但我们不想改配置,后来 跟了下源码貌似少初始化了一个类,所以我们现在先保证当前ClassLoad里面有这个类:package com.ximalaya.spark.thriftserver
import org.apache.hive.service.server.HiveServer2
/**
* @author todd.chen at 7/23/16 8:49 PM.
* email : todd.chen@ximalaya.com
*/
object XimaThriftServer {
def main(args: Array[String]): Unit = {
Class.forName("org.apache.hadoop.hive.ql.metadata.Hive")
HiveServer2.main(args)
}
}然后改一下
start-thriftserver.sh:
#!/usr/bin/env bash # # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # # # Shell script for starting the Spark SQL Thrift server # Enter posix mode for bash set -o posix if [ -z "${SPARK_HOME}" ]; then export SPARK_HOME="$(cd "`dirname "$0"`"/..; pwd)" fi # NOTE: This exact class name is matched downstream by SparkSubmit. # Any changes need to be reflected there. CLASS="com.ximalaya.spark.thriftserver.XimaSparkThriftServer" function usage { echo "Usage: ./sbin/start-thriftserver [options] [thrift server options]" pattern="usage" pattern+="\|Spark assembly has been built with Hive" pattern+="\|NOTE: SPARK_PREPEND_CLASSES is set" pattern+="\|Spark Command: " pattern+="\|=======" pattern+="\|--help" "${SPARK_HOME}"/bin/spark-submit --help 2>&1 | grep -v Usage 1>&2 echo echo "Thrift server options:" "${SPARK_HOME}"/bin/spark-class $CLASS --help 2>&1 | grep -v "$pattern" 1>&2 } if [[ "$@" = *--help ]] || [[ "$@" = *-h ]]; then usage exit 0 fi export SUBMIT_USAGE_FUNCTION=usage exec "${SPARK_HOME}"/sbin/spark-daemon.sh submit $CLASS 1 "$@"
好了,正常使用了

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- Spark随谈——开发指南(译)
- 单机版搭建Hadoop环境图文教程详解
- Spark,一种快速数据分析替代方案
- hadoop常见错误以及处理方法详解
- hadoop 单机安装配置教程
- hadoop的hdfs文件操作实现上传文件到hdfs
- hadoop实现grep示例分享
- Apache Hadoop版本详解
- linux下搭建hadoop环境步骤分享
- hadoop client与datanode的通信协议分析
- hadoop中一些常用的命令介绍
- Hadoop单机版和全分布式(集群)安装
- 用PHP和Shell写Hadoop的MapReduce程序
- hadoop map-reduce中的文件并发操作
- Hadoop1.2中配置伪分布式的实例