Spark钨丝计划:让火花(Spark)更接近灯丝(Rare Metal)详解(2)
2016-07-23 12:20
471 查看
本文主要内容包括 : “钨丝计划”的shuffle的使用
一:使用Tungsten功能
1, 如果想让您的程序使用Tungsten的功能,可以配置:
Spark.Shuffle.Manager = tungsten-sort
2, DataFrame中自动开启了Tungsten功能。
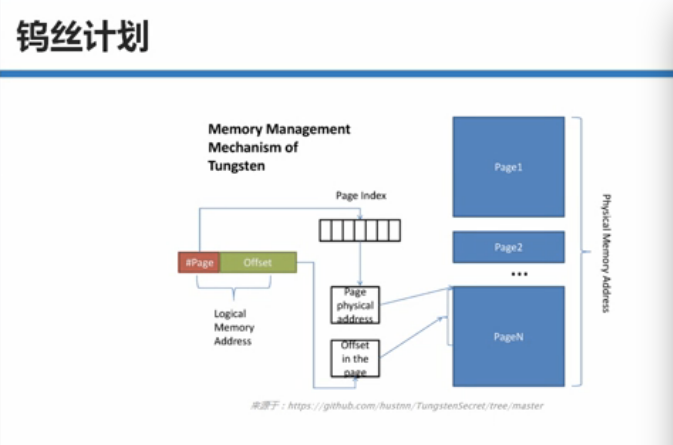
二:Tungsten-sort base Shuffle writer内幕
1,写数据在内存足够大的情况下是写到Page里面,在Page里面有一条条的Record,如果内存不够的话,会spill到磁盘上,输入数据的时候是循环每个Task中处理的数据Partition的结果,循环的时候会查看是否有内存,一个Page写满之后,才会写下一个Page。
2,如何看内存是否足够呢?
a)系统默认情况下给 shuffleMapTask 最大准备了多少内存空间,默认情况下是ExecutorHeapMemory*0.8*0.2 (spark.shuffle.memoryFraction = 0.2 , spark.shuffle.safeFraction = 0.8)
b)另外一方面是和Task处理的Partition大小紧密相关
写入的过程图:
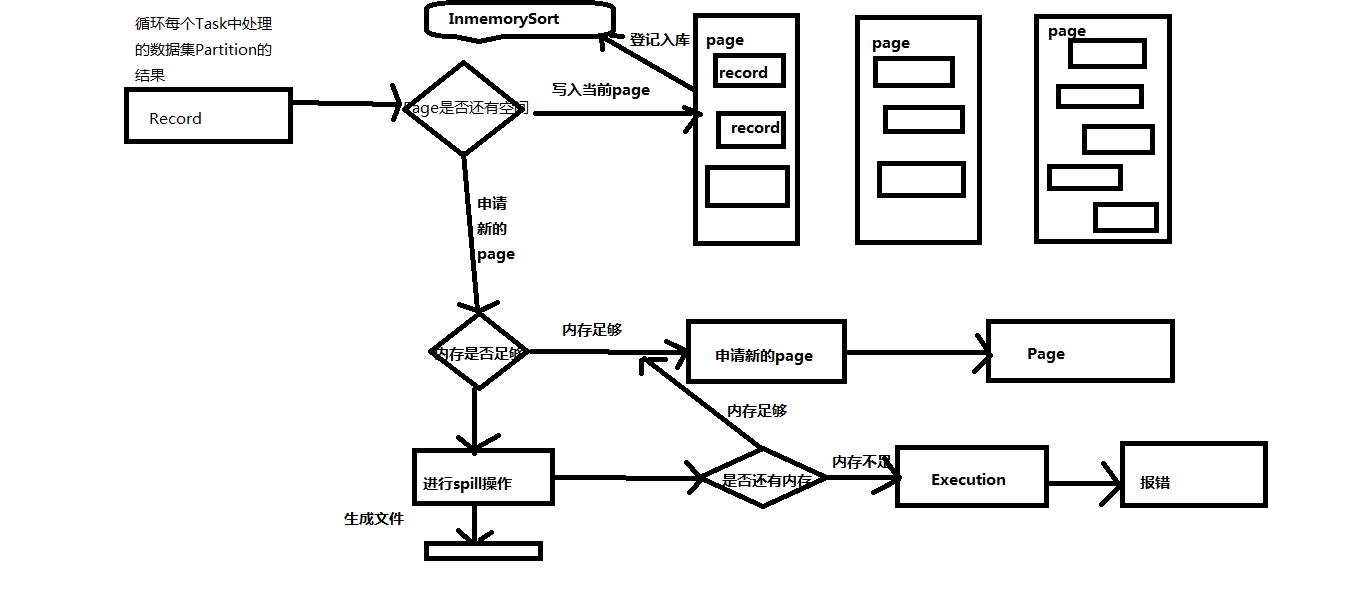
1,mergeSpills的功能是将很多小文件合并成一个大文件。然后加上index文件索引。
2,和Sort Based Shuffle 过程基本一样。
3, 写数据在内存足够大的情况下是写到Page里面,在Page中有一条条的Record,如果内存不够的话会Spill到磁盘中。此过程跟前面讲解Sort base Shuffle writer过程是一样的。
4,基于UnsafeShuffleWriter会有一个类负责将数据写入到Page中。
5, insertRecordIntoSorter: 此方法把records的数据一条一条的写入到输出流。
而输出流是: ByteArrayOutputStream
四:Tungsten-sort base Shuffle Read原理
基本上是复用了Hash Shuffle Read, 在Tungsten下获取数据的类叫做BlockStoreShuffleReader,其底层其实是Pag
一:使用Tungsten功能
1, 如果想让您的程序使用Tungsten的功能,可以配置:
Spark.Shuffle.Manager = tungsten-sort
2, DataFrame中自动开启了Tungsten功能。
二:Tungsten-sort base Shuffle writer内幕
1,写数据在内存足够大的情况下是写到Page里面,在Page里面有一条条的Record,如果内存不够的话,会spill到磁盘上,输入数据的时候是循环每个Task中处理的数据Partition的结果,循环的时候会查看是否有内存,一个Page写满之后,才会写下一个Page。
2,如何看内存是否足够呢?
a)系统默认情况下给 shuffleMapTask 最大准备了多少内存空间,默认情况下是ExecutorHeapMemory*0.8*0.2 (spark.shuffle.memoryFraction = 0.2 , spark.shuffle.safeFraction = 0.8)
b)另外一方面是和Task处理的Partition大小紧密相关
写入的过程图:
1,mergeSpills的功能是将很多小文件合并成一个大文件。然后加上index文件索引。
2,和Sort Based Shuffle 过程基本一样。
3, 写数据在内存足够大的情况下是写到Page里面,在Page中有一条条的Record,如果内存不够的话会Spill到磁盘中。此过程跟前面讲解Sort base Shuffle writer过程是一样的。
4,基于UnsafeShuffleWriter会有一个类负责将数据写入到Page中。
5, insertRecordIntoSorter: 此方法把records的数据一条一条的写入到输出流。
而输出流是: ByteArrayOutputStream
四:Tungsten-sort base Shuffle Read原理
基本上是复用了Hash Shuffle Read, 在Tungsten下获取数据的类叫做BlockStoreShuffleReader,其底层其实是Pag

相关文章推荐
- VS2010把项目发布、打包成可安装部署的应用程序
- 线程的创建
- 编程思想之多线程与多进程(1)——以操作系统的角度述说线程与进程
- 进程间通信——消息队列
- Angular2 开发规范
- codeforces 701B B. Cells Not Under Attack(水题)
- linphone-LinphoneAuthInfo.java
- Brupsuite暴力破解DVWA渗透平台
- 类成员的3种访问属性 类的3种继承方式(继承性也叫派生性)
- 线程上下文切换和进程上下文切换的区别
- 使用PUTTY连接虚拟机Ubuntu16.04
- POJ:3641 Pseudoprime numbers(快速幂)
- python数据持久存储:pickle模块的基本使用
- J2EE基础之Web服务简介
- Linux关机命令
- CSS样式设置小技巧
- codeforces 701A A. Cards(水题)
- CodeForces 699B——One Bomb(预处理,暴力枚举)
- opencv提取直线、轮廓及ROI的描述方法
- 开机导入Sim卡联系人流程分析