Oracle 12c 和 Hadoop:大数据的最佳存储和处理办法
2016-07-22 15:41
731 查看
Oracle 12c 和 Hadoop:大数据的最佳存储和处理办法
本文演示如何使用 Hadoop 生态系统工具从 Oracle 12c 数据库提取数据,使用 Hadoop 框架处理和转换数据,然后将在 Hadoop 中处理的数据加载到 Oracle 12c 数据库中。
本文介绍三个基本概念:
大数据是什么?大数据是一台计算机无法存储和处理的数据量。数据来源不同,格式不同(结构化和非结构化),增长速度极快。
Apache Hadoop 是什么?它是一个框架,允许分布式处理多台(可以达数千台)计算机上的大数据集。Hadoop 概念首先由 Google 引入。Hadoop 框架由 HDFS 和 MapReduce 组成。
HDFS 是什么? HDFS(Hadoop 分布式文件系统):支持跨多台计算机存储大数据集的 Hadoop 文件系统。
Map Reduce 是什么?它是 Hadoop 框架的数据处理组件,由“映射”阶段和“归约”阶段组成。
Apache Sqoop 是什么? Apache Sqoop(TM) 是一种在 Apache Hadoop 和结构化数据存储(如关系数据库)之间传输批量数据的工具。它是 Hadoop 生态系统的一部分。
Apache Hive 是什么? Hive 是一种查询和管理 Hadoop HDFS 中存储的大数据集的工具。它也是 Hadoop 生态系统的一部分。
Hadoop 适用于何处?在下面的文章中,我们将使用 Apache Hadoop 生态系统 (Apache Sqoop) 从 Oracle 12c 数据库提取数据,并将其存储到 Hadoop 分布式文件系统 (HDFS) 中。然后,我们将使用 Apache Hadoop 生态系统 (Apache Hive) 通过 Map Reduce 转换和处理数据(我们也可使用 Java 程序完成相同操作)。Apache Sqoop 用于将 Hadoop 中已经处理好的数据加载到 Oracle 12c 数据库中。下图描绘了
Hadoop 在流程中的适用位置。该场景表示一个处理来自 Oracle 数据库的大数据的实际解决方案;唯一的条件是数据源必须是结构化的。注意,Hadoop 还可以处理视频、日志文件等非结构化数据。

系统准备
安装 Hadoop 并配置 Cloudera Hadoop:http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/4.2.0/CDH4-Installation-Guide/cdh4ig_topic_4_4.html
安装 Sqoop:有关安装说明,请访问:http://sqoop.apache.org/
安装 Hive:http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH4/4.2.0/CDH4-Installation-Guide/cdh4ig_topic_18_3.html
从 Oracle 网站下载 JDBC 驱动程序:http://www.oracle.com/technetwork/cn/database/database11g/jdbc-112010-094555-zhs.html
将 Oracle 数据库中的数据提取到 HDFS 中:
连接到 Oracle 12cR1 中的可插拔数据库 (PDB):
注:如果您的 Oracle 数据库是 Oracle 12c 第 1 版之前的版本,则不必执行此步骤。在本文中,我们将连接到可插拔数据库。如果要连接到 Oracle 12c 版之前的 Oracle 数据库版本,只需有运行中的数据库服务即可。此步骤也适用于 Real Application Cluster 和 Exadata 环境。
在 Oracle 12cR1 中,可以使用以下四种方式之一连接到可插拔数据库:
使用数据库软件已自动创建的默认服务名称。
使用 SRVCTL 实用程序为 PDB 创建您自己的服务。
发出一条 alter session 命令,例如,ALTER SESSION SET CONTAINER = MYPDB; 将容器设置为 MYPDB 可插拔数据库。
使用 Enterprise Manager 12c 或 Enterprise Manager 12c Express。
为名为“orawiss12c”的可插拔数据库创建一个新服务
sandbox1(orawiss):/home/oracle/wissem>sqlplus / as sysdba
SQL*Plus:Release 12.1.0.1.0 Production on Mon Nov 25 10:57:42 2013
Copyright (c) 1982, 2013, Oracle.All rights reserved.
Connected to:
Oracle Database 12c Enterprise Edition Release 12.1.0.1.0 - 64bit Production
With the Partitioning, Automatic Storage Management, OLAP, Advanced Analytics
and Real Application Testing options
SQL> select con_id,dbid,NAME,OPEN_MODE from v$pdbs;
CON_ID DBID NAME OPEN_MODE
2 4061740350 PDB$SEED READ ONLY
3 1574282659 ORAWISS12C READ WRITE
SQL>
要使用 SRVCTL 实用程序为 PDB 创建服务,请使用 add service 命令并在 -pdb 参数中指定 PDB。
然后启动名为 orawissPDB 的新服务。
sandbox1(+ASM):/home/oracle>srvctl add service -db orawiss -service orawissPDB -pdb orawiss12c
sandbox1(+ASM):/home/oracle>srvctl start service -db orawiss -service orawissPDB
sandbox1(+ASM):/home/oracle>
在 tnsnames.ora 文件中为刚创建的服务 orawissPDB 创建一个条目。
然后测试连接。
sandbox1(+ASM):/home/oracle>cat /opt/app/oracle/product/12.1/db_1/network/admin/tnsnames.ora
orawissPDB =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS =
(PROTOCOL = TCP)(HOST = sandbox1.XXX.com)(PORT = 1522)
)
(CONNECT_DATA =
(SERVICE_NAME = orawissPDB)
)
)
sandbox1(+ASM):/home/oracle>
sandbox1(orawiss):/home/oracle/wissem >sqlplus wissem/wissem@orawissPDB
SQL*Plus:Release 12.1.0.1.0 Production on Mon Nov 25 10:51:24 2013
Copyright (c) 1982, 2013, Oracle.
All rights reserved.
Last Successful login time:Sun Jul 14 2013 05:20:12 -05:00
Connected to:Oracle Database 12c Enterprise Edition Release 12.1.0.1.0 - 64bit Production
With the Partitioning, Automatic Storage Management, OLAP, Advanced Analytics
and Real Application Testing options
SQL> exit
Disconnected from Oracle Database 12c Enterprise Edition Release 12.1.0.1.0 - 64bit Production
With the Partitioning, Automatic Storage Management, OLAP, Advanced Analytics
and Real Application Testing options
sandbox1(orawiss):/home/oracle/wissem/ORAWISS/archivelog>
下载适用于 Oracle 的 JDBC 驱动程序:http://www.oracle.com/technetwork/cn/database/database11g/jdbc-112010-094555-zhs.html。
您必须先接受许可协议,然后才能下载驱动程序。
下载 ojdbc6.jar 文件。
将 ojdbc6.jar 文件复制到 /usr/lib/sqoop/lib/ 目录。运行以下命令:

测试与 Oracle 数据库的连接:我们可以使用 sqoop 测试与 Oracle 数据库的连接。
注:我们将使用 sandbox1 作为安装 Hadoop、Sqoop 和 Hive 的 oracle 数据库服务器和 localhost。通常,您会发现 Hadoop 安装在多台计算机上,而 Sqoop 安装在单独的客户机上。Hive 也可能安装在单独的客户机上。为了简单起见,所有 Hadoop 生态系统和 Hadoop 框架都安装在一台计算机上。

我们从 dual 表中选择 1,Sqoop 返回值 1,这表示已建立与 Oracle 可插拔数据库的连接。
互联网活动用户数据集:
在本例中,网络营销公司为互联网用户提供横幅广告、网页供下载软件、游戏等,每天有来自世界各地的数百万活动用户。Inventory 部门需要知道一个用户每天处于活动状态的次数:活动状态表示用户单击横幅广告、单击优惠或只是登录。为了简单起见,我们假设需要一个 Oracle 表,表中只有两个字段:用户 IP 和活动日期。表中可以有许多其他列,如横幅广告标识符、流量源、国家/地区等等。将表命名为“User_Activity”,每天可能有数十亿条记录。
我们将编写一个挖掘活动用户数据的程序。用户每次在全球多个位置执行“操作”时收集数据。我们可以收集到大量日志数据。数据是结构化的,因此适合由 Oracle 数据库管理。而且用户活动表也很适合用 Map Reduce 分析。目的是了解一个用户每天处于活动状态的次数。
下面将在 Oracle 12c 数据库中创建该表,并填充一些示例数据。
sandbox1(orawiss):/home/oracle/wissem>sqlplus wissem/wissem@orawissPDB
SQL*Plus:Release 12.1.0.1.0 Production on Wed Nov 27 04:43:09 2013
Copyright (c) 1982, 2013, Oracle.All rights reserved.
Last Successful login time:Tue Nov 26 2013 11:26:04 -05:00
Connected to:Oracle Database 12c Enterprise Edition Release 12.1.0.1.0 - 64bit Production
With the Partitioning, Automatic Storage Management, OLAP, Advanced Analytics
and Real Application Testing options
SQL> create table user_activity(IP_ADRR Varchar2(30), ACTIVE_DATE DATE, Traffi_source Varchar2(50),
ISO_COUNTRY Varchar2(2));
Table created.
SQL> ALTER TABLE user_activity ADD PRIMARY KEY (IP_ADRR, ACTIVE_DATE);
Table altered.
SQL> select * from user_activity;
IP_ADRR ACTIVE_DATE TRAFFI_SOURCE IS
------------------ -------------- -------------------------------------------------- --
98.245.153.111 11/27/2013 04:49:14 Google TN
65.245.153.105 11/27/2013 04:49:59 Yahoo BE
98.245.153.111 11/27/2013 04:50:14 MSN TN
98.245.153.111 11/27/2013 04:50:25 MSN TN
98.245.153.111 11/27/2013 04:50:28 MSN TN
98.245.153.111 11/27/2013 04:50:30 MSN TN
65.245.153.105 11/27/2013 04:50:40 Yahoo BE
65.245.153.105 11/27/2013 04:50:41 Yahoo BE
65.245.153.105 11/27/2013 04:50:42 Yahoo BE
……
……
SQL>
将 Oracle 数据库中的数据提取到 HDFS 中:
我们使用 Sqoop 将 Oracle 中的数据导入 HDFS。Sqoop 有从 RDBMS 导入数据的导入选项。我们需要指定连接字符串、表名和字段分隔符。有关 sqoop 导入的更多详细信息,可参见 Sqoop 用户指南。Sqoop 可以并行导入数据。我们可以使用 -m 或 --num-mappers 参数指定用于执行从 Oracle 导入的映射任务(并行进程)数。默认情况下,使用四个任务。在本例中,我们将只使用一个映射器。(rac1)
[wissem@localhost ~]$ sqoop import --connect jdbc:oracle:thin:@//sandbox1.xxx.com:1522/orawissPDB --table
USER_ACTIVITY --fields-terminated-by '\t' --num-mappers 1 --username WISSEM -P
Warning:/usr/lib/hcatalog does not exist!HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Enter password:
13/11/27 14:39:23 INFO manager.SqlManager:Using default fetchSize of 1000
13/11/27 14:39:23 INFO tool.CodeGenTool:Beginning code generation
13/11/27 14:39:26 INFO manager.OracleManager:Time zone has been set to GMT
13/11/27 14:39:27 INFO manager.SqlManager:Executing SQL statement:SELECT t.* FROM USER_ACTIVITY t WHERE 1=0
13/11/27 14:39:27 INFO orm.CompilationManager:HADOOP_MAPRED_HOME is /usr/lib/hadoop-0.20-mapreduce
13/11/27 14:39:27 INFO orm.CompilationManager:Found hadoop core jar at:/usr/lib/hadoop-0.20- mapreduce/hadoop-core.jar Note:/tmp/sqoop-wissem/compile/6a6e927fb008e151d1eeb04bff6f24ef/USER_ACTIVITY.java uses or overrides a deprecated API.Note:Recompile with
-Xlint:deprecation for details.
13/11/27 14:39:30 INFO orm.CompilationManager:Writing jar file:/tmp/sqoop- wissem/compile/6a6e927fb008e151d1eeb04bff6f24ef/USER_ACTIVITY.jar
13/11/27 14:39:30 INFO manager.OracleManager:Time zone has been set to GMT
13/11/27 14:39:34 WARN manager.OracleManager:The table USER_ACTIVITY contains a multi-column primary key.Sqoop will default to the column ACTIVE_DATE only for this job.
13/11/27 14:39:34 INFO manager.OracleManager:Time zone has been set to GMT
13/11/27 14:39:35 WARN manager.OracleManager:The table USER_ACTIVITY contains a multi-column primary key.Sqoop will default to the column IP_ADRR only for this job.
13/11/27 14:39:35 INFO mapreduce.ImportJobBase:Beginning import of USER_ACTIVITY
13/11/27 14:39:36 INFO manager.OracleManager:Time zone has been set to GMT
13/11/27 14:39:37 WARN mapred.JobClient:Use GenericOptionsParser for parsing the arguments.Applications should implement Tool for the same.
13/11/27 14:39:42 INFO mapred.JobClient:Running job:job_201311271428_0001
13/11/27 14:39:43 INFO mapred.JobClient:map 0% reduce 0% 13/11/27 14:40:04 INFO mapred.JobClient:map 100% reduce 0% 13/11/27 14:40:07 INFO mapred.JobClient:Job complete:job_201311271428_0001
13/11/27 14:40:07 INFO mapred.JobClient:Counters:23 13/11/27 14:40:07 INFO mapred.JobClient:File System Counters 13/11/27 14:40:07 INFO mapred.JobClient:FILE:Number of bytes read=0 13/11/27 14:40:07 INFO mapred.JobClient:FILE:Number of bytes written=216292
13/11/27 14:40:07 INFO mapred.JobClient:FILE:Number of read operations=0
13/11/27 14:40:07 INFO mapred.JobClient:FILE:Number of large read operations=0
13/11/27 14:40:07 INFO mapred.JobClient:FILE:Number of write operations=0
13/11/27 14:40:07 INFO mapred.JobClient:HDFS:Number of bytes read=87
13/11/27 14:40:07 INFO mapred.JobClient:HDFS:Number of bytes written=407
13/11/27 14:40:07 INFO mapred.JobClient:HDFS:Number of read operations=1
13/11/27 14:40:07 INFO mapred.JobClient:HDFS:Number of large read operations=0
13/11/27 14:40:07 INFO mapred.JobClient:HDFS:Number of write operations=1
13/11/27 14:40:07 INFO mapred.JobClient:Job Counters
13/11/27 14:40:07 INFO mapred.JobClient:Launched map tasks=1
13/11/27 14:40:07 INFO mapred.JobClient:Total time spent by all maps in occupied slots (ms)=20435
13/11/27 14:40:07 INFO mapred.JobClient:Total time spent by all reduces in occupied slots (ms)=0
13/11/27 14:40:07 INFO mapred.JobClient:Total time spent by all maps waiting after reserving slots (ms)=0
13/11/27 14:40:07 INFO mapred.JobClient:Total time spent by all reduces waiting after reserving slots (ms)=0
13/11/27 14:40:07 INFO mapred.JobClient:Map-Reduce Framework
13/11/27 14:40:07 INFO mapred.JobClient:Map input records=9
13/11/27 14:40:07 INFO mapred.JobClient:Map output records=9
13/11/27 14:40:07 INFO mapred.JobClient:Input split bytes=87
13/11/27 14:40:07 INFO mapred.JobClient:Spilled Records=0
13/11/27 14:40:07 INFO mapred.JobClient:CPU time spent (ms)=1000
13/11/27 14:40:07 INFO mapred.JobClient:Physical memory (bytes) snapshot=60805120
13/11/27 14:40:07 INFO mapred.JobClient:Virtual memory (bytes) snapshot=389214208
13/11/27 14:40:07 INFO mapred.JobClient:Total committed heap usage (bytes)=15990784
13/11/27 14:40:07 INFO mapreduce.ImportJobBase:Transferred 407 bytes in 31.171 seconds (13.057 bytes/sec)
13/11/27 14:40:07 INFO mapreduce.ImportJobBase:Retrieved 9 records.
[wissem@localhost ~]$
Sqoop 使用 Map Reduce 框架(1 个 Mapper 以及对应的 Reducer);Sqoop 自动创建一个名为“USER_ACTIVITY.jar”的 Jar 文件,并使用 Sql 提取 Oracle 数据库中 User Activity 表的内容。HDFS 中的文件命名为 part-m-00000。这是 FileOutputFormat 类中定义的 Hadoop 文件命名规则,且有一个 mapreduce.output.basename 属性。“m”部分表示映射,“r”(如果有归约阶段)只是表示
reducer 的输出。由于我们定义了一个映射,因此只有一个名为 part-m-00000 的输出文件。我们来看看 part-m-00000 的内容,稍后将其重命名为 user_Activity.txt 文件。
[wissem@localhost ~]$ hadoop fs -cat /user/wissem/USER_ACTIVITY/part-m-00000
98.245.153.111 2013-11-27 04:49:14.0 Google TN
65.245.153.105 2013-11-27 04:49:59.0 Yahoo BE
98.245.153.111 2013-11-27 04:50:14.0 MSN TN
98.245.153.111 2013-11-27 04:50:25.0 MSN TN
98.245.153.111 2013-11-27 04:50:28.0 MSN TN
98.245.153.111 2013-11-27 04:50:30.0 MSN TN
65.245.153.105 2013-11-27 04:50:40.0 Yahoo BE
65.245.153.105 2013-11-27 04:50:41.0 Yahoo BE
65.245.153.105 2013-11-27 04:50:42.0 Yahoo BE
[wissem@localhost ~]$
[wissem@localhost ~]$ hadoop fs -mv USER_ACTIVITY/part-m-00000 /user/wissem/USER_ACTIVITY/user_activity.txt [wissem@localhost ~]$ hadoop fs -cat /user/wissem/USER_ACTIVITY/user_activity.txt
98.245.153.111 2013-11-27 04:49:14.0 Google TN
65.245.153.105 2013-11-27 04:49:59.0 Yahoo BE
98.245.153.111 2013-11-27 04:50:14.0 MSN TN
98.245.153.111 2013-11-27 04:50:25.0 MSN TN
98.245.153.111 2013-11-27 04:50:28.0 MSN TN
98.245.153.111 2013-11-27 04:50:30.0 MSN TN
65.245.153.105 2013-11-27 04:50:40.0 Yahoo BE
65.245.153.105 2013-11-27 04:50:41.0 Yahoo BE
65.245.153.105 2013-11-27 04:50:42.0 Yahoo BE
[wissem@localhost ~]$
现在,数据在 Hadoop 分布式文件系统中。下面进行 ETL 过程的第二部分,即转换部分。
Hadoop 中的数据转换:目的是了解用户每天处于活动状态的次数。
此查询可能需要几分钟的时间在 Oracle 数据库上运行。但如果有数万亿条记录,查询需数小时的时间才能开始运行,该怎么办?作为分布式框架,Hadoop 将输出文件存储在不同服务器内的不同 64MB 块(此为默认设置)中。每个节点上将运行 Hadoop Map 程序存储数据,还有一个 reducer 接受映射阶段的排序结果并在 HDFS 中生成输出文件。此过程将保证 Hadoop 框架的每个节点执行较小文件的处理。Hadoop 集群的所有节点并行工作,提供输出文件。我们已经解释了 Hadoop
系统的工作方式。下面对 user_activity.txt 文件运行 Map Reduce 程序。我们可以编写 Java 类执行 Map Reduce 阶段,但 HiveQL(Hive SQL 式语言)也可以完成同样的工作,且无需编写 Java 代码行。首先在 HIVE 中创建一个表,用制表符“\t”作为分隔符。
[wissem@localhost ~]$ hive
Logging initialized using configuration in file:/etc/hive/conf.dist/hive-log4j.properties
Hive history file=/tmp/wissem/hive_job_log_024ccdda-b362-4ef2-9222-2c374dd2ac83_188192255.txt
hive> create table user_Activity (IP_ADRR STRING, ACTIVE_DATE STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;
OK
Time taken:13.84 seconds
hive> show tables user_Activity;
OK
Time taken:0.235 seconds
hive>
我们已在 Hive 中创建了一个表,下面使用本文前一节中从 Oracle 数据库中提取的用户活动数据填充该表。
hive> LOAD DATA INPATH "/user/wissem/USER_ACTIVITY/user_activity.txt" INTO TABLE user_Activity;
Loading data to table default.user_activity
Table default.user_activity stats:[num_partitions:0, num_files:1, num_rows:0, total_size:407, raw_data_size:0]
OK
Time taken:1.318 seconds
hive> select * from user_activity;
OK
98.245.153.111 2013-11-27 04:49:14.0
65.245.153.105 2013-11-27 04:49:59.0
98.245.153.111 2013-11-27 04:50:14.0
98.245.153.111 2013-11-27 04:50:25.0
98.245.153.111 2013-11-27 04:50:28.0
98.245.153.111 2013-11-27 04:50:30.0
65.245.153.105 2013-11-27 04:50:40.0
65.245.153.105 2013-11-27 04:50:41.0
65.245.153.105 2013-11-27 04:50:42.0
Time taken:0.541 seconds
hive>
现在,我们在 HDFS 中处理用户活动数据并输出结果。我们使用 HiveQL 的 insert OVERWRITE 语法。我们将中的输出目录命名为“USER_ACTIVITY_OUT”,如果已经存在,则覆盖它。从 Hive 0.11.0 起,可以指定使用的分隔符,早期版本中的分隔符始终是
^A 字符 (\001)。
hive> INSERT OVERWRITE DIRECTORY 'USER_ACTIVITY_OUT' SELECT COUNT(*), IP_ADRR , SUBSTR(ACTIVE_DATE, 1,
10) FROM USER_ACTIVITY group by IP_ADRR , SUBSTR(ACTIVE_DATE, 1, 10);
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified.Estimated from input data size:1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer= <number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max= <number>
In order to set a constant number of reducers:
set mapred.reduce.tasks= <number>
Starting Job = job_201311271428_0003, Tracking URL = http://localhost:50030/jobdetails.jsp? jobid=job_201311271428_0003 Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_201311271428_0003
Hadoop job information for Stage-1:number of mappers:1; number of reducers:1
2013-11-27 15:32:20,392 Stage-1 map = 0%, reduce = 0%
2013-11-27 15:32:27,475 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.54 sec
2013-11-27 15:32:28,488 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.54 sec
2013-11-27 15:32:29,497 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.54 sec
2013-11-27 15:32:30,526 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.54 sec
2013-11-27 15:32:31,543 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.36 sec
2013-11-27 15:32:32,582 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.36 sec
MapReduce Total cumulative CPU time:4 seconds 360 msec
Ended Job = job_201311271428_0003
Moving data to:USER_ACTIVITY_OUT
2 Rows loaded to USER_ACTIVITY_OUT
MapReduce Jobs Launched:
Job 0:Map:1 Reduce:1 Cumulative CPU:4.36 sec HDFS Read:634 HDFS Write:56 SUCCESS
Total MapReduce CPU Time Spent:4 seconds 360 msec
OK
Time taken:16.466 seconds
hive> quit;
由以上输出可见,我们可以通过以下 URL 监视作业执行:
http://localhost:50030/jobdetails.jsp?jobid=job_201311271428_0003
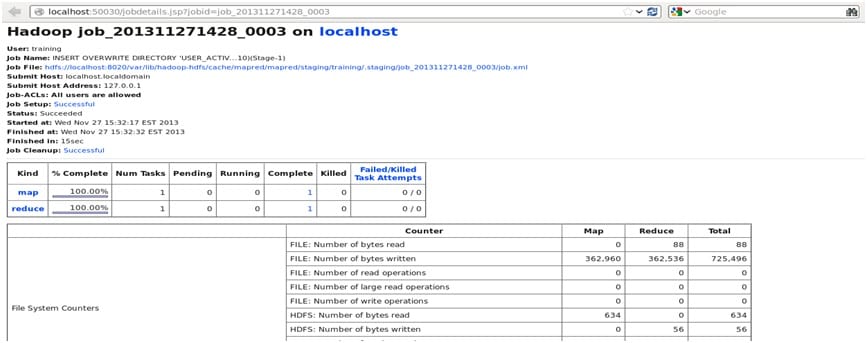
现在,我们可以检查输出文件内容。
[wissem@localhost ~]$ hadoop fs -cat /user/wissem/USER_ACTIVITY_OUT/000000_0
4 65.245.153.105 2013-11-27
5 98.245.153.111 2013-11-27
[wissem@localhost ~]$
将 Hadoop 中的数据加载到 Oracle 数据库中:现在,我们在 Oracle 12c 中创建一个名为 USER_STATS 的表。此表将包含最终的处理过的数据。
SQL> CREATE TABLE USER_STATS (ACTIVES NUMBER,IP_ADRR VARCHAR2(30), ACTIVE_DATE VARCHAR2(10));
Table created.
现在,我们使用 Sqoop 将处理过的数据加载到 Oracle 数据库中。我们使用 Sqoop 的 export 选项。
[wissem@localhost ~]$
sqoop export --connect jdbc:oracle:thin:@//sandbox1.xxx.com:1522/orawissPDB --export- dir '/user/wissem/USER_ACTIVITY_OUT/000000_0' --table WISSEM.USER_STATS --fields-terminated-by '\001'
--input-null-string '\\N' --input-null-non-string '\\N' -m 1 --username WISSEM -P
Warning:/usr/lib/hcatalog does not exist!HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Enter password:
13/11/27 15:36:06 INFO manager.SqlManager:Using default fetchSize of 1000
13/11/27 15:36:06 INFO tool.CodeGenTool:Beginning code generation
13/11/27 15:36:09 INFO manager.OracleManager:Time zone has been set to GMT
13/11/27 15:36:10 INFO manager.SqlManager:Executing SQL statement:SELECT t.* FROM WISSEM.USER_STATS t WHERE 1=0
13/11/27 15:36:11 INFO orm.CompilationManager:HADOOP_MAPRED_HOME is /usr/lib/hadoop-0.20-mapreduce
13/11/27 15:36:11 INFO orm.CompilationManager:Found hadoop core jar at:/usr/lib/hadoop-0.20-mapreduce/ hadoop-core.jar Note:/tmp/sqoop-wissem/compile/e49e98500225d2ef01254258389240fd/WISSEM_USER_STATS.java uses or overrides a deprecated API.
注:Recompile with -Xlint:deprecation for details.
13/11/27 15:36:12 INFO orm.CompilationManager:Writing jar file:/tmp/sqoop-wissem/ compile/e49e98500225d2ef01254258389240fd/WISSEM.USER_STATS.jar
13/11/27 15:36:12 INFO mapreduce.ExportJobBase:Beginning export of WISSEM.USER_STATS
13/11/27 15:36:13 INFO manager.OracleManager:Time zone has been set to GMT
13/11/27 15:36:14 WARN mapred.JobClient:Use GenericOptionsParser for parsing the arguments.Applications should implement Tool for the same.
13/11/27 15:36:15 INFO input.FileInputFormat:Total input paths to process :1
13/11/27 15:36:15 INFO input.FileInputFormat:Total input paths to process :1
13/11/27 15:36:15 INFO mapred.JobClient:Running job:job_201311271428_0004
13/11/27 15:36:16 INFO mapred.JobClient:map 0% reduce 0%
13/11/27 15:36:23 INFO mapred.JobClient:map 100% reduce 0%
13/11/27 15:36:24 INFO mapred.JobClient:Job complete:job_201311271428_0004
13/11/27 15:36:24 INFO mapred.JobClient:Counters:24
13/11/27 15:36:24 INFO mapred.JobClient:File System Counters
13/11/27 15:36:24 INFO mapred.JobClient:FILE:Number of bytes read=0
13/11/27 15:36:24 INFO mapred.JobClient:FILE:Number of bytes written=214755
13/11/27 15:36:24 INFO mapred.JobClient:FILE:Number of read operations=0
13/11/27 15:36:24 INFO mapred.JobClient:FILE:Number of large read operations=0
13/11/27 15:36:24 INFO mapred.JobClient:FILE:Number of write operations=0
13/11/27 15:36:24 INFO mapred.JobClient:HDFS:Number of bytes read=202
13/11/27 15:36:24 INFO mapred.JobClient:HDFS:Number of bytes written=0
13/11/27 15:36:24 INFO mapred.JobClient:HDFS:Number of read operations=4
13/11/27 15:36:24 INFO mapred.JobClient:HDFS:Number of large read operations=0
13/11/27 15:36:24 INFO mapred.JobClient:HDFS:Number of write operations=0
13/11/27 15:36:24 INFO mapred.JobClient:Job Counters 13/11/27 15:36:24 INFO mapred.JobClient:Launched map tasks=1
13/11/27 15:36:24 INFO mapred.JobClient:Data-local map tasks=1
13/11/27 15:36:24 INFO mapred.JobClient:Total time spent by all maps in occupied slots (ms)=7608
13/11/27 15:36:24 INFO mapred.JobClient:Total time spent by all reduces in occupied slots (ms)=0
13/11/27 15:36:24 INFO mapred.JobClient:Total time spent by all maps waiting after reserving slots
(ms)=0
13/11/27 15:36:24 INFO mapred.JobClient:Total time spent by all reduces waiting after reserving slots (ms)=0
13/11/27 15:36:24 INFO mapred.JobClient:Map-Reduce Framework
13/11/27 15:36:24 INFO mapred.JobClient:Map input records=2
13/11/27 15:36:24 INFO mapred.JobClient:Map output records=2
13/11/27 15:36:24 INFO mapred.JobClient:Input split bytes=143
13/11/27 15:36:24 INFO mapred.JobClient:Spilled Records=0
13/11/27 15:36:24 INFO mapred.JobClient:CPU time spent (ms)=820
13/11/27 15:36:24 INFO mapred.JobClient:Physical memory (bytes) snapshot=58933248
13/11/27 15:36:24 INFO mapred.JobClient:Virtual memory (bytes) snapshot=388550656
13/11/27 15:36:24 INFO mapred.JobClient:Total committed heap usage (bytes)=15990784
13/11/27 15:36:24 INFO mapreduce.ExportJobBase:Transferred 202 bytes in 10.349 seconds (19.5188 bytes/sec)
13/11/27 15:36:24 INFO mapreduce.ExportJobBase:Exported 2 records.
[wissem@localhost ~]$
现在结果已经成功导出,我们来检查 USER_STATS 表。
SQL> select * from USER_STATS;
ACTIVES IP_ADRR ACTIVE_DAT
---------- --------------------- ----------
4 65.245.153.105 2013-11-27
5 98.245.153.111 2013-11-27
总结:
在本文中,我们了解了 Oracle 数据库和 Hadoop(框架和生态系统)如何协同工作提供一个高效/最佳的企业架构来存储和处理大数据集。关于作者:
Wissem 是一位拥有逾 12 年经验的资深 Oracle DBA/架构师,专攻 Oracle RAC 和 Data Guard。他目前任职“Schneider Electric/APC 全球运营”。Wissem 是西班牙首位 Oracle ACE,他是 OCP/OCE DBA。您可以通过博客 www.oracle-class.com 或 twitter @orawiss 关注 Wissem
相关文章推荐
- 基于 Red Hat 的发行版 Oracle Linux 正式发布Oracle Linux 7.1
- Oracle Containers for J2EE远程安全漏洞(CVE-2014-0413)
- Oracle 10g R2不能使用EM的问题
- 表空间操作
- PreparedStatement中in子句的处理
- VMware下RedHat4.8_64位安装Oracle 10g RAC--简略脚本
- oracle sql日期比较
- 基于 Red Hat 的发行版 Oracle Linux 正式发布Oracle Linux 7.1
- OS block size和Oracle block size,查找OS Blocksize的方法
- oracle中创建数据库和表空间的几点总结
- 数据库自动备份脚本
- oracle的nvl函数的使用介绍
- 解决oracle用户连接失败的解决方法
- oracle的一些tips技巧
- Oracle 下的开发日积月累
- Oracle存储过程之数据库中获取数据实例
- Windows下ORACLE 10g完全卸载的方法分析
- Oracle 函数大全[字符串函数,数学函数,日期函数]第1/4页
- ORACLE LATERAL-SQL-INJECTION 个人见解