[置顶] 模式识别(Pattern Recognition)学习笔记(三十六)-- 动态聚类算法
2016-07-21 15:16
302 查看
如果不估计样本的概率分布,就无法从概率分布的角度来定义聚类,这时我们就需要有一种新的对聚类的定义,一般的,根据样本间的某种距离或某种相似性度量来定义聚类,即把相似的或距离近的样本聚为一类,而把不相似或距离远的样本聚在其他类,这种基于相似性度量的聚类方法在实际应用中非常常用,主要可以分为动态聚类法和分层聚类法,本篇博客我们主要来介绍常用动态聚类的方法。
动态聚类方法是一中普遍被采用的方法,具有以下三个要素:1)选定某种距离度量作为样本间的相似性度量;2)确定某种可以评价聚类结果质量的准则函数;3)给定某个初始分类,然后用迭代算法找出使得准则函数取极值的最好聚类结果。

的样本数目,样本均值为:

(1)
中各样本与均值间的误差平方和对所有类求和为:

(2)
为聚类结果的准则函数;对于不同的聚类,准则函数的值是不同的,但是能使其值极小的聚类才是误差平方和准则下的最优结果,这种类型的聚类通常被称为最小方差划分。
由于上述准则函数是样本集和聚类集合的函数,所以无法用解析的方法最小化,只能用迭代来解决,下面我们先来看看调整样本类别划分的方法。
假设已经有一个划分方案,它把样本y划分在

中,接下来假设对它做如下调整:
如果把样本y从聚类
中移到聚类

中,这时两个聚类的均值变为:


同时,对应的误差平方和也变为:


由于其他聚类都没有发生变化,所以总体误差平方和的变化仅仅取决于上述两个公式的变化。显然,移出一样本会导致类的平方误差减小,而移入会导致增大,如果减小量大于增加量,则当前进行的样本移动就有利于总体误差平方和的减少,于是就进行这一移动操作,否则的话不操作。

,利用公式(1)和(2)分别计算出各聚类的均值和误差平方和;
2)任意取出一个样本y,假设

;
3)如果样本数目
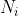
等于1,则跳至2),否则继续;
4)计算增加量和减小量:


j≠i;
5)考察增加量

中的最小量

,如果
<

,就把样本y从
移到
;
6)重新计算各聚类的均值和误差平方和;
7)在连续n次迭代后,如果总的误差平方和不再改变,就停止迭代,否则跳至2);
不难看出,这是一个局部搜索算法,并不能保证收敛到全局最优解,且算法的结果收初始划分和样本调整顺序的影响。
初始划分的方法有很多,一般的做法是,先选择一些代表样本点作为初始聚类的核心,然后根据距离把其余的样本划分到各初始类中,代表点的选取有以下常用方法:
1)经验:利用经验确定聚类数,从数据中找出从直观上看来是比较适合的代表点;
2)随机:将全部数据随机分成k类,计算每类的质心,将这些质心点作为每类的代表点;
3)按照样本的自然排列顺序或者将样本随机排序后用前k个数据点作为代表点;
4)先把全体样本看做是一个大的聚类,代表点为其均值,然后确定两个聚类问题的代表点,就是一聚类划分的总均值和离它最远的点,以此类推,得到k个聚类问题的代表点;
另外关于聚类数目k的确定,通常来说数目越多,误差越小,当每一个样本都自成一类时,误差等于0,当然这是现实情况中不会发生的,实际应用中可以根据具体应用领域比较聚类结果,来决定那个聚类数目比较合理。
总结:K-Means算法中,每调整一个样本,就要重新计算一次均值和误差,这种更改均值的方法属于逐个样本的修正;
算法的难点:聚类数目的动态决定,类的合并与分裂;

,设定以下参数:
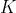
:期望得到的聚类数

:一个聚类中的最少样本数

:标准差参数

:合并参数
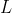
:每次迭代允许合并的最大聚类对数
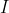
:最大迭代次数
1)初始化,设置初始聚类数c(不一定等于K),利用与K-Means相同的办法确定c个初始中心
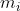
;
2)把所有样本分到距离初始中心最近的类

;
3)如果某个类
中样本数目过少,即

,则简介去掉该类:根据个样本到其他类中心的而距离分别合并入其他类,同时置c=c-1;
4)重新计算均值:

5)计算第j类样本与其中心的平均距离和总平均距离:


6)如果达到最大迭代次数,停止;否则:
若当前聚类数c≤K/2,分裂转7);
若当前聚类数c≥2K,或是偶数次迭代,合并转8);
7)聚类的分裂
a.对每各类,运用如下公式求出各维标准差

:

其中,

是第k个样本的第i个分量;

是当前第j个聚类中心的第i个分量;

是第j类第i个分量的标准差;d为样本维数;
b.对每个类,求出标准差最大的分量
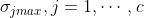
;
c.对各类的
,若存在某个类的

>
,

>

,且

,或c≤K/2,则将

分裂为两类,置c=c+1,分裂的两类中心分别为:


其中,分裂项可以为

,0<k≤1;也可以为

,即只在
对应的特征分量上把这一类分开。
8)聚类的合并
a.计算各类中心每两个之间的距离

;
b.比较
与
,对小于
者进行升序排列:

c.从最小的

开始,把每个

对应的

和

合并,组成新类,新的中心为:

,同时置c=c-1,注意每一次迭代中要避免同一类被合并两次;
9)若是最后一次迭代,终止;否则迭代次数加1,转2);
动态聚类方法是一中普遍被采用的方法,具有以下三个要素:1)选定某种距离度量作为样本间的相似性度量;2)确定某种可以评价聚类结果质量的准则函数;3)给定某个初始分类,然后用迭代算法找出使得准则函数取极值的最好聚类结果。
一 K-Means聚类算法
K-Means聚类又叫C均值聚类,其基本思想是,通过迭代找到k个聚类的一种划分方案,使得用这k个聚类的均值来表示相应各类样本时所得到的总体误差最小,所以K-Means是一种基于最小误差平方和准则的聚类算法。由于它在向量量化和图像分割上也有很广泛的应用,所以有时也被称为广义Glogd算法,简称GLA。1.主要原理
若Ni是第i个聚类的样本数目,样本均值为:
(1)
中各样本与均值间的误差平方和对所有类求和为:
(2)
为聚类结果的准则函数;对于不同的聚类,准则函数的值是不同的,但是能使其值极小的聚类才是误差平方和准则下的最优结果,这种类型的聚类通常被称为最小方差划分。
由于上述准则函数是样本集和聚类集合的函数,所以无法用解析的方法最小化,只能用迭代来解决,下面我们先来看看调整样本类别划分的方法。
假设已经有一个划分方案,它把样本y划分在
中,接下来假设对它做如下调整:
如果把样本y从聚类
中移到聚类
中,这时两个聚类的均值变为:
同时,对应的误差平方和也变为:
由于其他聚类都没有发生变化,所以总体误差平方和的变化仅仅取决于上述两个公式的变化。显然,移出一样本会导致类的平方误差减小,而移入会导致增大,如果减小量大于增加量,则当前进行的样本移动就有利于总体误差平方和的减少,于是就进行这一移动操作,否则的话不操作。
2.核心思想
1)初始划分k个聚类,利用公式(1)和(2)分别计算出各聚类的均值和误差平方和;
2)任意取出一个样本y,假设
;
3)如果样本数目
等于1,则跳至2),否则继续;
4)计算增加量和减小量:
j≠i;
5)考察增加量
中的最小量
,如果
<
,就把样本y从
移到
;
6)重新计算各聚类的均值和误差平方和;
7)在连续n次迭代后,如果总的误差平方和不再改变,就停止迭代,否则跳至2);
不难看出,这是一个局部搜索算法,并不能保证收敛到全局最优解,且算法的结果收初始划分和样本调整顺序的影响。
初始划分的方法有很多,一般的做法是,先选择一些代表样本点作为初始聚类的核心,然后根据距离把其余的样本划分到各初始类中,代表点的选取有以下常用方法:
1)经验:利用经验确定聚类数,从数据中找出从直观上看来是比较适合的代表点;
2)随机:将全部数据随机分成k类,计算每类的质心,将这些质心点作为每类的代表点;
3)按照样本的自然排列顺序或者将样本随机排序后用前k个数据点作为代表点;
4)先把全体样本看做是一个大的聚类,代表点为其均值,然后确定两个聚类问题的代表点,就是一聚类划分的总均值和离它最远的点,以此类推,得到k个聚类问题的代表点;
另外关于聚类数目k的确定,通常来说数目越多,误差越小,当每一个样本都自成一类时,误差等于0,当然这是现实情况中不会发生的,实际应用中可以根据具体应用领域比较聚类结果,来决定那个聚类数目比较合理。
总结:K-Means算法中,每调整一个样本,就要重新计算一次均值和误差,这种更改均值的方法属于逐个样本的修正;
算法的难点:聚类数目的动态决定,类的合并与分裂;
二 ISODATA算法
1.与K-Means算法的不同
ISODATA算法,叫做迭代自组织数据分析技术,可以看做是K-Means的一种改进,他们之间主要有两点不同:1)ISODATA算法不是每调整一个样本的类别就更新一次各类的均值,而是在把全部样本调整完后才更新计算各类的均值,相比于K-Means的逐个样本修正,这种均值的更新方法叫做成批样本修正,可以提高计算效率;2)ISODATA算法在聚类过程中引入了对类别的评判准则,可以根据这些准则自动的将某些类别合并或分裂,从而得到更合理的聚类结果,也在一定程度上打破了事先给定类别数目的限制。2.ISODATA算法的算法步骤
设有N个样本组成的样本集为,设定以下参数:
:期望得到的聚类数
:一个聚类中的最少样本数
:标准差参数
:合并参数
:每次迭代允许合并的最大聚类对数
:最大迭代次数
1)初始化,设置初始聚类数c(不一定等于K),利用与K-Means相同的办法确定c个初始中心
;
2)把所有样本分到距离初始中心最近的类
;
3)如果某个类
中样本数目过少,即
,则简介去掉该类:根据个样本到其他类中心的而距离分别合并入其他类,同时置c=c-1;
4)重新计算均值:
5)计算第j类样本与其中心的平均距离和总平均距离:
6)如果达到最大迭代次数,停止;否则:
若当前聚类数c≤K/2,分裂转7);
若当前聚类数c≥2K,或是偶数次迭代,合并转8);
7)聚类的分裂
a.对每各类,运用如下公式求出各维标准差
:
其中,
是第k个样本的第i个分量;
是当前第j个聚类中心的第i个分量;
是第j类第i个分量的标准差;d为样本维数;
b.对每个类,求出标准差最大的分量
;
c.对各类的
,若存在某个类的
>
,
>
,且
,或c≤K/2,则将
分裂为两类,置c=c+1,分裂的两类中心分别为:
其中,分裂项可以为
,0<k≤1;也可以为
,即只在
对应的特征分量上把这一类分开。
8)聚类的合并
a.计算各类中心每两个之间的距离
;
b.比较
与
,对小于
者进行升序排列:
c.从最小的
开始,把每个
对应的
和
合并,组成新类,新的中心为:
,同时置c=c-1,注意每一次迭代中要避免同一类被合并两次;
9)若是最后一次迭代,终止;否则迭代次数加1,转2);

相关文章推荐
- 定时任务基本概念
- 在线程中建立Form遇到的问题
- [Doc ID 1666646.1]如何使用功能管理员清除缓存?
- leetcode237
- 关于宏和函数、内联函数的一些区别
- 文件下载不能使用ajax的替代解决方案
- Jquery 事件冒泡的介绍以及如何阻止事件冒泡
- Android 让自定义TextView的drawableLeft与文本一起居中
- Spring Boot - 构建Spring Boot系统及相关配置详解
- 【理解JVM】 深入分析Java ClassLoader原理
- 筛法求素数
- 简述Java命令行参数、JVM、打包Java程序、JAR文件
- 我所理解的Cocos2d-x Cocos2d-x 内存管理机制
- js事件冒泡,元素中还有其他事件
- jstack对线程信息的分析
- mongoldb学习之初识mongoldb
- 别装了,你根本就不想变成更好的人
- js 把一个函数赋给一个变量时带括号与不带括号的区别
- A - Theatre Square
- mssql批量删除表