日志集中化管理系统ELK-logstash-grok详解
2016-07-20 15:08
666 查看
一般系统或服务生成的日志都是一大长串。每个字段之间用空格隔开。logstash在获取日志是整个一串获取,如果能日志中每个字段代表的意思分割开来在传给elasticsearch。这样呈现出来的效果将会更加好,而且也能让kibana更方便的绘制图形。
Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。
grok表达式
下面针对Apache日志来分割处理
如:%{IPORHOST:addre} ==> 192.168.10.197
但问题是IPORHOST又不是正则表达式,怎么能匹配IP地址呢?
那是因为IPPRHOST是grok表达式,它代表的正则表达式如下:
IPORHOST代表的是ipv4或者ipv6或者HOSTNAME所匹配的grok表达式。
上面的IPORHOST有点复杂,我们来看看简单点的,如USER
USERNAME [a-zA-Z0-9._-]+
USER %{USERNAME}
第一行,用普通的正则表达式来定义一个 grok 表达式;第二行,通过打印赋值格式,用前面定义好的 grok 表达式来定义另一个 grok 表达式。
下面我们先来介绍下grok的语法:%{SYNTAX:SEMANTIC}
SYNTAX代表的是正则表达式替代字段,SEMANTIC是代表这个表达式对应的字段名,你可以自由命名。这个命名尽量能简单易懂的表达出这个字段代表的意思。
那如IPORHOST在哪里已经定义好了,有哪些我们可以直接使用的呢?
logstash安装时就带有已经写好的正则表达式。路径如下:
/usr/local/logstash-2.3.4/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-2.0.5/patterns
或者直接访问https://github.com/elastic/logstash/blob/v1.4.2/patterns/grok-patterns
上面IPORHOST,USER等都是在里面已经定义好的!当然还有其他的,基本能满足我们的需求。
日志匹配
当我们拿到一段日志,按照上面的grok表达式一个个去匹配时,我们如何确实我们匹配的是否正确呢?
http://grokdebug.herokuapp.com/ 这个地址可以满足我们的测试需求。就拿上面apache的日志测试。
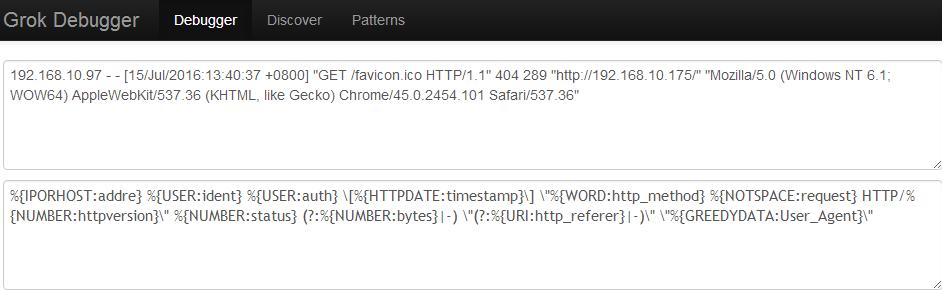
点击后就出现如下数据,你写的每个grok表达式都获取到值了。为了测试准确,可以多测试几条日志。
如:(?:%{NUMBER:bytes}|-)
但是有些字符串是在太长,如:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36
我们可以使用%{GREEDYDATA browser}.
对应的grok表达式: GREEDYDATA .*
自定义grok表达式
如果你感觉logstash自带的grok表达式不能满足需要,你也可以自己定义
如:
自定义的patterns中按照logstash自带的格式书写。
如果你把 "message" 里所有的信息都 grok 到不同的字段了,数据实质上就相当于是重复存储了两份。所以你可以用
本文出自 “宁静致远” 博客,请务必保留此出处http://irow10.blog.51cto.com/2425361/1828077
Grok 是 Logstash 最重要的插件。它的主要作用就是将文本格式的字符串,转换成为具体的结构化的数据,配合正则表达式使用。
grok表达式
下面针对Apache日志来分割处理
filter {
if [type] == "apache" {
grok {
match => ["message" => "%{IPORHOST:addre} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:http_method} %{NOTSPACE:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:status} (?:%{NUMBER:bytes}|-) \"(?:%{URI:http_referer}|-)\" \"%{GREEDYDATA:User_Agent}\""]
remove_field => ["message"]
}
date {
match => [ "timestamp", "dd/MMM/YYYY:HH:mm:ss Z" ]
}
}
}下面是apache日志192.168.10.97 - - [19/Jul/2016:16:28:52 +0800] "GET / HTTP/1.1" 200 23 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"日志中每个字段之间空格隔开,分别一一对应message中的字段。
如:%{IPORHOST:addre} ==> 192.168.10.197
但问题是IPORHOST又不是正则表达式,怎么能匹配IP地址呢?
那是因为IPPRHOST是grok表达式,它代表的正则表达式如下:
IPV6 ((([0-9A-Fa-f]{1,4}:){7}([0-9A-Fa-f]{1,4}|:))|(([0-9A-Fa-f]{1,4}:){6}(:[0-9A-Fa-f]{1,4}|((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){5}(((:[0-9A-Fa-f]{1,4}){1,2})|:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){4}(((:[0-9A-Fa-f]{1,4}){1,3})|((:[0-9A-Fa-f]{1,4})?:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){3}(((:[0-9A-Fa-f]{1,4}){1,4})|((:[0-9A-Fa-f]{1,4}){0,2}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){2}(((:[0-9A-Fa-f]{1,4}){1,5})|((:[0-9A-Fa-f]{1,4}){0,3}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){1}(((:[0-9A-Fa-f]{1,4}){1,6})|((:[0-9A-Fa-f]{1,4}){0,4}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(:(((:[0-9A-Fa-f]{1,4}){1,7})|((:[0-9A-Fa-f]{1,4}){0,5}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:)))(%.+)?
IPV4 (?<![0-9])(?:(?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5])[.](?:[0-1]?[0-9]{1,2}|2[0-4][0-9]|25[0-5]))(?![0-9])
IP (?:%{IPV6}|%{IPV4})
HOSTNAME \b(?:[0-9A-Za-z][0-9A-Za-z-]{0,62})(?:\.(?:[0-9A-Za-z][0-9A-Za-z-]{0,62}))*(\.?|\b)
IPORHOST (?:%{IP}|%{HOSTNAME})IPORHOST代表的是ipv4或者ipv6或者HOSTNAME所匹配的grok表达式。
上面的IPORHOST有点复杂,我们来看看简单点的,如USER
USERNAME [a-zA-Z0-9._-]+
USER %{USERNAME}
第一行,用普通的正则表达式来定义一个 grok 表达式;第二行,通过打印赋值格式,用前面定义好的 grok 表达式来定义另一个 grok 表达式。
下面我们先来介绍下grok的语法:%{SYNTAX:SEMANTIC}
SYNTAX代表的是正则表达式替代字段,SEMANTIC是代表这个表达式对应的字段名,你可以自由命名。这个命名尽量能简单易懂的表达出这个字段代表的意思。
那如IPORHOST在哪里已经定义好了,有哪些我们可以直接使用的呢?
logstash安装时就带有已经写好的正则表达式。路径如下:
/usr/local/logstash-2.3.4/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-2.0.5/patterns
或者直接访问https://github.com/elastic/logstash/blob/v1.4.2/patterns/grok-patterns
上面IPORHOST,USER等都是在里面已经定义好的!当然还有其他的,基本能满足我们的需求。
日志匹配
当我们拿到一段日志,按照上面的grok表达式一个个去匹配时,我们如何确实我们匹配的是否正确呢?
http://grokdebug.herokuapp.com/ 这个地址可以满足我们的测试需求。就拿上面apache的日志测试。
点击后就出现如下数据,你写的每个grok表达式都获取到值了。为了测试准确,可以多测试几条日志。
{
"addre": [
[
"192.168.10.97"
]
],
"HOSTNAME": [
[
"192.168.10.97",
"192.168.10.175"
]
...........中间省略多行...........
"http_referer": [
[
"http://192.168.10.175/"
]
],
"URIPROTO": [
[
"http"
]
],
"URIHOST": [
[
"192.168.10.175"
]
],
"IPORHOST": [
[
"192.168.10.175"
]
],
"User_Agent": [
[
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36"
]
]
}每条日志总有些字段是没有数据显示,然后以“-”代替的。所有我们在匹配日志的时候也要判断。如:(?:%{NUMBER:bytes}|-)
但是有些字符串是在太长,如:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36
我们可以使用%{GREEDYDATA browser}.
对应的grok表达式: GREEDYDATA .*
自定义grok表达式
如果你感觉logstash自带的grok表达式不能满足需要,你也可以自己定义
如:
filter {
if [type] == "apache" {
grok {
patterns_dir => "/usr/local/logstash-2.3.4/ownpatterns/patterns"
match => {
"message" => "%{APACHE_LOG}"
}
remove_field => ["message"]
}
date {
match => [ "timestamp", "dd/MMM/YYYY:HH:mm:ss Z" ]
}
}
}patterns_dir为只定义的grok表达式的路径。自定义的patterns中按照logstash自带的格式书写。
APACHE_LOG %{IPORHOST:addre} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:http_method} %{NOTSPACE:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:status} (?:%{NUMBER:bytes}|-) \"(?:%{URI:http_referer}|-)\" \"%{GREEDYDATA:User_Agent}\"我只是把apache日志匹配的grok表达式写入自定义文件中,简化conf文件。单个字段的正则表达式匹配你可以自己书写测试。如果你把 "message" 里所有的信息都 grok 到不同的字段了,数据实质上就相当于是重复存储了两份。所以你可以用
remove_field参数来删除掉 message 字段,或者用
overwrite参数来重写默认的 message字段,只保留最重要的部分。
本文出自 “宁静致远” 博客,请务必保留此出处http://irow10.blog.51cto.com/2425361/1828077

相关文章推荐
- 近期项目笔记整理(三)
- CentOS 6.3下配置LVM(逻辑卷管理)
- angularJs中将字符串转换为HTML格式
- nginx,php相关
- c语言链表初始化
- 开发时调试方式与配置要相同
- hdoj 2098 分拆素数和
- 欢迎使用CSDN-markdown编辑器
- 《JAVA与模式》之单例模式
- uc/os-iii学习笔记-消息传递
- PCDATA和CDATA区别
- oracle sql语言模糊查询--通配符like的使用
- nubbi模型的启发
- Mysql数据库分布式事务XA详解
- 监听EditText内容变化及字数限制
- UI阅读笔记
- Cassandra简介
- mysql 优化
- Ubuntu中安装eclipse ,双击eclipse出现invalid configuration location问题
- Go 辅助工具